Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
Ez a cikk bemutatja, hogyan becsülheti meg és kezelheti a kiszolgáló nélküli SQL-készlet költségeit az Azure Synapse Analyticsben:
- A lekérdezés kiadása előtt feldolgozott adatok mennyiségének becslése
- Költségkezelési funkció használata a költségvetés beállításához
Ismerje meg, hogy az Azure Synapse Analytics kiszolgáló nélküli SQL-készletének költségei csak az Azure-számla havi költségeinek egy részét képezik. Ha Ön más Azure-szolgáltatásokat is használ, akkor számlázásra kerül az Azure-előfizetéséhez tartozó összes Azure-szolgáltatásért és erőforrásért, a harmadik fél által nyújtott szolgáltatásokkal együtt. Ez a cikk azt ismerteti, hogyan tervezheti meg és kezelheti a kiszolgáló nélküli SQL-készlet költségeit az Azure Synapse Analyticsben.
Feldolgozott adatok
A feldolgozott adatok azon adatok mennyisége, amelyeket a rendszer ideiglenesen tárol egy lekérdezés futtatása során. A feldolgozott adatok a következő mennyiségekből állnak:
- A tárolóból beolvasott adatok mennyisége. Ez az összeg a következőket tartalmazza:
- Adatok olvasása közben beolvasott adatok.
- Metaadatok olvasása közben beolvasott adatok (metaadatokat tartalmazó fájlformátumok esetén, például Parquet).
- A köztes eredményekben lévő adatok mennyisége. Ezeket az adatokat a lekérdezés futtatásakor a program a csomópontok között továbbítja. Tömörítetlen formátumban tartalmazza a végpont felé történő adatátvitelt.
- A tárolóba írt adatok mennyisége. Ha a CETAS használatával exportálja az eredményhalmazt tárolóba, akkor a rendszer hozzáadja a kiírt adatok mennyiségét a CETAS SELECT részében feldolgozott adatok mennyiségéhez.
A fájlok olvasása a tárolóról rendkívül optimalizált. A folyamat a következőket használja:
- Előletöltés, amely némi többletterhelést jelenthet a beolvasott adatok mennyiségére. Ha egy lekérdezés egy teljes fájlt olvas be, akkor nincs többletterhelés. Ha egy fájl olvasása részben történik, például a TOP N lekérdezésekben, akkor egy kicsit több adatot olvasnak előzetes beolvasással.
- Optimalizált vesszővel tagolt érték (CSV) elemző. Ha a CSV-fájlok olvasásához PARSER_VERSION='2.0' értéket használja, akkor a tárterületről beolvasott adatok mennyisége kismértékben nő. Az optimalizált CSV-elemző a fájlokat párhuzamosan, egyenlő méretű adattömbökben olvassa be. Az adattömbök nem feltétlenül tartalmaznak egész sorokat. Az összes sor elemzése érdekében az optimalizált CSV-elemző a szomszédos adattömbök kis töredékeit is beolvassa. Ez a folyamat kis mennyiségű többletterhelést ad hozzá.
statisztika
A kiszolgáló nélküli SQL-készlet lekérdezésoptimalizálója statisztikákra támaszkodik az optimális lekérdezés-végrehajtási tervek létrehozásához. A statisztikákat manuálisan is létrehozhatja. Ellenkező esetben a kiszolgáló nélküli SQL-készlet automatikusan létrehozza őket. Akárhogy is, a statisztikák egy külön lekérdezés futtatásával jönnek létre, amely egy adott oszlopot ad vissza egy megadott mintasebesség mellett. Ez a lekérdezés a feldolgozott adatok mennyiségéhez van társítva.
Ha ugyanazt a lekérdezést vagy bármely más olyan lekérdezést futtat, amely a létrehozott statisztikák előnyeit élvezné, akkor a statisztikák lehetőség szerint újra felhasználhatók. A statisztikák létrehozásához nincs további feldolgozott adat.
Ha egy Parquet-oszlophoz statisztikákat hoz létre, a rendszer csak a megfelelő oszlopot olvassa be a fájlokból. Ha egy CSV-oszlop statisztikáit hozza létre, a rendszer a teljes fájlokat beolvassa és elemzi.
Kerekítés
A feldolgozott adatok mennyisége lekérdezésenként a legközelebbi MB-ra lesz kerekítve. Minden lekérdezés legalább 10 MB feldolgozott adatval rendelkezik.
A feldolgozott adatok nem tartalmazzák a következőket:
- Kiszolgálószintű metaadatok (például bejelentkezések, szerepkörök és kiszolgálószintű hitelesítő adatok).
- A végponton létrehozott adatbázisok. Ezek az adatbázisok csak metaadatokat tartalmaznak (például felhasználókat, szerepköröket, sémákat, nézeteket, beágyazott táblaértékű függvényeket [TVF-eket], tárolt eljárásokat, adatbázis-hatókörű hitelesítő adatokat, külső adatforrásokat, külső fájlformátumokat és külső táblákat).
- Sémakövetkeztetés használata esetén a rendszer beolvassa a fájltöredékeket az oszlopnevek és adattípusok következtetéséhez, és az olvasási adatok mennyisége hozzáadódik a feldolgozott adatok mennyiségéhez.
- Adatdefiníciós nyelvi (DDL-) utasítások, kivéve a CREATE STATISTICS utasítást, mert a megadott mintaszázada alapján dolgozza fel a tárolóból származó adatokat.
- Csak metaadat-lekérdezések.
A feldolgozott adatok mennyiségének csökkentése
Optimalizálhatja a lekérdezésenkénti feldolgozott adatokat, és javíthatja a teljesítményt úgy, hogy particionálja és tömörített oszlopalapú formátumra konvertálja az adatokat, például a Parquetet.
Példák
Képzelj el három táblát.
- A population_csv táblát 5 TB-nyi CSV-fájlok támogatják. A fájlok öt egyenlő méretű oszlopba vannak rendezve.
- A population_parquet táblában ugyanazok az adatok vannak, mint a population_csv táblában. 1 TB Parquet-fájl támogatja. Ez a táblázat kisebb, mint az előző, mert az adatok parquet formátumban tömörítve lesznek.
- A very_small_csv táblát 100 KB méretű CSV-fájlok támogatják.
1. lekérdezés: SELECT SUM(population) FROM population_csv
Ez a lekérdezés beolvassa és elemzi a teljes fájlokat a sokaság oszlop értékeinek lekéréséhez. A csomópontok feldolgozzák a tábla töredékeit, és az egyes töredékek populációösszegét a csomópontok között továbbítja a program. A végső összeg átkerül a végpontra.
Ez a lekérdezés 5 TB adatot dolgoz fel, valamint egy kis többletterhelést a töredékek összegének átviteléhez.
2. lekérdezés: SELECT SUM(population) FROM population_parquet
Ha tömörített és oszlopalapú formátumokat kérdez le, például a Parquetet, kevesebb adatot olvas be, mint az 1. lekérdezésben. Ez az eredmény azért jelenik meg, mert a kiszolgáló nélküli SQL-készlet egyetlen tömörített oszlopot olvas be a teljes fájl helyett. Ebben az esetben a 0,2 TB olvasható. (Öt egyenlő méretű oszlop egyenként 0,2 TB.) A csomópontok feldolgozzák a tábla töredékeit, és az egyes töredékek populációösszegét a csomópontok között továbbítja a program. A végső összeg átkerül a végpontra.
Ez a lekérdezés 0,2 TB-ot dolgoz fel, plusz egy kis többletterhelést a töredékösszegek átviteléhez.
3. lekérdezés: SELECT * FROM population_parquet
Ez a lekérdezés beolvassa az összes oszlopot, és tömörítetlen formátumban továbbítja az összes adatot. Ha a tömörítési formátum 5:1, akkor a lekérdezés 6 TB-ot dolgoz fel, mert 1 TB-ot olvas be, és 5 TB tömörítetlen adatot továbbít.
4. lekérdezés: SELECT COUNT(*) FROM very_small_csv
Ez a lekérdezés teljes fájlokat olvas be. A tábla tárolójában lévő fájlok teljes mérete 100 KB. A csomópontok feldolgozzák ennek a táblázatnak a töredékeit, és az egyes töredékek összegét a csomópontok között továbbítja a program. A végső összeg átkerül a végpontra.
Ez a lekérdezés valamivel több mint 100 KB adatot dolgoz fel. A lekérdezéshez feldolgozott adatok mennyisége 10 MB-ra kerekítve lesz a cikk Kerekítés szakaszában megadottak szerint.
Költségkezelés
A kiszolgáló nélküli SQL-készlet költségkezelési funkciója lehetővé teszi a feldolgozott adatok költségvetésének beállítását. A költségvetést beállíthatja egy napra, hétre és hónapra feldolgozott adat mennyiségére TB-ban. Ugyanakkor egy vagy több költségvetést is beállíthat. A kiszolgáló nélküli SQL-készlet költségszabályozásának konfigurálásához használhatja a Synapse Studiót vagy a T-SQL-t.
Költségszabályozás konfigurálása kiszolgáló nélküli SQL-készlethez a Synapse Studióban
A kiszolgáló nélküli SQL-készlet költségszabályozásának konfigurálásához a Synapse Studióban lépjen a bal oldali menü Kezelés elemére, és válassza ki az SQL-készlet elemét az Analytics-készletek alatt. Amikor rámutat a kiszolgáló nélküli SQL-készletre, megjelenik egy költségkövetési ikon – kattintson erre az ikonra.
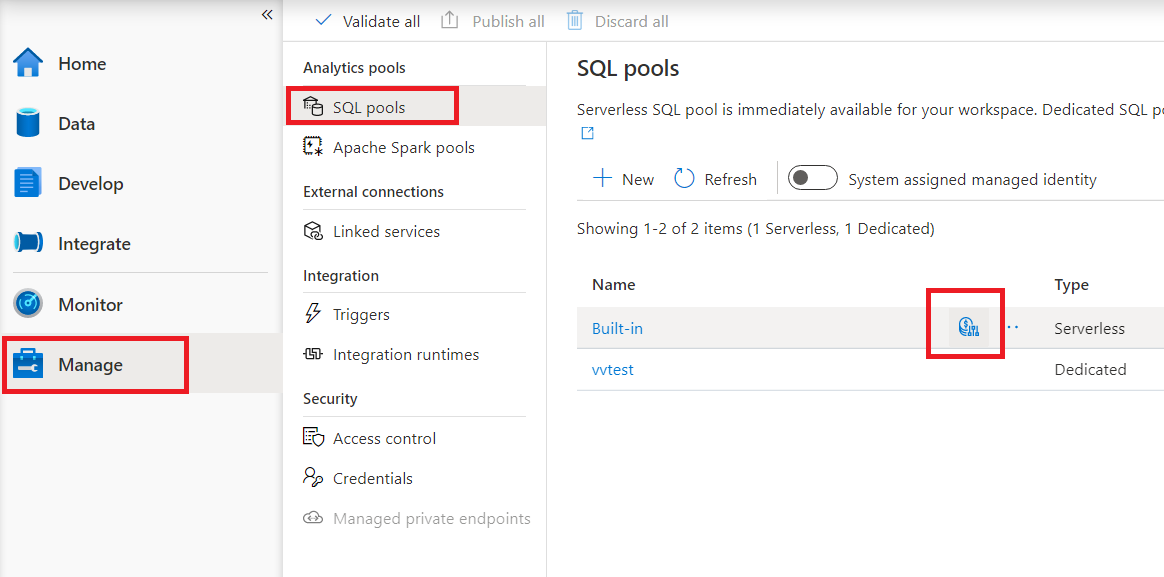
Ha a költségvezérlő ikonra kattint, megjelenik egy oldalsáv:

Ha egy vagy több költségvetést szeretne beállítani, először kattintson a beállítani kívánt költségvetés rádiógombjának engedélyezésére, majd írja be az egész számot a szövegmezőbe. Az érték mértékegysége a TBs. Miután konfigurálta a kívánt költségvetéseket, kattintson az alkalmaz gombra az oldalsáv alján. Ennyi, a költségvetés készen áll.
A kiszolgáló nélküli SQL-készlet költségszabályozásának konfigurálása a T-SQL-ben
A kiszolgáló nélküli SQL-készlet költségszabályozásának A T-SQL-ben való konfigurálásához az alábbi tárolt eljárások közül legalább egyet végre kell hajtania.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Az aktuális konfiguráció megtekintéséhez hajtsa végre a következő T-SQL-utasítást:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Az aktuális nap, hét vagy hónap során feldolgozott adatok számának megtekintéséhez hajtsa végre a következő T-SQL-utasítást:
SELECT * FROM sys.dm_external_data_processed
A költségkontrollban meghatározott korlátok túllépése
Ha a lekérdezés végrehajtása során túllépi a korlátot, a lekérdezés nem fejeződik be.
Ha túllépi a korlátot, a rendszer elutasítja az új lekérdezést a hibaüzenettel, amely az adott időszakra vonatkozó adatokat, az adott időszakra meghatározott korlátot és az adott időszakra feldolgozott adatokat tartalmazza. Ha például új lekérdezést hajtanak végre, ahol a heti korlát 1 TB-ra van állítva, és túllépték, a hibaüzenet a következő lesz:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Következő lépések
A lekérdezések teljesítményoptimalizáltságáról további információt a kiszolgáló nélküli SQL-készlet ajánlott eljárásaiban talál.