Oktatóanyag: Apache Spark-feladatdefiníció létrehozása a Synapse Studióban
Ez az oktatóanyag bemutatja, hogyan hozhat létre Apache Spark-feladatdefiníciókat a Synapse Studióval, majd hogyan küldheti el őket egy kiszolgáló nélküli Apache Spark-készletbe.
Ez az oktatóanyag a következő feladatokat mutatja be:
- Apache Spark-feladatdefiníció létrehozása a PySparkhoz (Python)
- Apache Spark-feladatdefiníció létrehozása a Sparkhoz (Scala)
- Apache Spark-feladatdefiníció létrehozása a .NET Sparkhoz (C#/F#)
- Feladatdefiníció létrehozása JSON-fájl importálásával
- Apache Spark-feladatdefiníciós fájl exportálása helyire
- Apache Spark-feladatdefiníció elküldése kötegelt feladatként
- Apache Spark-feladatdefiníció hozzáadása a folyamathoz
Előfeltételek
Mielőtt nekilát az oktatóanyagnak, ellenőrizze, hogy megfelel-e a következő feltételeknek:
- Azure Synapse Analytics-munkaterület. Útmutatásért lásd : Azure Synapse Analytics-munkaterület létrehozása.
- Kiszolgáló nélküli Apache Spark-készlet.
- Egy ADLS Gen2-tárfiók. A használni kívánt ADLS Gen2 fájlrendszer tárolási blobadat-közreműködőjének kell lennie. Ha nem, manuálisan kell hozzáadnia az engedélyt.
- Ha nem szeretné használni a munkaterület alapértelmezett tárterületét, kapcsolja össze a szükséges ADLS Gen2 tárfiókot a Synapse Studióban.
Apache Spark-feladatdefiníció létrehozása a PySparkhoz (Python)
Ebben a szakaszban egy Apache Spark-feladatdefiníciót hoz létre a PySparkhoz (Python).
Nyissa meg a Synapse Studiót.
Az Apache Spark-feladatdefiníciók létrehozására szolgáló mintafájlok között letöltheti python.zip mintafájljait, majd kibonthatja a tömörített csomagot, és kinyerheti a wordcount.py és shakespeare.txt fájlokat.
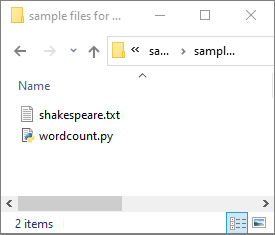
Válassza a Data -Linked ->>Azure Data Lake Storage Gen2 lehetőséget, és töltse fel wordcount.py és shakespeare.txt az ADLS Gen2 fájlrendszerbe.
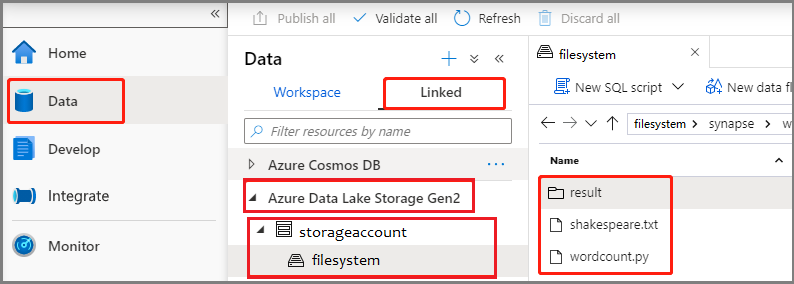
Válassza a Fejlesztési központ lehetőséget, válassza a "+" ikont, és válassza a Spark-feladatdefiníciót egy új Spark-feladatdefiníció létrehozásához.
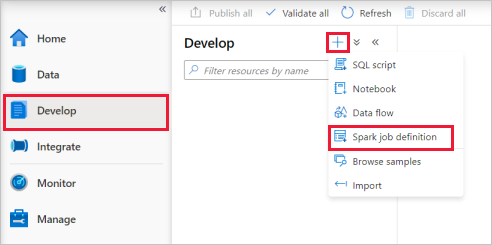
Válassza ki a PySparkot (Python) az Apache Spark-feladatdefiníció főablakának Nyelv legördülő listájából.
Töltse ki az Apache Spark-feladatdefiníció adatait.
Tulajdonság Leírás Feladatdefiníció neve Adja meg az Apache Spark-feladatdefiníció nevét. Ez a név bármikor frissíthető a közzétételig.
Minta:job definition sampleFő definíciós fájl A feladathoz használt fő fájl. Válasszon ki egy PY-fájlt a tárolóból. A Fájl feltöltése lehetőséget választva feltöltheti a fájlt egy tárfiókba.
Minta:abfss://…/path/to/wordcount.pyParancssori argumentumok A feladat nem kötelező argumentumai.
Minta:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Megjegyzés: A mintafeladat-definíció két argumentumát szóköz választja el egymástól.Referenciafájlok A fő definíciós fájlban hivatkozásra használt további fájlok. A Fájl feltöltése lehetőséget választva feltöltheti a fájlt egy tárfiókba. Spark-készlet A feladat a kiválasztott Apache Spark-készletbe lesz elküldve. Szikra változat Az Apache Spark azon verziója, amelyen az Apache Spark-készlet fut. Végrehajtók A feladathoz megadott Apache Spark-készletben megadható végrehajtók száma. Végrehajtó mérete A feladathoz megadott Apache Spark-készletben megadott végrehajtókhoz használandó magok és memória száma. Illesztőprogram mérete A feladathoz megadott Apache Spark-készletben megadott illesztőprogramhoz használandó magok és memória száma. Apache Spark-konfiguráció A konfigurációk testreszabása az alábbi tulajdonságok hozzáadásával. Ha nem ad hozzá tulajdonságot, az Azure Synapse szükség esetén az alapértelmezett értéket fogja használni. 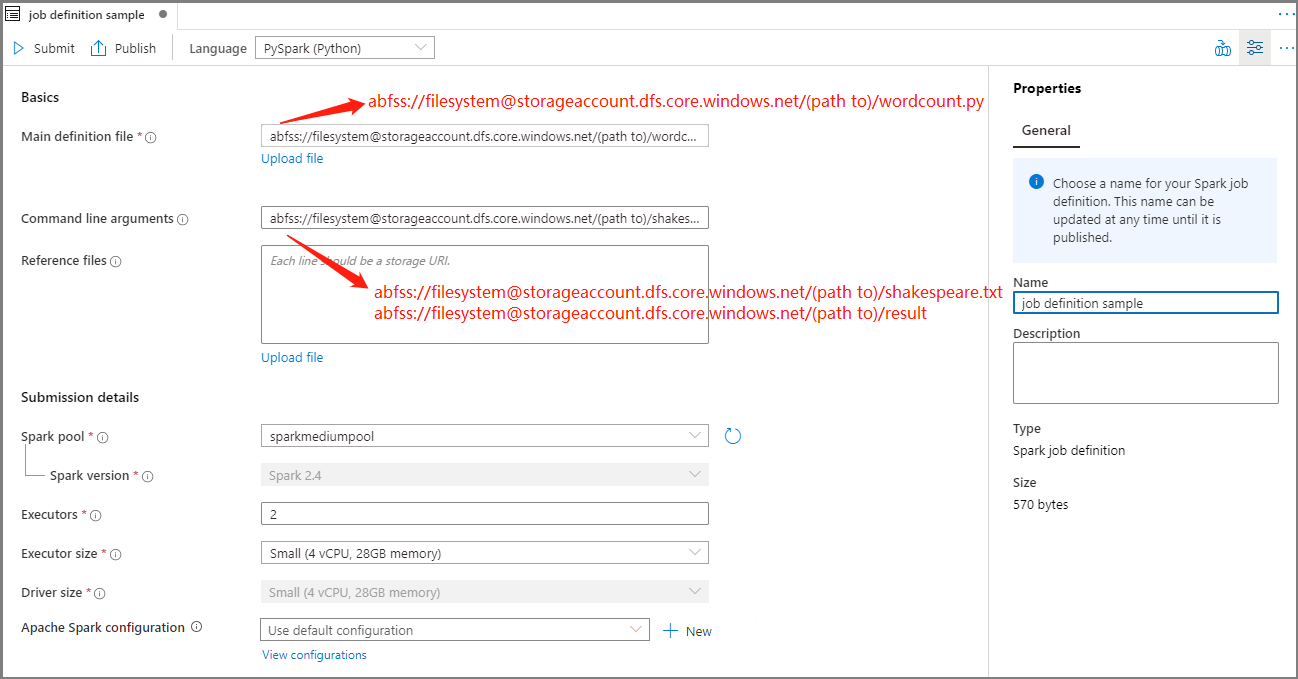
Válassza a Közzététel lehetőséget az Apache Spark-feladatdefiníció mentéséhez.

Apache Spark-feladatdefiníció létrehozása az Apache Sparkhoz (Scala)
Ebben a szakaszban egy Apache Spark-feladatdefiníciót hoz létre az Apache Sparkhoz (Scala).
Nyissa meg az Azure Synapse Studiót.
Az Apache Spark-feladatdefiníciók létrehozásához megnyithatja a mintafájlokat a scala.zip mintafájljainak letöltéséhez, majd kibonthatja a tömörített csomagot, és kinyerheti a wordcount.jar és shakespeare.txt fájlokat.
Válassza a Data -Linked ->>Azure Data Lake Storage Gen2 lehetőséget, és töltse fel wordcount.jar és shakespeare.txt az ADLS Gen2 fájlrendszerbe.
Válassza a Fejlesztési központ lehetőséget, válassza a "+" ikont, és válassza a Spark-feladatdefiníciót egy új Spark-feladatdefiníció létrehozásához. (A mintakép megegyezik a következő 4. lépésével: Apache Spark-feladatdefiníció (Python) létrehozása a PySparkhoz.)
Válassza a Spark(Scala) elemet az Apache Spark-feladatdefiníció főablakának Nyelv legördülő listájából.
Töltse ki az Apache Spark-feladatdefiníció adatait. A mintainformációkat átmásolhatja.
Tulajdonság Leírás Feladatdefiníció neve Adja meg az Apache Spark-feladatdefiníció nevét. Ez a név bármikor frissíthető a közzétételig.
Minta:scalaFő definíciós fájl A feladathoz használt fő fájl. Válasszon ki egy JAR-fájlt a tárolóból. A Fájl feltöltése lehetőséget választva feltöltheti a fájlt egy tárfiókba.
Minta:abfss://…/path/to/wordcount.jarFőosztály neve A teljes azonosító vagy a fő definíciós fájlban található főosztály.
Minta:WordCountParancssori argumentumok A feladat nem kötelező argumentumai.
Minta:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Megjegyzés: A mintafeladat-definíció két argumentumát szóköz választja el egymástól.Referenciafájlok A fő definíciós fájlban hivatkozásra használt további fájlok. A Fájl feltöltése lehetőséget választva feltöltheti a fájlt egy tárfiókba. Spark-készlet A feladat a kiválasztott Apache Spark-készletbe lesz elküldve. Szikra változat Az Apache Spark azon verziója, amelyen az Apache Spark-készlet fut. Végrehajtók A feladathoz megadott Apache Spark-készletben megadható végrehajtók száma. Végrehajtó mérete A feladathoz megadott Apache Spark-készletben megadott végrehajtókhoz használandó magok és memória száma. Illesztőprogram mérete A feladathoz megadott Apache Spark-készletben megadott illesztőprogramhoz használandó magok és memória száma. Apache Spark-konfiguráció A konfigurációk testreszabása az alábbi tulajdonságok hozzáadásával. Ha nem ad hozzá tulajdonságot, az Azure Synapse szükség esetén az alapértelmezett értéket fogja használni. 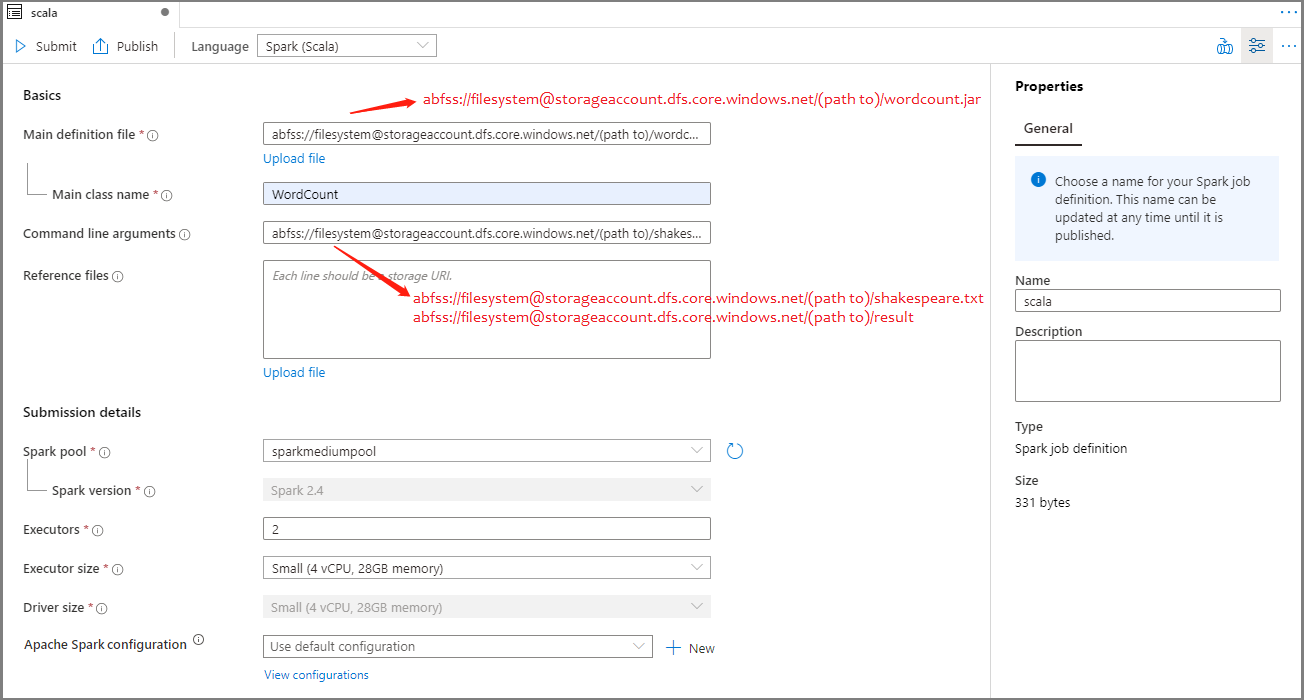
Válassza a Közzététel lehetőséget az Apache Spark-feladatdefiníció mentéséhez.

Apache Spark-feladatdefiníció létrehozása a .NET Sparkhoz (C#/F#)
Ebben a szakaszban egy Apache Spark-feladatdefiníciót hoz létre a .NET Spark(C#/F#) számára.
Nyissa meg az Azure Synapse Studiót.
Az Apache Spark-feladatdefiníciók létrehozásához megnyithatja a mintafájlokat a dotnet.zip mintafájljainak letöltéséhez, majd kibonthatja a tömörített csomagot, és kinyerheti a wordcount.zip és shakespeare.txt fájlokat.
Válassza a Data -Linked ->>Azure Data Lake Storage Gen2 lehetőséget, és töltse fel wordcount.zip és shakespeare.txt az ADLS Gen2 fájlrendszerbe.
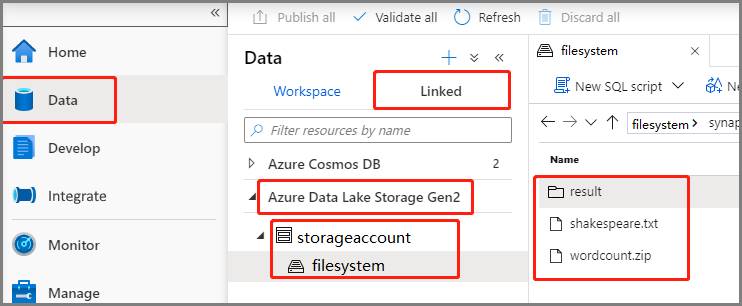
Válassza a Fejlesztési központ lehetőséget, válassza a "+" ikont, és válassza a Spark-feladatdefiníciót egy új Spark-feladatdefiníció létrehozásához. (A mintakép megegyezik a következő 4. lépésével: Apache Spark-feladatdefiníció (Python) létrehozása a PySparkhoz.)
Válassza a .NET Spark(C#/F#) lehetőséget az Apache Spark feladatdefiníció főablakának Nyelv legördülő listájából.
Töltse ki az Apache Spark-feladatdefinícióval kapcsolatos információkat. A mintainformációkat átmásolhatja.
Tulajdonság Leírás Feladatdefiníció neve Adja meg az Apache Spark-feladatdefiníció nevét. Ez a név bármikor frissíthető a közzétételig.
Minta:dotnetFő definíciós fájl A feladathoz használt fő fájl. Válasszon ki egy zip-fájlt, amely tartalmazza az Apache Spark-alkalmazáshoz készült .NET-et (azaz a fő végrehajtható fájlt, a felhasználó által definiált függvényeket tartalmazó DLL-eket és egyéb szükséges fájlokat) a tárolóból. A Fájl feltöltése lehetőséget választva feltöltheti a fájlt egy tárfiókba.
Minta:abfss://…/path/to/wordcount.zipFő végrehajtható fájl A fő végrehajtható fájl a fő definíciós ZIP-fájlban.
Minta:WordCountParancssori argumentumok A feladat nem kötelező argumentumai.
Minta:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Megjegyzés: A mintafeladat-definíció két argumentumát szóköz választja el egymástól.Referenciafájlok A feldolgozó csomópontok további fájlokat igényelnek az Apache Spark-alkalmazás .NET-hez való végrehajtásához, amelyek nem szerepelnek a fődefiníciós ZIP-fájlban (azaz függő jarok, további felhasználó által definiált függvény DLL-jei és egyéb konfigurációs fájlok). A Fájl feltöltése lehetőséget választva feltöltheti a fájlt egy tárfiókba. Spark-készlet A feladat a kiválasztott Apache Spark-készletbe lesz elküldve. Szikra változat Az Apache Spark azon verziója, amelyen az Apache Spark-készlet fut. Végrehajtók A feladathoz megadott Apache Spark-készletben megadható végrehajtók száma. Végrehajtó mérete A feladathoz megadott Apache Spark-készletben megadott végrehajtókhoz használandó magok és memória száma. Illesztőprogram mérete A feladathoz megadott Apache Spark-készletben megadott illesztőprogramhoz használandó magok és memória száma. Apache Spark-konfiguráció A konfigurációk testreszabása az alábbi tulajdonságok hozzáadásával. Ha nem ad hozzá tulajdonságot, az Azure Synapse szükség esetén az alapértelmezett értéket fogja használni. 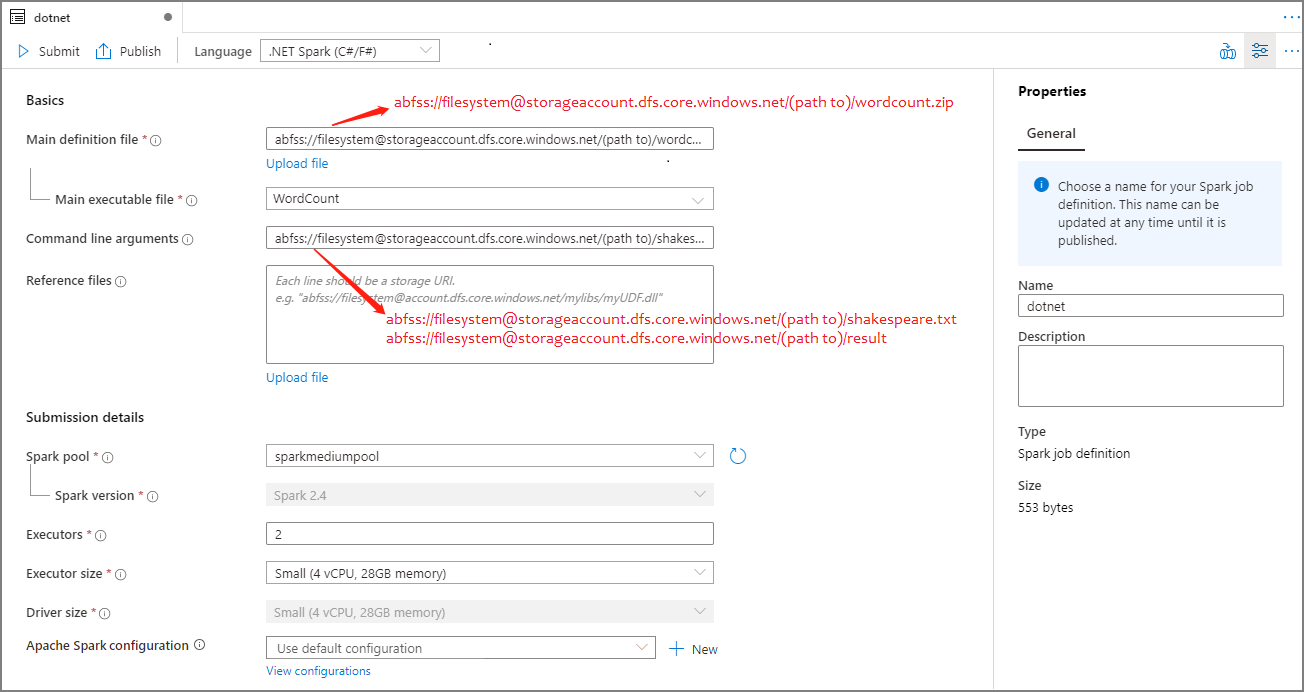
Válassza a Közzététel lehetőséget az Apache Spark-feladatdefiníció mentéséhez.

Feljegyzés
Az Apache Spark-konfiguráció esetében, ha az Apache Spark-konfiguráció Apache Spark-feladatdefiníciója nem végez különleges műveletet, a feladat futtatásakor az alapértelmezett konfiguráció lesz használva.
Apache Spark-feladatdefiníció létrehozása JSON-fájl importálásával
Egy meglévő helyi JSON-fájlt importálhat az Azure Synapse-munkaterületre az Apache Spark-feladatdefiníció-kezelő Műveletek (...) menüjéből egy új Apache Spark-feladatdefiníció létrehozásához.
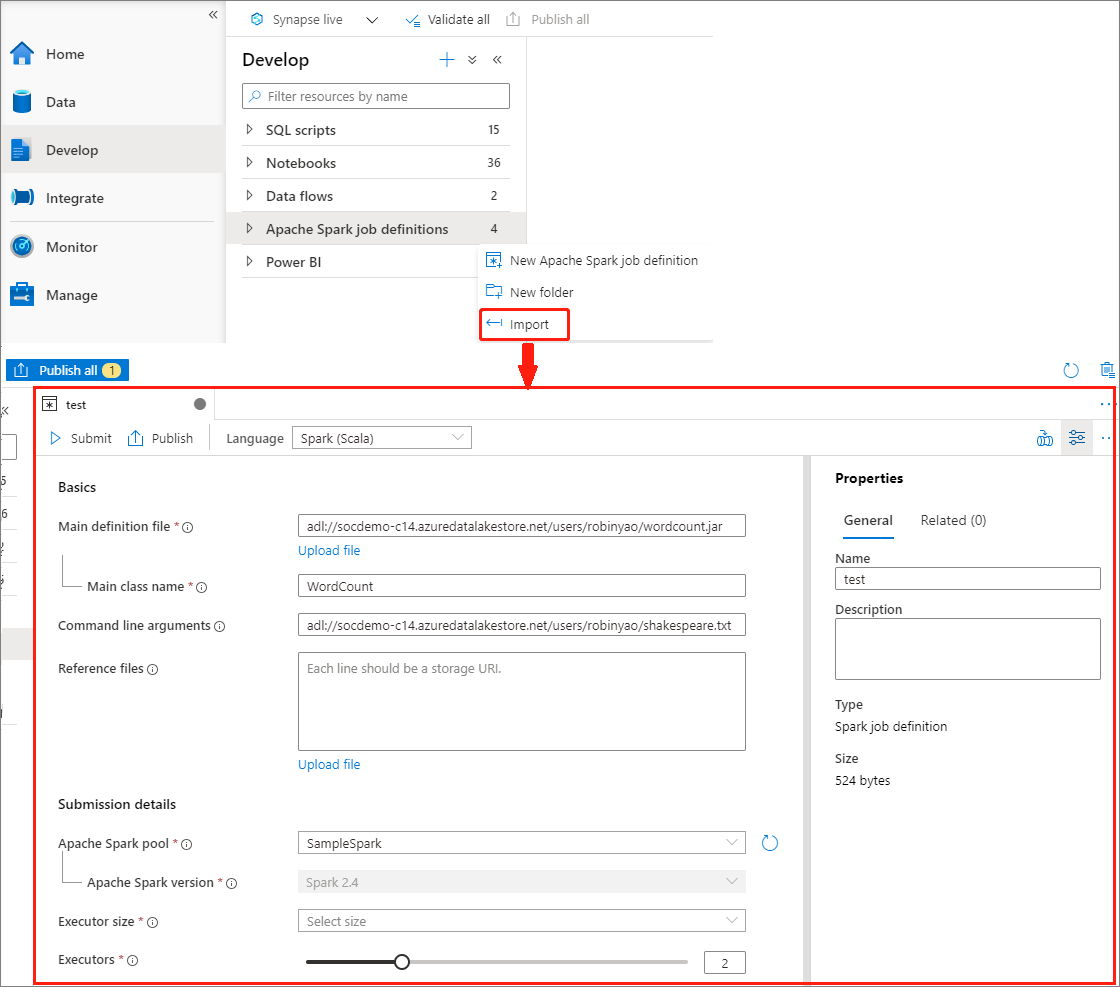
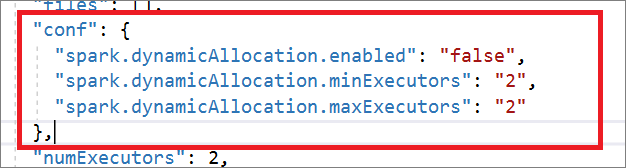
A Spark-feladatdefiníció teljes mértékben kompatibilis a Livy API-val. A helyi JSON-fájlban további paramétereket is hozzáadhat más Livy-tulajdonságokhoz (Livy Docs – REST API (apache.org). A Spark konfigurációval kapcsolatos paramétereit is megadhatja a konfigurációs tulajdonságban az alább látható módon. Ezután importálhatja a JSON-fájlt, hogy létrehozzon egy új Apache Spark-feladatdefiníciót a kötegelt feladathoz. Példa JSON értékre a Spark-definíció importálásához:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
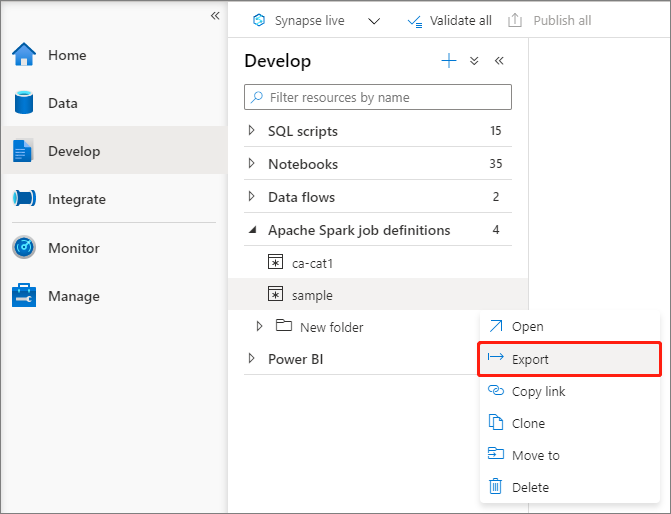
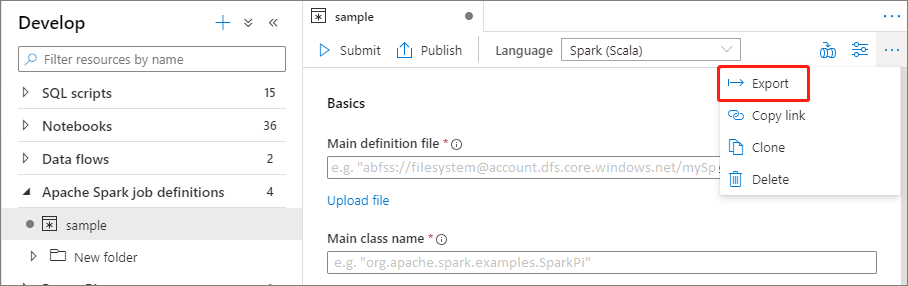
Meglévő Apache Spark-feladatdefiníciós fájl exportálása
A meglévő Apache Spark-feladatdefiníciós fájlokat exportálhatja a helyi fájlba a Fájlkezelő Műveletek (...) menüjéből. A JSON-fájlt további Livy-tulajdonságokhoz is frissítheti, és szükség esetén újra importálhatja, hogy új feladatdefiníciót hozzon létre.
Apache Spark-feladatdefiníció elküldése kötegelt feladatként
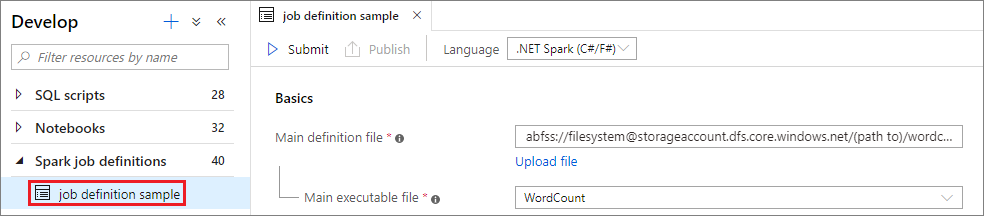
Az Apache Spark-feladatdefiníció létrehozása után elküldheti azt egy Apache Spark-készletbe. Győződjön meg arról, hogy Ön a használni kívánt ADLS Gen2 fájlrendszer tárolási blobadat-közreműködője . Ha nem, manuálisan kell hozzáadnia az engedélyt.
1. forgatókönyv: Apache Spark-feladatdefiníció elküldése
Nyisson meg egy Apache Spark-feladatdefiníciós ablakot a kijelölésével.
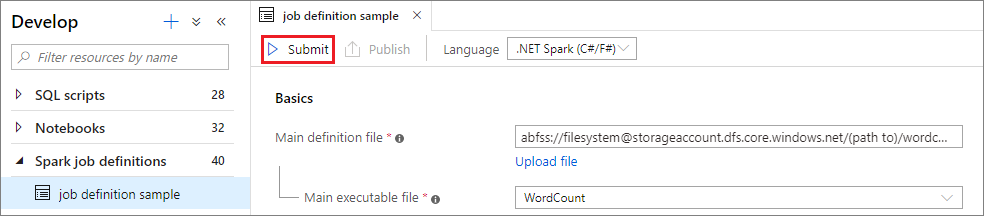
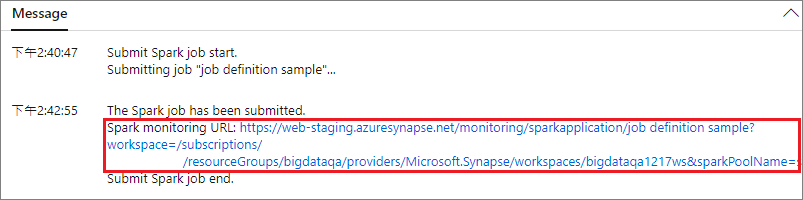
A Küldés gombra kattintva elküldheti a projektet a kiválasztott Apache Spark-készletbe. Az Apache Spark-alkalmazás LogQuery-jének megtekintéséhez válassza a Spark monitorozási URL-címét .
2. forgatókönyv: Az Apache Spark-feladat futási folyamatának megtekintése
Válassza a Monitorozás, majd az Apache Spark-alkalmazások lehetőséget. Megtalálhatja a beküldött Apache Spark-alkalmazást.
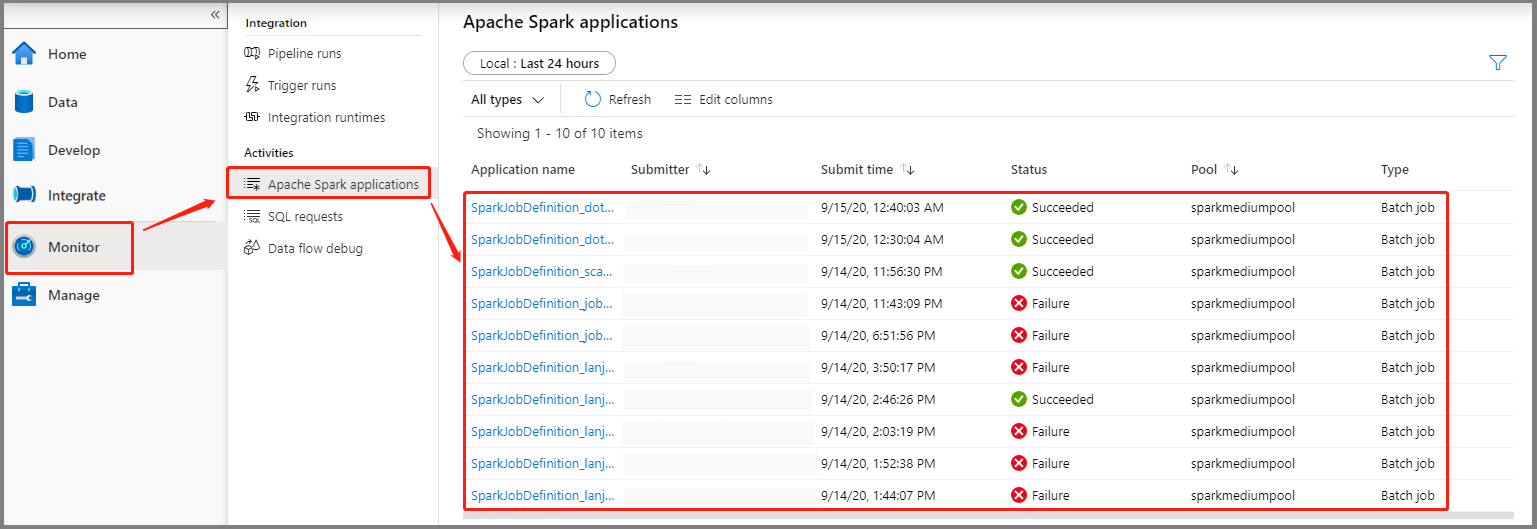
Ezután válasszon ki egy Apache Spark-alkalmazást, és megjelenik a SparkJobDefinition feladat ablaka. A feladat végrehajtásának előrehaladását innen tekintheti meg.
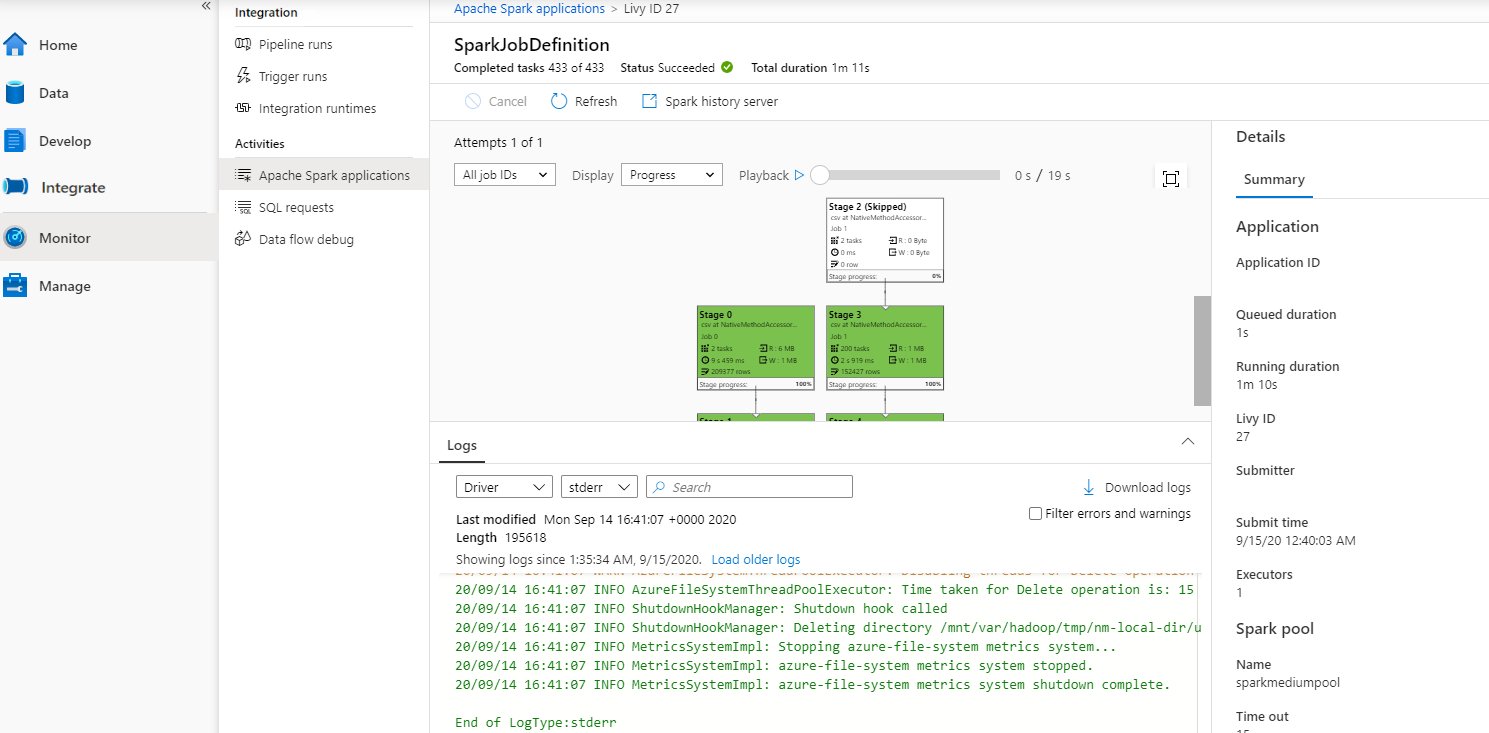
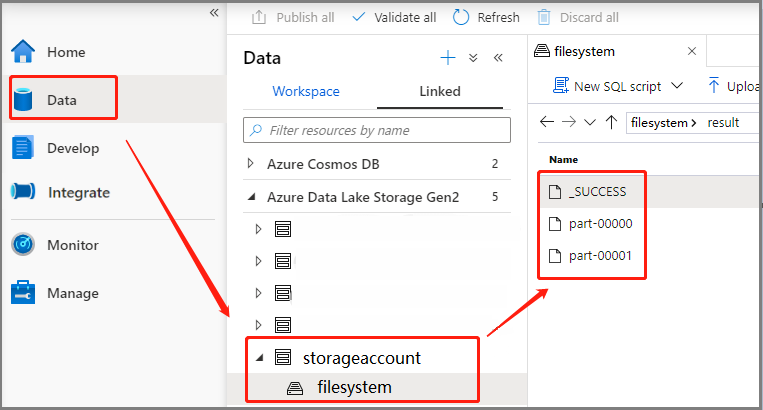
3. forgatókönyv: Kimeneti fájl ellenőrzése
Válassza a Data -Linked ->>Azure Data Lake Storage Gen2 (hozhaobdbj) lehetőséget, nyissa meg a korábban létrehozott eredménymappát, nyissa meg az eredménymappát, és ellenőrizze, hogy létrejött-e a kimenet.
Apache Spark-feladatdefiníció hozzáadása a folyamathoz
Ebben a szakaszban egy Apache Spark-feladatdefiníciót ad hozzá a folyamathoz.
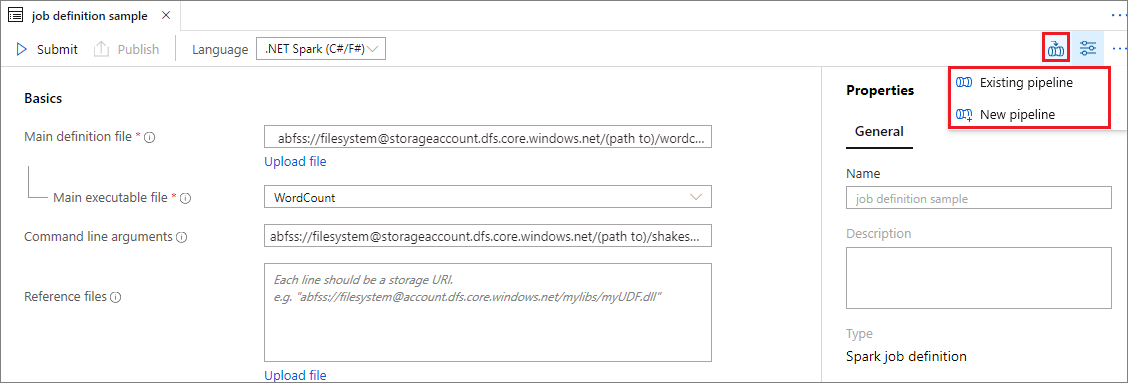
Nyisson meg egy meglévő Apache Spark-feladatdefiníciót.
Válassza az Apache Spark-feladatdefiníció jobb felső részén található ikont, válassza a Meglévő folyamat vagy az Új folyamat lehetőséget. További információkért tekintse meg a Folyamat lapot.
Következő lépések
Ezután az Azure Synapse Studióval Power BI-adatkészleteket hozhat létre és kezelheti a Power BI-adatokat. További információ: Power BI-munkaterület csatolása Synapse-munkaterülethez .
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: