Bevezetés az Azure Synapse Analytics fájlcsatlakoztatási/leválasztási API-jaiba
Az Azure Synapse Studio csapata két új csatlakoztatási/leválasztott API-t készített a Microsoft Spark Utilities (mssparkutils) csomagban. Ezekkel az API-kkal távoli tárolást (Azure Blob Storage vagy Azure Data Lake Storage Gen2) csatolhat az összes működő csomóponthoz (illesztőprogram-csomóponthoz és feldolgozó csomóponthoz). A tárolást követően a helyi fájl API-val úgy érheti el az adatokat, mintha a helyi fájlrendszerben tárolva lenne. További információ: Bevezetés a Microsoft Spark segédprogramok használatába.
A cikk bemutatja, hogyan használhatja a csatlakoztatási/leválasztott API-kat a munkaterületen. Az oktatóanyagból a következőket sajátíthatja el:
- A Data Lake Storage Gen2 vagy a Blob Storage csatlakoztatása.
- A csatlakoztatási pont alatti fájlok elérése a helyi fájlrendszer API-jának használatával.
- A csatlakoztatási pont alatti fájlok elérése az
mssparktuils fsAPI használatával. - A csatlakoztatási pont alatti fájlok elérése a Spark olvasási API-val.
- A csatlakoztatási pont leválasztása.
Figyelmeztetés
Az Azure-fájlmegosztás csatlakoztatása átmenetileg le van tiltva. Ehelyett használhatja a Data Lake Storage Gen2 vagy az Azure Blob Storage csatlakoztatását a következő szakaszban leírtak szerint.
Az Azure Data Lake Storage Gen1 storage nem támogatott. A Csatlakoztatási API-k használata előtt az Azure Data Lake Storage Gen1 és Gen2 migrálási útmutatóját követve migrálhat a Data Lake Storage Gen2-be.
Tároló csatlakoztatása
Ez a szakasz példaként bemutatja, hogyan csatlakoztathatja lépésről lépésre a Data Lake Storage Gen2-t. A Blob Storage csatlakoztatása hasonlóan működik.
A példa azt feltételezi, hogy egy Data Lake Storage Gen2-fiókkal rendelkezik storegen2. A fióknak van egy olyan tárolója, amelyhez mycontainer csatlakoztatni /test szeretné a Spark-készletet.
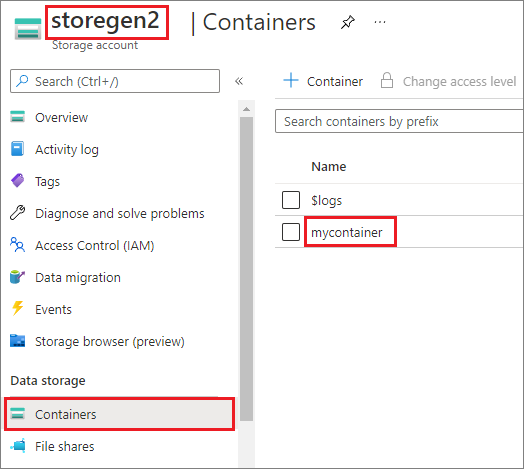
A hívott mycontainermssparkutils tároló csatlakoztatásához először ellenőriznie kell, hogy rendelkezik-e engedéllyel a tároló eléréséhez. Az Azure Synapse Analytics jelenleg három hitelesítési módszert támogat az eseményindító csatlakoztatási műveletéhez: linkedService, accountKeyés sastoken.
Csatlakoztatás társított szolgáltatással (ajánlott)
Az eseményindító csatlakoztatását a társított szolgáltatáson keresztül javasoljuk. Ez a módszer elkerüli a biztonsági szivárgásokat, mert mssparkutils nem tárol titkos vagy hitelesítési értékeket. mssparkutils Ehelyett mindig lekéri a hitelesítési értékeket a társított szolgáltatásból a blobadatok távoli tárolóból való lekéréséhez.
Létrehozhat egy társított szolgáltatást a Data Lake Storage Gen2-hez vagy a Blob Storage-hoz. Az Azure Synapse Analytics jelenleg két hitelesítési módszert támogat csatolt szolgáltatás létrehozásakor:
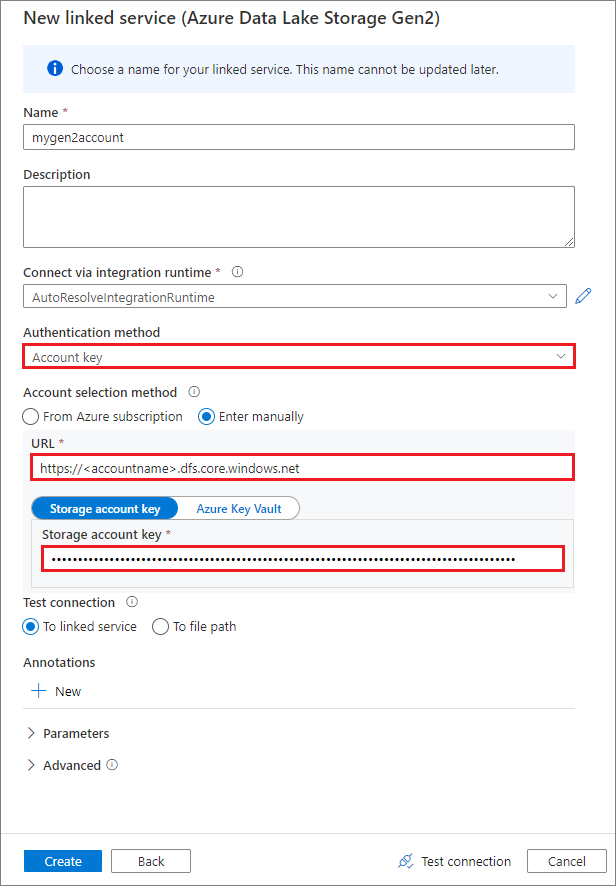
Társított szolgáltatás létrehozása fiókkulcs használatával
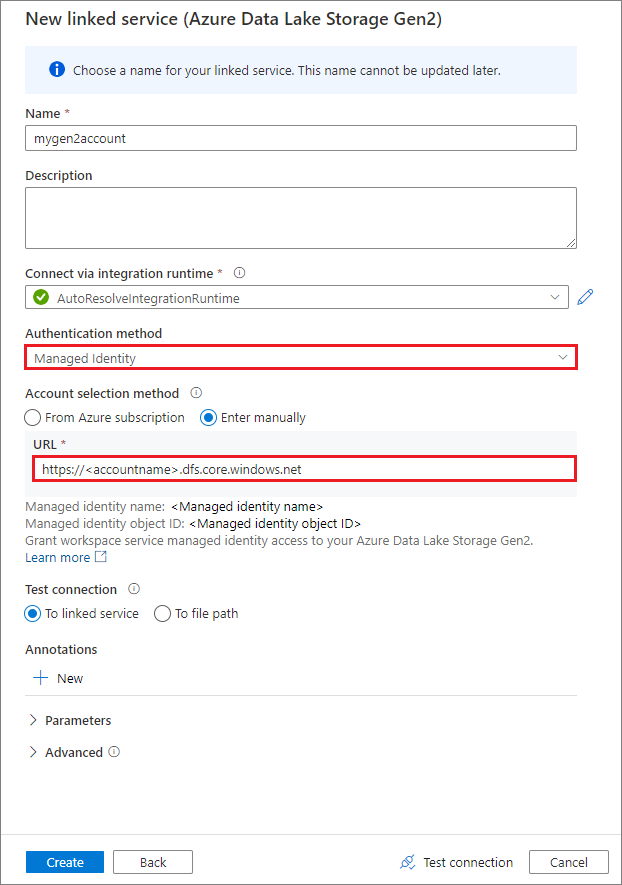
Társított szolgáltatás létrehozása rendszer által hozzárendelt felügyelt identitással
Fontos
- Ha a fent létrehozott Társított szolgáltatás az Azure Data Lake Storage Gen2-hez felügyelt privát végpontot használ (dfs URI-val), akkor létre kell hoznunk egy másik másodlagos felügyelt privát végpontot az Azure Blob Storage lehetőséggel (blob URI-val), hogy a belső fsspec/adlfs-kód a BlobServiceClient felület használatával kapcsolódhasson.
- Ha a másodlagos felügyelt privát végpont nincs megfelelően konfigurálva, akkor hibaüzenet jelenik meg, például ServiceRequestError: Nem lehet csatlakozni a gazdagéphez [storageaccountname].blob.core.windows.net:443 ssl:True [Név vagy szolgáltatás nem ismert]
Feljegyzés
Ha egy társított szolgáltatást felügyelt identitás használatával hoz létre hitelesítési módszerként, győződjön meg arról, hogy a munkaterületi MSI-fájl rendelkezik a csatlakoztatott tároló Storage Blob Data Közreműködő szerepkörével.
A társított szolgáltatás sikeres létrehozása után egyszerűen csatlakoztathatja a tárolót a Spark-készlethez a következő Python-kóddal:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Feljegyzés
Előfordulhat, hogy importálnia mssparkutils kell, ha nem érhető el:
from notebookutils import mssparkutils
Nem ajánlott gyökérmappát csatlakoztatni, függetlenül attól, hogy melyik hitelesítési módszert használja.
Csatlakoztatási paraméterek:
- fileCacheTimeout: A blobok alapértelmezés szerint 120 másodpercig lesznek gyorsítótárazva a helyi ideiglenes mappában. Ez idő alatt a Blobfuse nem ellenőrzi, hogy a fájl naprakész-e vagy sem. A paraméter beállítható úgy, hogy módosítsa az alapértelmezett időtúllépési időt. Ha egyszerre több ügyfél is módosítja a fájlokat, a helyi és a távoli fájlok közötti ellentmondások elkerülése érdekében javasoljuk, hogy lerövidítse a gyorsítótár idejét, vagy akár 0-ra módosítsa, és mindig a legújabb fájlokat kapja a kiszolgálótól.
- időtúllépés: A csatlakoztatási művelet időkorlátja alapértelmezés szerint 120 másodperc. A paraméter beállítható úgy, hogy módosítsa az alapértelmezett időtúllépési időt. Ha túl sok végrehajtó van, vagy ha a csatlakoztatás túllépi az időkorlátot, javasoljuk az érték növelését.
- hatókör: A rendszer a csatlakoztatás hatókörének megadására használja a hatókört. Az alapértelmezett érték a "feladat". Ha a hatókör "feladat" értékre van állítva, a csatlakoztatás csak az aktuális fürt számára látható. Ha a hatókör "munkaterület" értékre van állítva, a csatlakoztatás az aktuális munkaterület összes jegyzetfüzete számára látható, és a csatlakoztatási pont automatikusan létrejön, ha nem létezik. Adja hozzá ugyanazokat a paramétereket a leválasztott API-hoz a csatlakoztatási pont leválasztásához. A munkaterületszintű csatlakoztatás csak csatolt szolgáltatáshitelesítés esetén támogatott.
A következő paramétereket használhatja:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Csatlakoztatás megosztott hozzáférésű jogosultságkód jogkivonaton vagy fiókkulcson keresztül
A társított szolgáltatáson mssparkutils keresztüli csatlakoztatás mellett támogatja a fiókkulcs vagy a közös hozzáférésű jogosultságkód (SAS) jogkivonat paraméterként történő átadását a cél csatlakoztatásához.
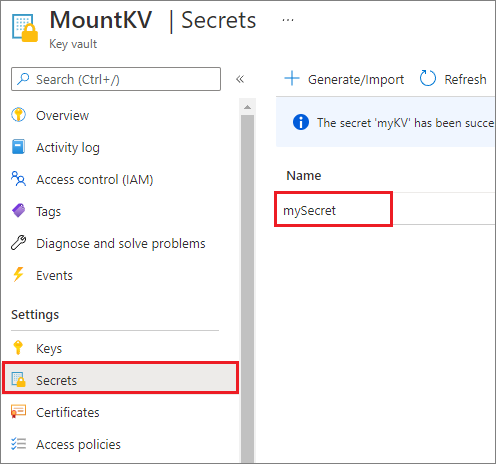
Biztonsági okokból javasoljuk, hogy a fiókkulcsokat vagy SAS-jogkivonatokat az Azure Key Vaultban tárolja (ahogy az alábbi példa képernyőképe is mutatja). Ezután lekérheti őket az mssparkutil.credentials.getSecret API használatával. További információ: Tárfiókkulcsok kezelése a Key Vaulttal és az Azure CLI-vel (örökölt).
Íme a mintakód:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Feljegyzés
Biztonsági okokból ne tárolja a hitelesítő adatokat kódban.
Fájlok elérése a csatlakoztatási pont alatt az mssparkutils fs API használatával
A csatlakoztatási művelet fő célja, hogy az ügyfelek egy helyi fájlrendszer API-val érhessék el a távoli tárfiókban tárolt adatokat. Az adatokat úgy is elérheti, hogy az mssparkutils fs API-val egy csatlakoztatott elérési utat használ paraméterként. Az itt használt elérési út formátuma kissé eltérő.
Feltéve, hogy csatlakoztatta a Data Lake Storage Gen2 tárolómontainert a csatlakoztatási API használatával történő /teszteléshez. Amikor egy helyi fájlrendszer API-jának használatával éri el az adatokat:
- A Spark 3.3-nál kisebb vagy egyenlő verziói esetén az elérési út formátuma
/synfs/{jobId}/test/{filename}. - A 3,4-nél nagyobb vagy egyenlő Spark-verziók esetében az elérési út formátuma .
/synfs/notebook/{jobId}/test/{filename}
Javasoljuk, mssparkutils.fs.getMountPath() hogy a pontos elérési utat használja:
path = mssparkutils.fs.getMountPath("/test")
Feljegyzés
Ha hatókörrel workspace csatlakoztatja a tárolót, a csatlakoztatási pont a /synfs/workspace mappa alatt jön létre. És a pontos útvonalat kell használnia mssparkutils.fs.getMountPath("/test", "workspace") .
Ha az API-val szeretné elérni az mssparkutils fs adatokat, az elérési út formátuma a következő: synfs:/notebook/{jobId}/test/{filename}. synfs Ebben az esetben a rendszer sémaként használja a csatlakoztatott elérési út egy része helyett. Természetesen a helyi fájlrendszersémával is hozzáférhet az adatokhoz. Például: file:/synfs/notebook/{jobId}/test/{filename}.
Az alábbi három példa bemutatja, hogyan érheti el a csatlakoztatási pont elérési útját tartalmazó fájlokat a használatával mssparkutils fs.
Címtárak listázása:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Fájltartalom olvasása:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Címtár létrehozása:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Fájlok elérése a csatlakoztatási pont alatt a Spark read API használatával
Megadhat egy paramétert az adatok eléréséhez a Spark olvasási API-jának használatával. Az elérési út formátuma megegyezik az mssparkutils fs API használatakor.
Fájl beolvasása csatlakoztatott Data Lake Storage Gen2-tárfiókból
Az alábbi példa feltételezi, hogy egy Data Lake Storage Gen2-tárfiók már csatlakoztatva van, majd egy csatlakoztatási útvonal használatával olvassa el a fájlt:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Feljegyzés
Ha csatolt szolgáltatással csatlakoztatja a tárolót, mindig explicit módon állítsa be a Spark társított szolgáltatás konfigurációját, mielőtt synfs-sémát használ az adatok eléréséhez. Részletekért tekintse meg a csatolt szolgáltatásokkal rendelkező ADLS Gen2-tárolót.
Fájl beolvasása csatlakoztatott Blob Storage-fiókból
Ha csatlakoztatott egy Blob Storage-fiókot, és azt a Spark API-val vagy a Spark API-val mssparkutils szeretné elérni, explicit módon konfigurálnia kell az SAS-jogkivonatot a Spark-konfiguráción keresztül, mielőtt megpróbálná csatlakoztatni a tárolót a csatlakoztatási API használatával:
Ha egy Blob Storage-fiókot az eseményindító csatlakoztatása után a Spark API használatával vagy a Spark API-val
mssparkutilsszeretne elérni, frissítse a Spark-konfigurációt az alábbi kód példában látható módon. Ezt a lépést megkerülheti, ha csak a helyi fájl API-val szeretné elérni a Spark-konfigurációt a csatlakoztatás után.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Hozza létre a társított szolgáltatást
myblobstorageaccount, és csatlakoztassa a Blob Storage-fiókot a társított szolgáltatással:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Csatlakoztassa a Blob Storage-tárolót, majd olvassa el a fájlt egy csatlakoztatási útvonal használatával a helyi fájl API-jának használatával:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Olvassa el az adatokat a csatlakoztatott Blob Storage-tárolóból a Spark read API-val:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
A csatlakoztatási pont leválasztása
A csatlakoztatási pont leválasztásához használja az alábbi kódot (/test ebben a példában):
mssparkutils.fs.unmount("/test")
Ismert korlátozások
A leválasztó mechanizmus nem automatikus. Amikor az alkalmazás futtatása befejeződött, a csatlakoztatási pont leválasztásához a lemezterület felszabadításához explicit módon meg kell hívnia egy leválasztott API-t a kódban. Ellenkező esetben a csatlakoztatási pont az alkalmazás futtatása után is megmarad a csomópontban.
A Data Lake Storage Gen1-tárfiók csatlakoztatása egyelőre nem támogatott.