Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben az oktatóanyagban megtudhatja, hogyan elemezhet strukturálatlan szövegeket a Text Analytics használatával az Azure Synapse Analyticsben. A Text Analytics egy Azure AI-szolgáltatás , amely lehetővé teszi a szövegbányászatot és a szövegelemzést természetes nyelvi feldolgozási (NLP) funkciókkal.
Ez az oktatóanyag bemutatja, hogy a Text Analytics és a SynapseML a következő célokra használható:
- Hangulatfeliratok észlelése mondat- vagy dokumentumszinten
- Adott szövegbevitel nyelvének azonosítása
- Entitások felismerése egy jól ismert tudásbázis
- Kulcskifejezések kinyerése szövegből
- A szöveg különböző entitásainak azonosítása és kategorizálása előre definiált osztályokba vagy típusokba
- Bizalmas entitások azonosítása és ismételt kiírása egy adott szövegben
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot.
Előfeltételek
- Azure Synapse Analytics-munkaterület alapértelmezett tárolóként konfigurált Azure Data Lake Storage Gen2-tárfiókkal. A Data Lake Storage Gen2 fájlrendszer tárolási blobadat-közreműködőjének kell lennie.
- Spark-készlet az Azure Synapse Analytics-munkaterületen. További információ: Spark-készlet létrehozása az Azure Synapse-ban.
- Az oktatóanyagban ismertetett előzetes konfigurációs lépések Az Azure AI-szolgáltatások konfigurálása az Azure Synapse-ban.
Első lépések
Nyissa meg a Synapse Studiót, és hozzon létre egy új jegyzetfüzetet. Első lépésként importálja a SynapseML-t.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Szövegelemzés konfigurálása
Használja az előre konfigurálási lépésekben konfigurált csatolt szövegelemzést.
linked_service_name = "<Your linked service for text analytics>"
Szöveg hangulata
A szöveges hangulatelemzés lehetővé teszi a hangulatcímkék (például a "negatív", a "semleges" és a "pozitív") és a megbízhatósági pontszámok észlelését a mondat- és dokumentumszinten. Az engedélyezett nyelvek listáját a Text Analytics API támogatott nyelvei között találja.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Várt eredmények
| text | Hangulat |
|---|---|
| Olyan boldog vagyok ma, hogy napsütés van! | pozitív |
| Frusztrált ez a csúcsforgalom | negatív |
| Az Azure AI-szolgáltatások a Sparkon nem megfelelőek | semleges |
Nyelvi detektor
A Language Detector kiértékeli az egyes dokumentumok szövegbevitelét, és olyan pontszámmal adja vissza a nyelvi azonosítókat, amelyek az elemzés erősségét jelzik. Ez a funkció véletlen szöveget gyűjtő tartalom áruházak számára hasznos, amikor a nyelv ismeretlen. Az engedélyezett nyelvek listáját a Text Analytics API támogatott nyelvei között találja.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Várt eredmények
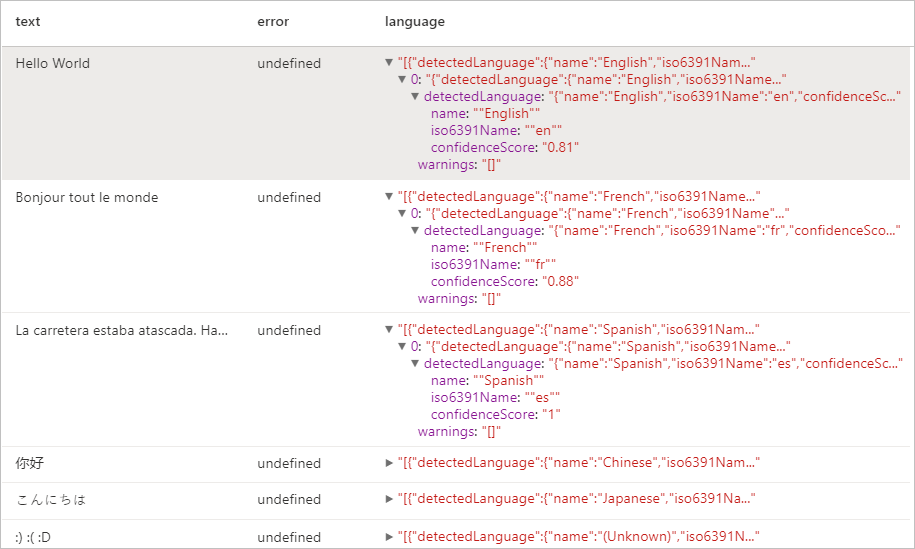
Entitásérzékelő
Az Entitásérzékelő egy jól ismert tudásbázis mutató hivatkozásokkal rendelkező felismert entitások listáját adja vissza. Az engedélyezett nyelvek listáját a Text Analytics API támogatott nyelvei között találja.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Várt eredmények
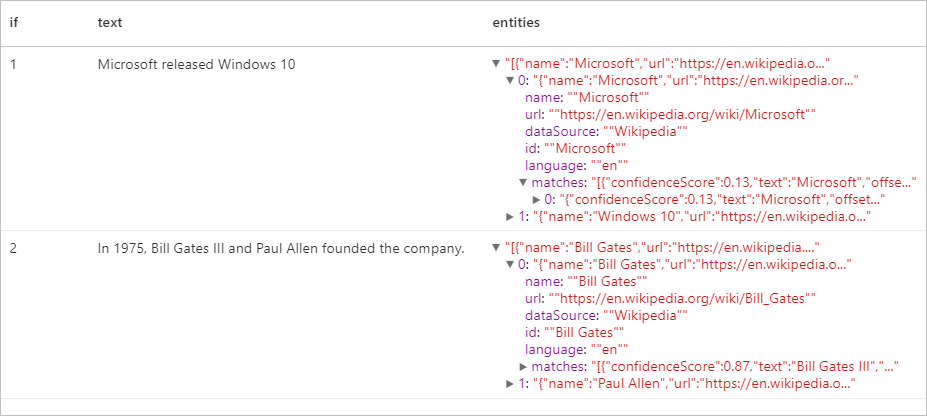
Kulcskifejezés-kinyerő
A kulcskifejezések kinyerése strukturálatlan szöveget értékel ki, és visszaadja a kulcskifejezések listáját. Ez a funkció akkor hasznos, ha szeretné gyorsan azonosítani a dokumentum gyűjtemény fő témáit. Az engedélyezett nyelvek listáját a Text Analytics API támogatott nyelvei között találja.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Várt eredmények
| text | keyPhrases |
|---|---|
| Helló világ. Ez egy szövegbeviteli szöveg, amit szeretek. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Nevesített entitások felismerése (NER)
A nevesített entitásfelismerés (NER) lehetővé teszi a szöveg különböző entitásainak azonosítását, és előre meghatározott osztályokba vagy típusokba kategorizálhatja őket, például: személy, hely, esemény, termék és szervezet. Az engedélyezett nyelvek listáját a Text Analytics API támogatott nyelvei között találja.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Várt eredmények
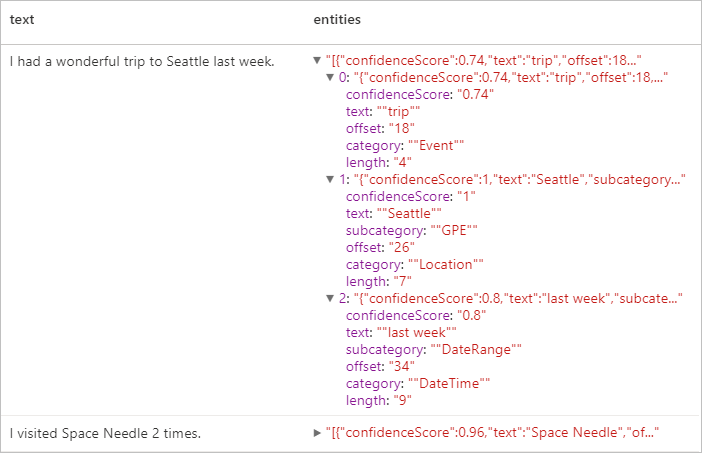
Személyazonosításra alkalmas adatok (PII) V3.1
A PII szolgáltatás a NER része, és képes azonosítani és újra kiírni azokat a bizalmas entitásokat, amelyek egy adott személyhez vannak társítva, például: telefonszám, e-mail-cím, levelezési cím, útlevélszám. Az engedélyezett nyelvek listáját a Text Analytics API támogatott nyelvei között találja.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Várt eredmények
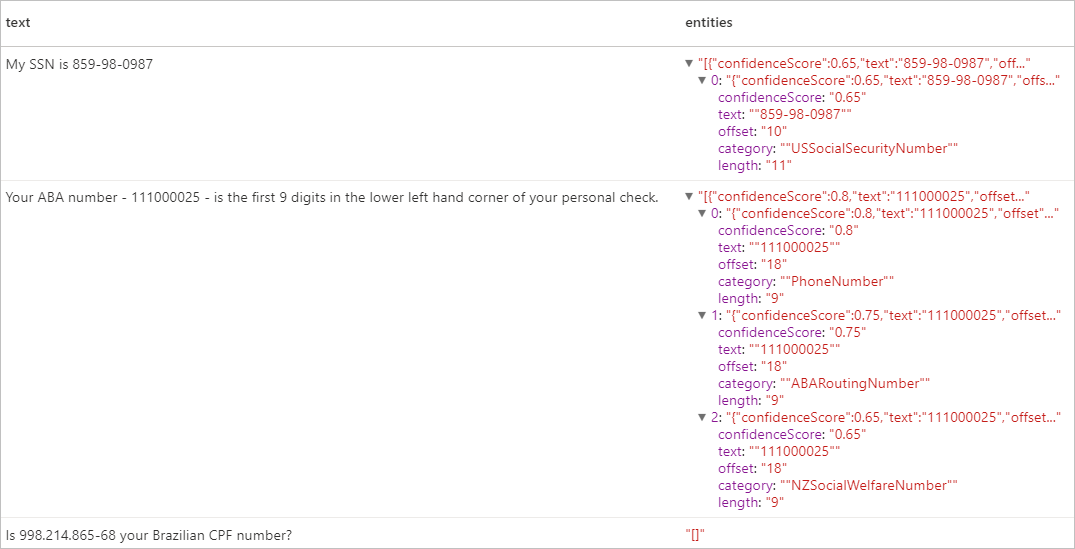
Az erőforrások eltávolítása
A Spark-példány leállítása érdekében zárja be a csatlakoztatott munkameneteket (jegyzetfüzeteket). A készlet leáll az Apache Spark-készletben megadott tétlenségi idő elérésekor. A leállítási munkamenetet a jegyzetfüzet jobb felső sarkában található állapotsoron is kiválaszthatja.
