Apache Spark-készletek kódtárainak kezelése az Azure Synapse Analyticsben
Miután azonosította a Spark-alkalmazáshoz használni vagy frissíteni kívánt Scala-, Java-, R- (előzetes verzió) vagy Python-csomagokat, telepítheti vagy eltávolíthatja őket egy Spark-készletben. A készletszintű kódtárak a készleten futó összes jegyzetfüzet és feladat számára elérhetők.
A Spark-készletre kétféleképpen telepíthet kódtárat:
- Telepítsen egy munkaterület-csomagként feltöltött munkaterület-tárat.
- Python-kódtárak frissítéséhez adjon meg egy requirements.txt vagy Conda environment.yml környezeti specifikációt a csomagok telepítéséhez olyan adattárakból, mint a PyPI, a Conda-Forge stb. További információért olvassa el a környezeti specifikációról szóló szakaszt.
A módosítások mentése után egy Spark-feladat futtatja a telepítést, és gyorsítótárazza az eredményül kapott környezetet későbbi felhasználás céljából. A feladat befejezése után az új Spark-feladatok vagy jegyzetfüzet-munkamenetek a frissített készletkódtárakat fogják használni.
Fontos
- Ha a telepítendő csomag nagy méretű, vagy hosszú ideig tart a telepítés, ez hatással van a Spark-példány indítási idejére.
- A PySpark, a Python, a Scala/Java, a .NET, az R vagy a Spark verzió módosítása nem támogatott.
- A csomagok külső adattárakból, például a PyPI-ből, a Conda-Forge-ból vagy az alapértelmezett Conda-csatornákból való telepítése nem támogatott az adatkiszivárgás elleni védelemmel kompatibilis munkaterületeken.
Csomagok kezelése Synapse Studio vagy Azure Portal
A Spark-készlettárak a Synapse Studio vagy Azure Portal kezelhetők.
Kódtárak frissítése vagy hozzáadása Spark-készlethez:
Lépjen a Azure Synapse Analytics-munkaterületre a Azure Portal.
Ha a Azure Portal frissít:
A Synapse-erőforrások szakaszban válassza az Apache Spark-készletek lapot, és válasszon ki egy Spark-készletet a listából.
Válassza a Csomagok elemet a Spark-készlet Beállítások szakaszában.
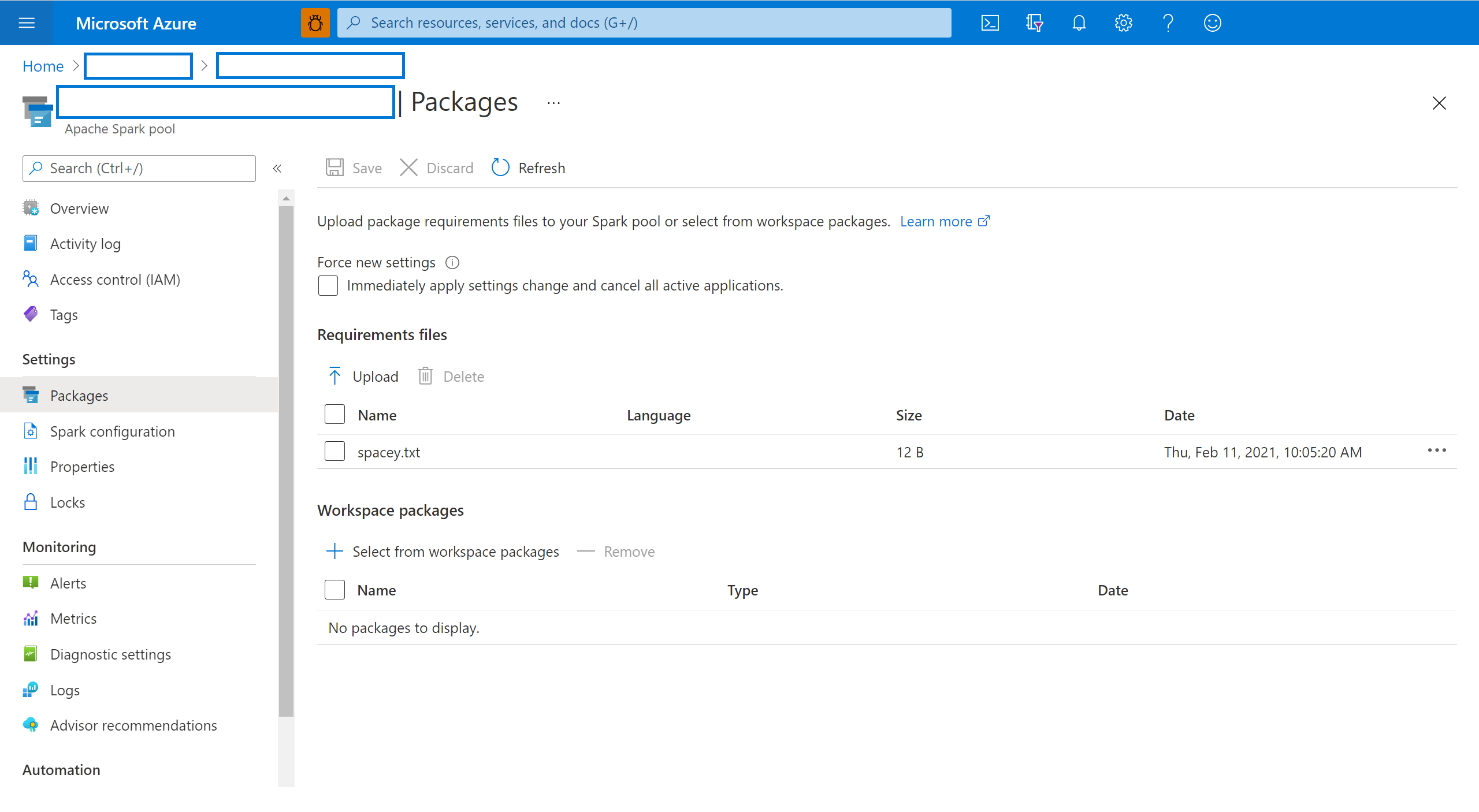
Ha a Synapse Studio frissít:
A fő navigációs panelen válassza a Kezelés , majd az Apache Spark-készletek lehetőséget.
Válassza ki egy adott Spark-készlet Csomagok szakaszát.

Python-hírcsatorna-kódtárak esetén töltse fel a környezeti konfigurációs fájlt a lap Csomagok szakaszában található fájlválasztóval.
További munkaterület-csomagokat is kiválaszthat, ha Jar-, Wheel- vagy Tar.gz-fájlokat szeretne hozzáadni a készlethez.
Az elavult csomagokat a Munkaterület-csomagok szakaszból is eltávolíthatja, a készlet többé nem csatolja ezeket a csomagokat.
A módosítások mentése után egy rendszerfeladat aktiválódik a megadott kódtárak telepítéséhez és gyorsítótárazásához. Ez a folyamat segít csökkenteni a munkamenetek indítási idejét.
Miután a feladat sikeresen befejeződött, minden új munkamenet felveszi a frissített készletkódtárakat.


Fontos
Az Új beállítások kényszerítése lehetőség kiválasztásával befejezheti a kijelölt Spark-készlet összes aktuális munkamenetét. A munkamenetek befejeződése után meg kell várnia, amíg a készlet újraindul.
Ha ez a beállítás nincs bejelölve, akkor meg kell várnia, amíg az aktuális Spark-munkamenet befejeződik vagy manuálisan leáll. A munkamenet befejezése után hagyja, hogy a készlet újrainduljon.
A telepítés előrehaladásának nyomon követése
A rendszer minden alkalommal elindít egy rendszer által fenntartott Spark-feladatot, amikor egy készlet új kódtárakkal frissül. Ez a Spark-feladat segít az erőforrástár telepítésének állapotának monitorozásában. Ha a telepítés kódtárütközések vagy egyéb problémák miatt meghiúsul, a Spark-készlet visszaáll a korábbi vagy alapértelmezett állapotára.
Emellett a felhasználók a telepítési naplókat is megvizsgálhatják a függőségi ütközések azonosítása érdekében, vagy megtekinthetik, hogy mely kódtárak lettek telepítve a készlet frissítése során.
A naplók megtekintése:
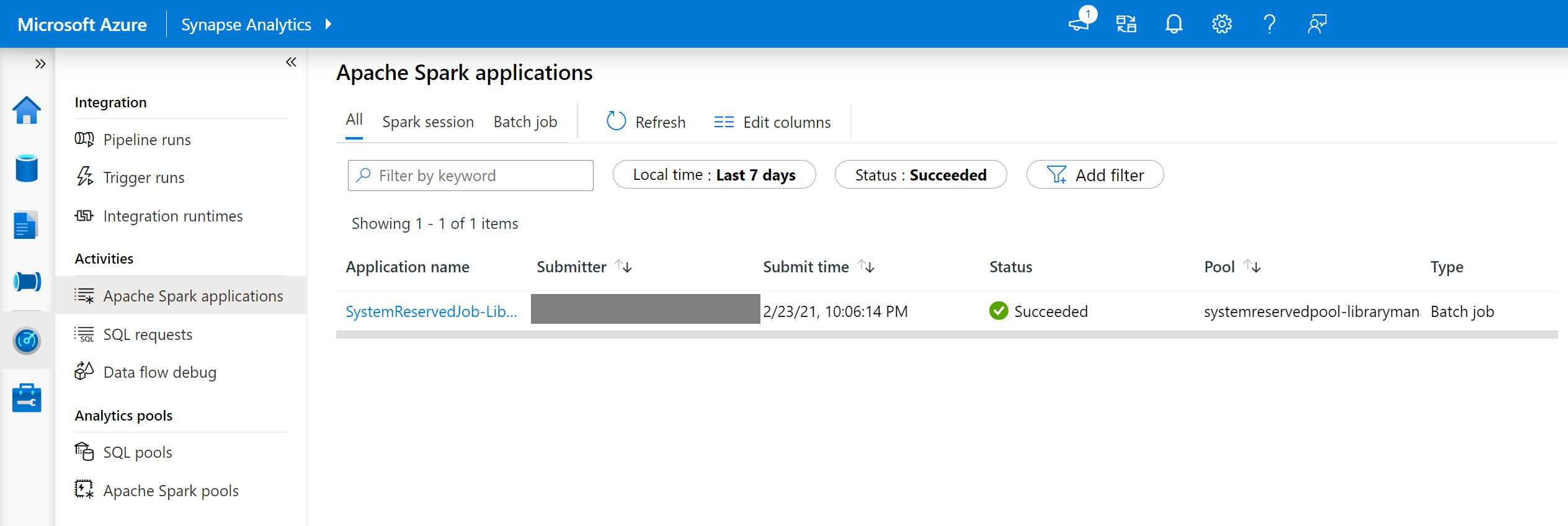
- Lépjen a Spark-alkalmazások listájára a Monitorozás lapon.
- Válassza ki a készletfrissítésnek megfelelő Rendszer Spark-alkalmazásfeladatot. Ezek a rendszerfeladatok a SystemReservedJob-LibraryManagement cím alatt futnak .
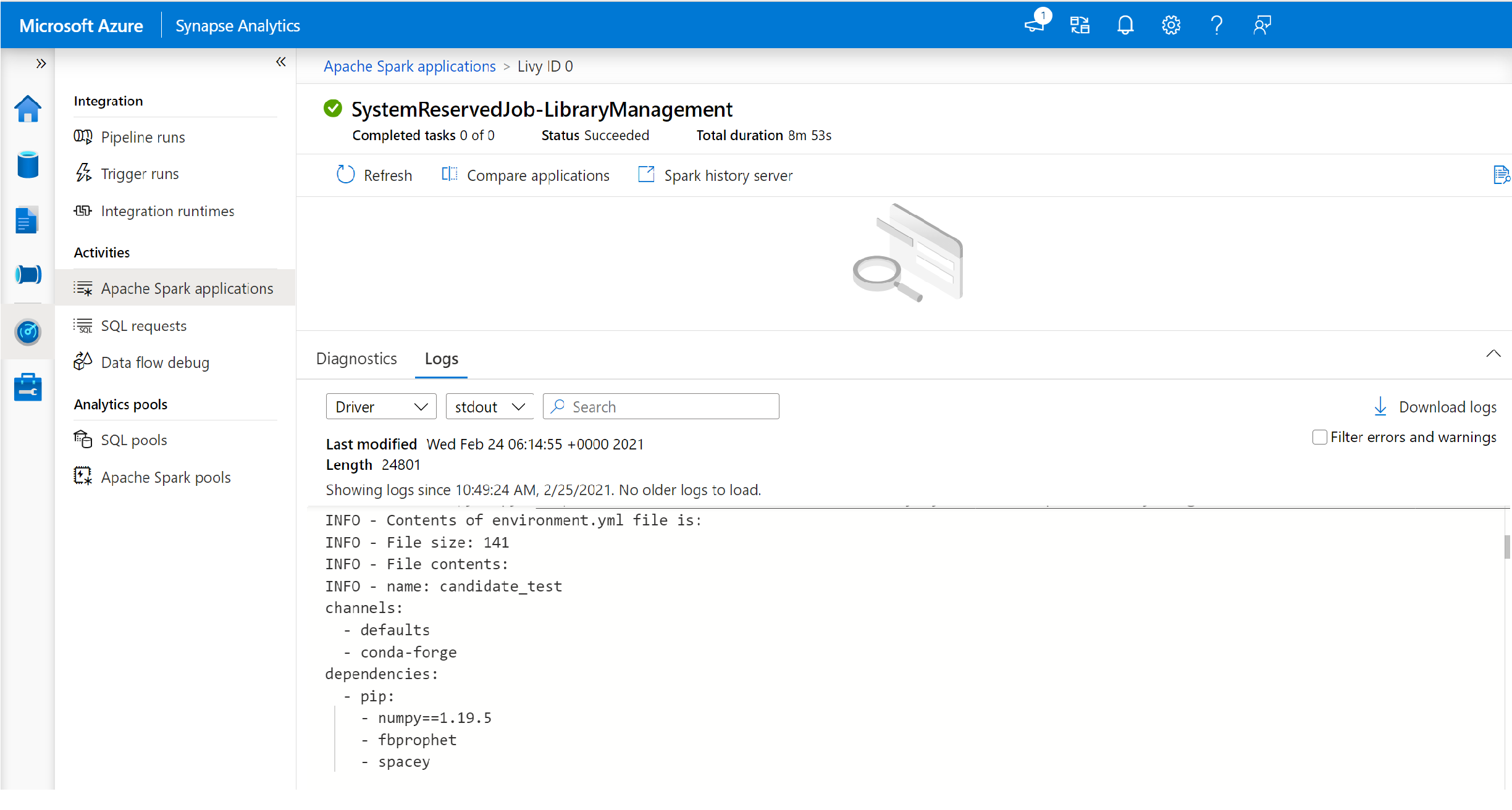
- Váltson az illesztőprogram és az stdout naplóinak megtekintéséhez.
- Az eredmények között megjelennek a függőségek telepítésével kapcsolatos naplók.


Környezeti specifikációk formátumai
PIP-requirements.txt
A környezet frissítéséhezrequirements.txtfájl (a pip freeze parancs kimenete) használható. A készlet frissítésekor a fájlban felsorolt csomagok a PyPI-ből töltődnek le. A rendszer ezután gyorsítótárazza és menti a teljes függőségeket a készlet későbbi újrafelhasználása érdekében.
Az alábbi kódrészlet a követelményfájl formátumát mutatja be. A PyPI-csomag neve a pontos verzióval együtt jelenik meg. Ez a fájl a pip freeze referenciadokumentációban leírt formátumot követi.
Ez a példa egy adott verziót rögzít.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
YML formátum
Emellett megadhat egy environment.yml fájlt is a készletkörnyezet frissítéséhez. A fájlban felsorolt csomagok az alapértelmezett Conda-csatornákról, a Conda-Forge-ból és a PyPI-ből töltődnek le. A konfigurációs beállításokkal más csatornákat is megadhat, vagy eltávolíthatja az alapértelmezett csatornákat.
Ez a példa a csatornákat és a Conda-/PyPI-függőségeket határozza meg.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
A környezetnek a environment.yml fájlból történő létrehozásával kapcsolatos részletekért lásd: Környezet létrehozása environment.yml fájlból.
Következő lépések
- Az alapértelmezett kódtárak megtekintése: Apache Spark-verzió támogatása
- Könyvtártelepítési hibák elhárítása: Kódtárhibák elhárítása