Apache Spark-feladatok optimalizálása az Azure Synapse Analyticsben
Megtudhatja, hogyan optimalizálhat egy Apache Spark-fürtkonfigurációt az adott számítási feladathoz. A leggyakoribb kihívás a memória leterheltsége, amelynek okai lehetnek a nem megfelelő konfigurációk (különösen a nem megfelelő méretű végrehajtók), a hosszan futó műveletek, valamint a Descartes-műveleteket eredményező feladatok. A megfelelő gyorsítótárazással és az adateltérés engedélyezésével felgyorsíthatja a feladatokat. A legjobb teljesítmény érdekében monitorozza és tekintse át a hosszú ideig futó és erőforrás-igényes Spark-feladatvégrehajtásokat.
Az alábbi szakaszok a Spark-feladatok gyakori optimalizálását és javaslatait ismertetik.
Az adat absztrakciójának kiválasztása
A korábbi Spark-verziók RDD-k használatával absztrakciós adatokat, a Spark 1.3-at és az 1.6-os verzióban bevezetett DataFrame-eket és adatkészleteket használnak. Vegye figyelembe a következő relatív érdemeket:
- Adatkeretek
- A legjobb választás a legtöbb helyzetben.
- A Catalyst használatával biztosítja a lekérdezésoptimalizálást.
- Teljes körű kódlétrehozás.
- Közvetlen memória-hozzáférés.
- Alacsony szemétgyűjtési (GC) többletterhelés.
- Nem olyan fejlesztőbarát, mint az Adathalmazok, mivel nincs fordítási idő ellenőrzése vagy tartományi objektum programozása.
- Adatkészletek
- Olyan összetett ETL-folyamatokban jó, ahol a teljesítményre gyakorolt hatás elfogadható.
- Nem jó az olyan összesítésekben, ahol a teljesítményre gyakorolt hatás jelentős lehet.
- A Catalyst használatával biztosítja a lekérdezésoptimalizálást.
- Fejlesztőbarát a tartományi objektumok programozásával és a fordítási idő ellenőrzésével.
- Szerializálási/deszerializálási többletterhelés hozzáadása.
- Magas GC-többletterhelés.
- Megszakítja a teljes fázisú kódgenerálást.
- RDD-k
- Nem kell RDD-ket használnia, kivéve, ha új egyéni RDD-t kell létrehoznia.
- Nincs lekérdezésoptimalizálás a Catalyst használatával.
- Nincs teljes fázisú kódgenerálás.
- Magas GC-többletterhelés.
- Spark 1.x örökölt API-kat kell használnia.
Optimális adatformátum használata
A Spark számos formátumot támogat, például csv, json, xml, parquet, orc és avro. A Spark kiterjeszthető, hogy még sok más formátumot is támogatjon külső adatforrásokkal – további információt az Apache Spark-csomagok című témakörben talál.
A teljesítmény szempontjából a legjobb formátum a parquet beépülő modul tömörítése, amely a Spark 2.x alapértelmezett formátuma. A Parquet oszlopos formátumban tárolja az adatokat, és a Sparkban rendkívül optimalizált. Emellett, míg a dokkolt tömörítés nagyobb fájlokat eredményezhet, mint mondjuk gzip tömörítés. A fájlok felosztható jellege miatt gyorsabban bontják le a fájlokat.
Gyorsítótár használata
A Spark saját natív gyorsítótárazási mechanizmusokat biztosít, amelyek különböző módszerekkel használhatók, például .persist(), .cache()és CACHE TABLE. Ez a natív gyorsítótárazás kis adatkészletekben és ETL-folyamatokban is hatékony, ahol a köztes eredményeket gyorsítótárazza. A Spark natív gyorsítótárazása azonban jelenleg nem működik jól a particionálással, mivel a gyorsítótárazott táblák nem őrzik meg a particionálási adatokat.
A memória hatékony használata
A Spark az adatok memóriába helyezésével működik, így a memóriaerőforrások kezelése kulcsfontosságú szempont a Spark-feladatok végrehajtásának optimalizálásában. A fürt memóriájának hatékony használatához számos technikát alkalmazhat.
- A particionálási stratégia a kisebb adatpartíciókat és fiókokat részesíti előnyben az adatméret, -típusok és -elosztás szempontjából.
- Az alapértelmezett Java-szerializálás helyett fontolja meg az újabb, hatékonyabb Kryo-adatszerializálást.
- A Spark konfigurációs beállításainak figyelése és finomhangolása.
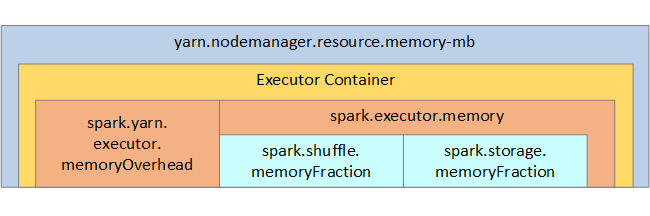
Referenciaként a Spark memóriaszerkezete és néhány fő végrehajtó memóriaparamétere megjelenik a következő képen.
Spark-memóriahasználati szempontok
Az Apache Spark Azure Synapse YARN Apache Hadoop YARN-t használ, a YARN az egyes Spark-csomópontok összes tárolója által használt memória maximális összegét szabályozza. Az alábbi ábrán a fő objektumok és azok kapcsolatai láthatók.
A "kevés memóriával" kapcsolatos üzenetek kezeléséhez próbálkozzon a következőkkel:
- Tekintse át a DAG felügyeleti átrendezéseket. Csökkentés térképoldali csökkentéssel, előparticionálással (vagy gyűjtőbe rendezés) a forrásadatokkal, az egyetlen sorrend maximalizálása és az elküldött adatok mennyiségének csökkentése.
- A rögzített memóriakorlátot inkább
ReduceByKeya értékre szeretné szabniGroupByKey, amely összesítéseket, ablakozást és egyéb függvényeket biztosít, de kötetlen memóriakorláttal rendelkezik. - Előnyben részesítse
TreeReducea parancsot, amely több munkát végez a végrehajtókon vagy partíciókon, a -tReduce, amely minden munkát végez az illesztőprogramon. - Az alacsonyabb szintű RDD-objektumok helyett használja a DataFrame-eket.
- Olyan ComplexType-okat hozhat létre, amelyek műveleteket foglalnak magában, például "Top N", különböző összesítések vagy ablakozási műveletek.
Az adatszerializálás optimalizálása
A Spark-feladatok elosztottak, így a legjobb teljesítmény érdekében fontos a megfelelő adat szerializálás. A Sparkhoz két szerializálási lehetőség érhető el:
- A Java-szerializálás az alapértelmezett beállítás.
- A Kryo szerializálás egy újabb formátum, amely gyorsabb és kompaktabb szerializálást eredményezhet, mint a Java. A Kryo megköveteli, hogy regisztrálja az osztályokat a programban, és még nem támogatja az összes szerializálható típust.
Gyűjtés használata
A gyűjtőzés hasonló az adatparticionáláshoz, de minden gyűjtő nem csak egy, hanem egy oszlopértékkészletet is tartalmazhat. A gyűjtők kiválóan alkalmasak nagy (több millió vagy több millió) érték, például termékazonosítók particionálására. A gyűjtők meghatározása a sor gyűjtőkulcsának kivonatolásával történik. A gyűjtőtáblák egyedi optimalizálásokat kínálnak, mivel metaadatokat tárolnak arról, hogyan lettek gyűjtve és rendezve.
Néhány speciális gyűjtőfunkció:
- Lekérdezésoptimalizálás a metaadatok gyűjtőbe gyűjtése alapján.
- Optimalizált összesítések.
- Optimalizált illesztések.
Egyidejűleg particionálást és gyűjtőmunkát is használhat.
A csatlakozás és a véletlen sorrend optimalizálása
Ha lassú feladatok vannak egy illesztésen vagy shuffle-en, az ok valószínűleg az adateltérés, ami a feladatadatokban aszimmetria. Egy leképezési feladat például 20 másodpercet is igénybe vehet, de egy olyan feladat futtatása, amelyben az adatok össze vannak kapcsolva vagy el vannak elosztással, órákba telik. Az adateltérés javításához sózza a teljes kulcsot, vagy használjon izolált sót a kulcsok csak bizonyos részhalmazához. Ha izolált sót használ, további szűréssel elkülönítheti a sózott kulcsok részhalmazát a térképillesztésekben. Egy másik lehetőség, hogy először egy gyűjtőoszlopot és egy előre összesítést vezet be a gyűjtőkben.
A lassú illesztéseket okozó másik tényező lehet az illesztés típusa. Alapértelmezés szerint a Spark az SortMerge illesztés típusát használja. Ez az illesztéstípus leginkább nagy adathalmazokhoz ideális, de egyébként számítási szempontból költséges, mivel először az adatok bal és jobb oldalát kell rendeznie, mielőtt egyesítené őket.
Az Broadcast illesztés kisebb adathalmazokhoz ideális, vagy ha az illesztés egyik oldala sokkal kisebb, mint a másik. Ez az illesztéstípus az összes végrehajtó egyik oldalát közvetíti, így általában több memóriát igényel a közvetítésekhez.
A konfigurációban módosíthatja az illesztés típusát a beállítással spark.sql.autoBroadcastJoinThreshold, vagy beállíthat egy illesztési tippet a DataFrame API-k (dataframe.join(broadcast(df2))) használatával.
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
Ha gyűjtőtáblákat használ, akkor van egy harmadik illesztéstípusa, az Merge illesztés. A megfelelően előre particionált és előre rendezett adathalmazok kihagyják a drága rendezési fázist egy SortMerge illesztésből.
Az illesztések sorrendje számít, különösen az összetettebb lekérdezésekben. Kezdje a legválogatottabb illesztésekkel. Emellett áthelyezhet olyan illesztéseket is, amelyek lehetőség szerint növelik a sorok számát az összesítések után.
A Cartesian-illesztések párhuzamosságának kezeléséhez hozzáadhat beágyazott struktúrákat, ablakokat, és kihagyhat egy vagy több lépést a Spark-feladatban.
Válassza ki a megfelelő végrehajtóméretet
A végrehajtó konfigurációjának kiválasztásakor vegye figyelembe a Java szemétgyűjtési (GC) többletterhelését.
A végrehajtó méretének csökkentésére használt tényezők:
- Csökkentse a halommemória méretét 32 GB alá, hogy a GC többletterhelése < 10%legyen.
- Csökkentse a magok számát, hogy a GC többletterhelése < 10%legyen.
A végrehajtó méretének növelését befolyásoló tényezők:
- Csökkentse a végrehajtók közötti kommunikációs többletterhelést.
- Csökkentse a nagyobb fürtökön> (100 végrehajtó) lévő végrehajtók (N2) közötti nyitott kapcsolatok számát.
- Növelje a heapméretet a memóriaigényes feladatokhoz való igazodáshoz.
- Nem kötelező: Csökkentse a végrehajtónkénti memóriaterhelést.
- Nem kötelező: Növelje a kihasználtságot és az egyidejűséget a processzor túljegyzésével.
A végrehajtó méretének kiválasztásakor a hüvelykujj általános szabálya:
- Első lépésként 30 GB végrehajtónként, és ossza el a rendelkezésre álló gépmagokat.
- Növelje a nagyobb fürtök végrehajtó magjainak számát (> 100 végrehajtó).
- Módosítsa a méretet a próbafuttatások és az előző tényezők, például a GC többletterhelése alapján.
Egyidejű lekérdezések futtatásakor vegye figyelembe a következőket:
- Első lépésként 30 GB/végrehajtó és minden gépmag.
- Több párhuzamos Spark-alkalmazás létrehozása a processzor túligénylésével (kb. 30%-os késés javulása).
- Lekérdezések elosztása párhuzamos alkalmazások között.
- Módosítsa a méretet a próbafuttatások és az előző tényezők, például a GC többletterhelése alapján.
Az idősornézet, az SQL Graph, a feladatstatisztikák stb. megtekintésével monitorozza a lekérdezési teljesítményt a kiugró értékek vagy egyéb teljesítményproblémák esetén. Néha egy vagy néhány végrehajtó lassabb, mint a többi, és a feladatok végrehajtása sokkal tovább tart. Ez gyakran előfordul nagyobb fürtökön (> 30 csomóponton). Ebben az esetben ossza el a munkát nagyobb számú tevékenységre, hogy az ütemező kompenzálhassa a lassú tevékenységeket.
Például legalább kétszer annyi feladat van, mint az alkalmazásban lévő végrehajtó magok száma. A feladat spekulatív végrehajtását is engedélyezheti a használatával conf: spark.speculation = true.
A feladat-végrehajtás optimalizálása
- Szükség szerint gyorsítótárazva, például ha kétszer használja az adatokat, akkor gyorsítótárazza.
- Változók szórása az összes végrehajtónak. A változók csak egyszer vannak szerializálva, ami gyorsabb kereséseket eredményez.
- Használja a szálkészletet az illesztőprogramon, ami sok feladat gyorsabb működését eredményezi.
A Spark 2.x lekérdezési teljesítményének kulcsa a volfrámmotor, amely a teljes fázisú kódgenerálástól függ. Bizonyos esetekben előfordulhat, hogy a teljes fázisú kódlétrehozás le van tiltva.
Ha például nem mutable típusú (string) típust használ az aggregációs kifejezésben, SortAggregate a helyett HashAggregatemegjelenik. A jobb teljesítmény érdekében például próbálkozzon a következőkkel, majd engedélyezze újra a kódgenerálást:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))