NFS 4.1-es verziójú kötetek az SAP HANA-hoz készült Azure NetApp Filesban
Az Azure NetApp Files natív NFS-megosztásokat biztosít, amelyek /hana/shared, /hana/data és /hana/log kötetekhez használhatók. A /hana/data és /hana/log kötetek ANF-alapú NFS-megosztásainak használatához a v4.1 NFS protokoll használata szükséges. Az NFS protokoll v3 nem támogatott a /hana/data és /hana/log kötetek használata esetén, amikor a megosztásokat ANF-en alapozza.
Fontos
Az Azure NetApp Filesban implementált NFS v3 protokoll nem használható /hana/data és /hana/log esetén. Az NFS 4.1 használata funkcionális szempontból kötelező a /hana/data és a /hana/log kötetek esetében. Míg a /hana/megosztott kötet esetében az NFS v3 vagy az NFS v4.1 protokoll használható funkcionális szempontból.
Fontos tényezők
Az Sap Netweaverhez és az SAP HANA-hoz készült Azure NetApp Files megfontolásakor vegye figyelembe a következő fontos szempontokat:
A minimális kapacitáskészlet 4 TiB
A minimális kötetméret 100 GiB
Az ANF-alapú NFS-megosztásoknak és a megosztásokat csatlakoztató virtuális gépeknek ugyanabban az Azure-beli virtuális hálózatban vagy egy régióban lévő társhálózatban kell lenniük
A kijelölt virtuális hálózatnak rendelkeznie kell egy, az Azure NetApp Fileshoz delegált alhálózattal. AZ SAP számítási feladataihoz erősen ajánlott /25 tartományt konfigurálni az ANF-nek delegált alhálózathoz.
Fontos, hogy a virtuális gépek elegendő közelségben üzemeljenek az Azure NetApp Storage-hoz az alacsonyabb késés érdekében, mivel például az SAP HANA megköveteli a naplóírások újraírását.
- Az Azure NetApp Files mindeközben rendelkezik olyan funkciókkal, amelyek NFS-köteteket helyeznek üzembe adott Azure rendelkezésre állási zónákban. Az ilyen zonális közelség az esetek többségében elegendő lesz, hogy 1 ezredmásodpercnél kisebb késést érjen el. A funkció nyilvános előzetes verzióban érhető el, és az Azure NetApp Files rendelkezésre állási zónájának kötetelhelyezésének kezelése című cikkben ismertetjük. Ez a funkció nem igényel interaktív folyamatot a Microsofttal a virtuális gép és a lefoglalt NFS-kötetek közötti közelség eléréséhez.
- A lehető legoptimálisabb közelség érdekében elérhető az alkalmazáskötetcsoportok funkciója. Ez a funkció nem csak a legoptimálisabb közelségre törekszik, hanem az NFS-kötetek optimális elhelyezésére is, így a HANA-adatokat és a naplóköteteket különböző vezérlők kezelik. Ennek a módszernek a hátránya, hogy a Virtuális gépek rögzítéséhez a Microsoft interaktív folyamatra van szükség.
Győződjön meg arról, hogy az adatbázis-kiszolgáló és az ANF-kötet közötti késés mérése 1 ezredmásodperc alatt van
Az Azure NetApp-kötetek átviteli sebessége a kötetkvóta és a szolgáltatási szint függvénye, az Azure NetApp Files szolgáltatási szintjén dokumentálva. A HANA Azure NetApp-kötetek méretezésekor győződjön meg arról, hogy az eredményül kapott átviteli sebesség megfelel a HANA rendszerkövetelményeknek. Másik lehetőségként érdemes lehet manuális QoS-kapacitáskészletet használni, ahol a kötetkapacitás és az átviteli sebesség egymástól függetlenül konfigurálható és skálázható (ebben a dokumentumban SAP HANA-specifikus példák találhatók ).
Próbálja meg "összesíteni" a köteteket, hogy nagyobb teljesítményt érjen el egy nagyobb kötetben, például használjon egy kötetet a /sapmnt, /usr/sap/trans, ... ha lehetséges
Az Azure NetApp Files exportálási szabályzatot kínál: szabályozhatja az engedélyezett ügyfeleket, a hozzáférési típust (Olvasás és írás, Írás csak olvasás stb.).
Az sidadm felhasználói azonosítójának és a virtuális gépek csoportazonosítójának
sapsysmeg kell egyeznie az Azure NetApp Files konfigurációjával.Az SAP megjegyzésében említett Linux operációsrendszer-paraméterek implementálása 3024346
Fontos
Az SAP HANA számítási feladatinak esetében az alacsony késés kritikus fontosságú. A Microsoft-képviselővel együttműködve győződjön meg arról, hogy a virtuális gépek és az Azure NetApp Files-kötetek a közelben vannak üzembe helyezve.
Fontos
Ha a sidadm felhasználói azonosítója és a virtuális gép és az Azure NetApp konfigurációja közötti csoportazonosító sapsys nem egyezik, a virtuális géphez csatlakoztatott Azure NetApp-köteteken lévő fájlok engedélyeit a rendszer a következőképpen jeleníti megnobody. Az új rendszer Azure NetApp Filesba való beszálláskor mindenképpen adja meg a sidadm megfelelő felhasználói azonosítóját és csoportazonosítójátsapsys.
NCONNECT csatlakoztatási lehetőség
Az Nconnect az ANF-en üzemeltetett NFS-kötetek csatlakoztatási lehetősége, amely lehetővé teszi, hogy az NFS-ügyfél több munkamenetet nyisson meg egyetlen NFS-köteten. Az nconnect 1-nél nagyobb értékkel való használata esetén az NFS-ügyfél több RPC-munkamenetet is aktivál az ügyféloldalon (a vendég operációs rendszerben) a vendég operációs rendszer és a csatlakoztatott NFS-kötetek közötti forgalom kezelésére. Egy NFS-kötet forgalmát kezelő több munkamenet használata, de több RPC-munkamenet használata is képes kezelni a teljesítményt és az átviteli sebességet, például:
- Több ANF által üzemeltetett NFS-kötet csatlakoztatása különböző szolgáltatási szintekkel egy virtuális gépen
- Egy kötet és egyetlen Linux-munkamenet írási sebessége legfeljebb 1,2 és 1,4 GB/s között lehet. Ha több munkamenetet használ egy ANF által üzemeltetett NFS-köteten, az növelheti az átviteli sebességet
Az nconnect csatlakoztatási lehetőségként támogatott Linux operációsrendszer-kiadások és az nconnect néhány fontos konfigurációs szempontja– különösen a különböző NFS-kiszolgálóvégpontok esetében – olvassa el az Azure NetApp Files linuxos NFS csatlakoztatási beállításainak ajánlott eljárásait.
Méretezés HANA-adatbázishoz az Azure NetApp Filesban
Az Azure NetApp-kötetek átviteli sebessége az Azure NetApp Files szolgáltatásszintjeiben dokumentált kötetméret és szolgáltatási szint függvénye.
Fontos tisztában lenni a méret teljesítménybeli kapcsolatával, valamint azzal, hogy a szolgáltatás tárolási végpontjának fizikai korlátai vannak. Minden tárolási végpont dinamikusan lesz injektálva az Azure NetApp Files delegált alhálózatába a kötet létrehozásakor, és kap egy IP-címet. Az Azure NetApp Files-kötetek – az elérhető kapacitástól és az üzembe helyezési logikától függően – megoszthatnak egy tárolási végpontot
Az alábbi táblázat azt mutatja be, hogy érdemes lehet létrehozni egy nagy "Standard" kötetet a biztonsági másolatok tárolásához, és hogy nincs értelme 12 TB-nál nagyobb "Ultra" kötetet létrehozni, mert az egyetlen kötet maximális fizikai sávszélesség-kapacitása túllépné.
Ha a /hana/adatkötet maximális írási sebességénél többre van szüksége, mint amennyit egyetlen Linux-munkamenet biztosíthat, használhatja az SAP HANA adatkötet particionálását is alternatívaként. Az SAP HANA-adatkötet particionálása leválasztja az I/O-tevékenységet az adatok újrabetöltése vagy a HANA-mentési pontok több, több NFS-megosztáson található HANA-adatfájl között. A HANA adatkötet-csíkozásával kapcsolatos további részletekért olvassa el az alábbi cikkeket:
- A HANA Rendszergazda istrator útmutatója
- Blog az SAP HANA-ról – Adatkötetek particionálása
- SAP-megjegyzés #2400005
- SAP-megjegyzés #2700123
| Méret | Átviteli sebesség standard | Átviteli sebesség – Prémium | Átviteli sebesség ultra |
|---|---|---|---|
| 1 TB | 16 MB/s | 64 MB/s | 128 MB/s |
| 2 TB | 32 MB/s | 128 MB/s | 256 MB/s |
| 4 TB | 64 MB/s | 256 MB/s | 512 MB/s |
| 10 TB | 160 MB/s | 640 MB/s | 1280 MB/s |
| 15 TB | 240 MB/s | 960 MB/s | 1400 MB/mp1 |
| 20 TB | 320 MB/s | 1280 MB/s | 1400 MB/mp1 |
| 40 TB | 640 MB/s | 1400 MB/mp1 | 1400 MB/mp1 |
1: írási vagy egy munkamenetes olvasási átviteli sebességkorlátok (ha az NFS csatlakoztatási lehetőséget nem használja az nconnect)
Fontos tisztában lenni azzal, hogy az adatok ugyanazokra az SSD-kre lesznek írva a háttérrendszerben. A kapacitáskészletből származó teljesítménykvótát azért hozták létre, hogy kezelni lehessen a környezetet. A Storage KPI-k egyenlők az összes HANA-adatbázis méretével. Ez a feltételezés szinte minden esetben nem tükrözi a valóságot és az ügyfél elvárásait. A HANA-rendszerek mérete nem feltétlenül jelenti azt, hogy egy kis rendszer alacsony tárolási teljesítményt igényel – és egy nagy rendszer nagy tárolási teljesítményt igényel. A nagyobb HANA-adatbázispéldányok esetében azonban általában magasabb átviteli sebességre lehet számítani. Az SAP a mögöttes hardverre vonatkozó méretezési szabályainak köszönhetően az ilyen nagyobb HANA-példányok több CPU-erőforrást és nagyobb párhuzamosságot biztosítanak az olyan feladatokban, mint az adatok betöltése a példányok újraindítása után. Ennek eredményeképpen a mennyiségi méreteket az ügyfél elvárásainak és követelményeinek megfelelően kell alkalmazni. És nem csak a tiszta kapacitási követelmények vezérlik.
Az AZURE-beli SAP infrastruktúrájának megtervezése során tisztában kell lennie az SAP által előírt minimális tárolási átviteli sebességre vonatkozó követelményekkel (az éles rendszerek esetében). Ezek a követelmények a következők minimális átviteli sebességére vonatkoznak:
| Kötettípus és I/O-típus | Az SAP által igényelt minimális KPI | Prémium szolgáltatási szint | Ultra szolgáltatási szint |
|---|---|---|---|
| Naplókötet írása | 250 MB/s | 4 TB | 2 TB |
| Adatkötet írása | 250 MB/s | 4 TB | 2 TB |
| Adatkötet olvasása | 400 MB/s | 6,3 TB | 3.2 TB |
Mivel mindhárom KPI-t igényelni kell, a /hana/adatmennyiséget a nagyobb kapacitás felé kell méretezni a minimális olvasási követelmények teljesítéséhez. ha manuális QoS-kapacitáskészleteket használ, a kötetek mérete és átviteli sebessége egymástól függetlenül határozható meg. Mivel a kapacitás és az átviteli sebesség is ugyanabból a kapacitáskészletből származik, a készlet szolgáltatási szintjének és méretének elég nagynak kell lennie a teljes teljesítmény biztosításához (lásd itt a példát)
A nagy sávszélességet nem igénylő HANA-rendszerek esetében az ANF-kötet átviteli sebessége kisebb hangerővel vagy manuális QoS használatával csökkenthető közvetlenül az átviteli sebesség beállításával. Abban az esetben, ha egy HANA-rendszer nagyobb átviteli sebességet igényel, a kapacitás online átméretezésével adaptálható a kötet. A biztonsági mentési kötetekhez nincs meghatározva KPI. A biztonsági mentési kötet átviteli sebessége azonban elengedhetetlen egy jól teljesítő környezethez. A naplót és az adatmennyiség teljesítményét az ügyfél elvárásainak megfelelően kell megtervezni.
Fontos
Az egyetlen NFS-köteten üzembe helyezhető kapacitástól függetlenül az átviteli sebesség várhatóan 1,2–1,4 GB/s sávszélességet fog biztosítani, amelyet a fogyasztó egyetlen munkamenetben használ fel. Ennek az ANF-ajánlat mögöttes architektúrájával és a kapcsolódó Linux-munkamenetek NFS-sel kapcsolatos korlátaihoz kell köze. Az Azure NetApp Files teljesítménymutató-teszteredményei című cikkben dokumentált teljesítmény- és átviteli sebességszámokat egy megosztott NFS-köteten, több ügyfél virtuális géppel és több munkamenettel végezték. Ez a forgatókönyv eltér az SAP-ban mért forgatókönyvétől. Ahol egyetlen virtuális gép átviteli sebességét mérjük egy NFS-kötethez. Az ANF-en üzemeltetve.
Az SAP minimális átviteli sebességére vonatkozó követelményeknek való megfelelés érdekében az adatok és naplók esetében, valamint a /hana/shared irányelveinek megfelelően az ajánlott méretek a következőképpen néznek ki:
| Térfogat | Méret Prémium szintű tárolási szint |
Méret Ultra storage-szint |
Támogatott NFS-protokoll |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | v4.1 |
| /hana/megosztott felskálázás | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | v3 vagy v4.1 |
| /hana/megosztott vertikális felskálázás | 1 x RAM munkavégző csomópont négy feldolgozó csomópontonként |
1 x RAM munkavégző csomópont négy feldolgozó csomópontonként |
v3 vagy v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 vagy v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 vagy v4.1 |
Minden kötet esetében erősen ajánlott az NFS 4.1-s verzió.
Alaposan tekintse át a /hana/megosztott méretezés szempontjait, mivel a megfelelő méretű /hana/megosztott kötet hozzájárul a rendszer stabilitásához.
A biztonsági mentési kötetek mérete becslések. A pontos követelményeket a számítási feladatok és a műveleti folyamatok alapján kell meghatározni. Biztonsági mentések esetén a különböző SAP HANA-példányok számos kötetét összevonhatja egy (vagy két) nagyobb kötetre, amelyek alacsonyabb anf szolgáltatási szinttel rendelkezhetnek.
Feljegyzés
A dokumentumban ismertetett Méretezési javaslatok az Azure NetApp Files esetében azokat a minimális követelményeket célzják meg, amelyeket az SAP az infrastruktúra-szolgáltatók felé fejez ki. A valós ügyféltelepítésekben és számítási feladatokban ez nem feltétlenül elegendő. Használja ezeket a javaslatokat kiindulási pontként, és az adott számítási feladat követelményeinek megfelelően alkalmazkodjon.
Ezért érdemes lehet megfontolni az ANF-kötetek hasonló átviteli sebességének üzembe helyezését az Ultra Disk Storage esetében már felsoroltak szerint. Vegye figyelembe a különböző virtuálisgép-termékváltozatok köteteihez felsorolt méretek méretét is az Ultra lemeztáblákban már ismertetett módon.
Tipp.
Az Azure NetApp Files-köteteket dinamikusan, a kötetek nélkül unmount is átméretezheti, leállíthatja a virtuális gépeket, vagy leállíthatja az SAP HANA-t. Ez lehetővé teszi, hogy rugalmasan kielégítse az alkalmazást a várt és az előre nem látható átviteli sebességre vonatkozó követelményeknek is.
Az SAP HANA vertikális felskálázási konfigurációjának anf-alapú NFS v4.1-kötetekkel történő üzembe helyezésére vonatkozó dokumentációt az SAP HANA kibővített, készenléti csomóponttal rendelkező azure-beli virtuális gépeken, az Azure NetApp Files su-n Standard kiadás Linux Enterprise Serveren.
Linux kernel Gépház
Az SAP HANA ANF-en való sikeres üzembe helyezéséhez a Linux kernelbeállításokat az SAP megjegyzés 3024346 szerint kell implementálnunk.
Magas rendelkezésre állású (HA) pacemakert és Azure Load Balancert használó rendszerek esetén a következő beállításokat kell implementálnunk a /etc/sysctl.d/91-NetApp-HANA.conf fájlban
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
A pacemaker és az Azure Load Balancer nélkül futó rendszereknek ezeket a beállításokat a /etc/sysctl.d/91-NetApp-HANA.conf fájlban kell implementálniuk
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Üzembe helyezés zonális közelséggel
Az NFS-kötetek és virtuális gépek zonális közelségéhez kövesse az Azure NetApp Files rendelkezésre állási zónájának kötetelhelyezésének kezelése című témakör utasításait. Ezzel a módszerrel a virtuális gépek és az NFS-kötetek ugyanabban az Azure rendelkezésre állási zónában lesznek. Az Azure-régiók többségében az ilyen típusú közelségnek elegendőnek kell lennie ahhoz, hogy kevesebb mint 1 ezredmásodpercnél kisebb késést érjen el az SAP HANA-hoz készült kisebb újraműves naplóírások esetében. Ez a módszer nem igényel interaktív munkát a Microsofttal a virtuális gépek adott adatközpontba való elhelyezéséhez és rögzítéséhez. Ennek eredményeképpen rugalmasan módosíthatja a virtuális gépek méretét és családjait az üzembe helyezett rendelkezésre állási zónában kínált összes virtuálisgép-típuson és családon belül. Így rugalmasan reagálhat a chanign feltételekre, vagy gyorsabban válthat a költséghatékonyabb virtuálisgép-méretekre vagy -családokra. Ezt a módszert nem éles rendszerekhez és éles rendszerekhez ajánljuk, amelyek képesek az 1 ezredmásodperchez közelebbi redo log késésekkel dolgozni. A funkció jelenleg nyilvános előzetes verzióban érhető el.
Üzembe helyezés az Azure NetApp Files alkalmazáskötetcsoporton keresztül az SAP HANA-hoz (AVG)
A virtuális gép közelében lévő ANF-kötetek üzembe helyezéséhez egy új funkciót fejlesztettek ki az SAP HANA -hoz készült Azure NetApp Files alkalmazáskötetcsoport (AVG) néven. A funkciót több cikk is dokumentálja. A legjobb, ha az SAP HANA-hoz készült Azure NetApp Files-alkalmazáskötetcsoport ismertetése című cikkből indul ki. A cikkek elolvasása során nyilvánvalóvá válik, hogy az AVG-k használata magában foglalja az Azure közelségi elhelyezési csoportjainak használatát is. A közelségi elhelyezési csoportokat az új funkciók a létrehozott kötetekhez kötik. Annak érdekében, hogy a HANA-rendszer élettartama alatt a virtuális gépek ne legyenek elmozdulva az ANF-kötetektől, javasoljuk, hogy használja az Avset/PPG kombinációt az egyes zónákhoz, amelyekbe üzembe helyez. Az üzembe helyezés sorrendje a következőképpen nézne ki:
- Az űrlap használatával az üres AvSet rögzítését kell kérnie egy számítási HW-hez, hogy a virtuális gépek ne mozduljanak el
- PPG hozzárendelése a rendelkezésre állási csoporthoz, és az ehhez a rendelkezésre állási csoporthoz rendelt virtuális gép indítása
- HANA-kötetek üzembe helyezéséhez használja az Azure NetApp Files alkalmazáskötetcsoportját az SAP HANA-funkciókhoz
Az AVG-k optimális használatára vonatkozó közelségi elhelyezési csoport konfigurációja a következőképpen nézne ki:
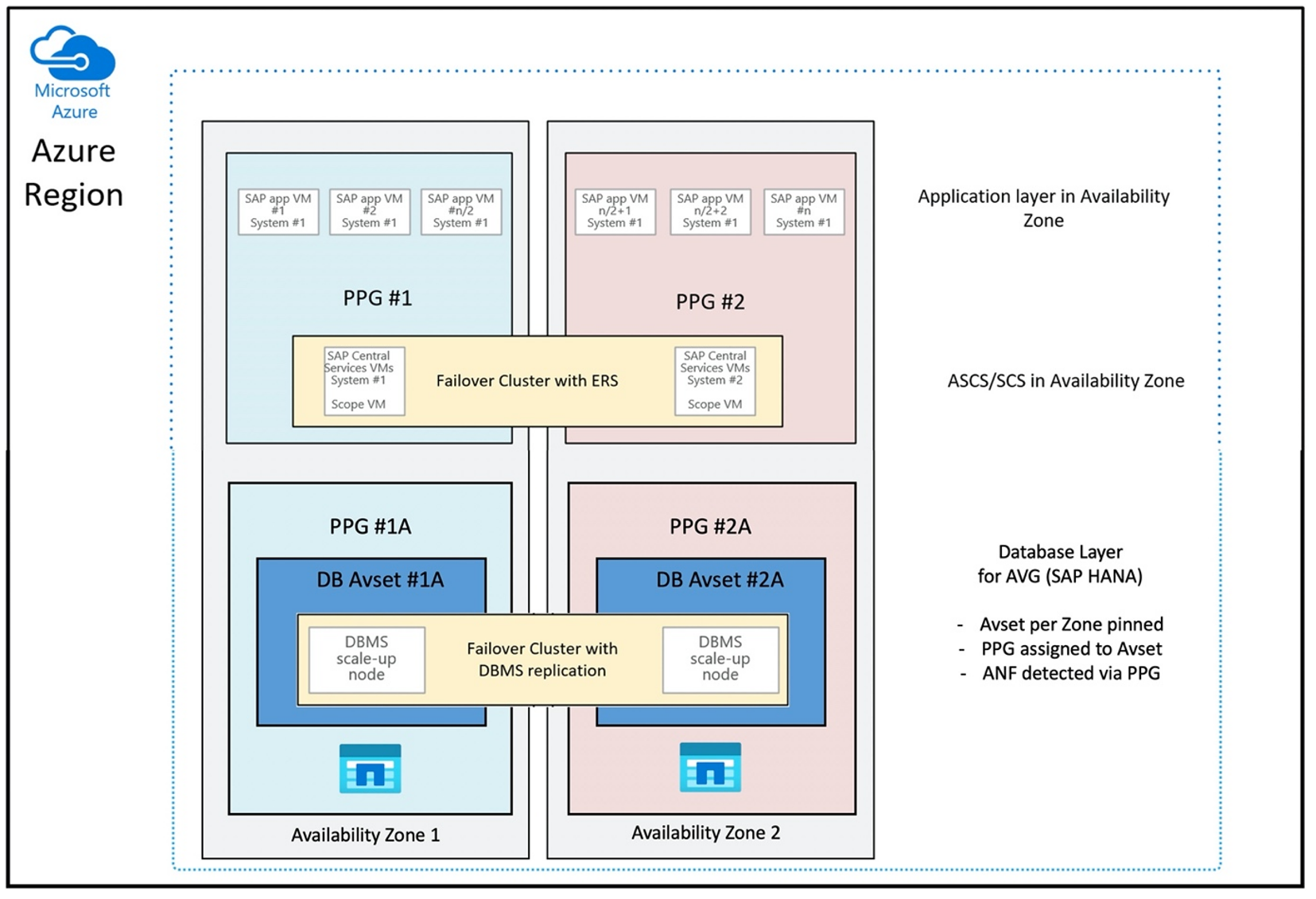
Az ábrán látható, hogy egy Azure-közelségi elhelyezési csoportot fog használni a DBMS-réteghez. Így együtt használhatja az AVG-kkel. A legjobb, ha csak azokat a virtuális gépeket tartalmazza, amelyek a HANA-példányokat futtatják a közelségi elhelyezési csoportban. A közelségi elhelyezési csoportra akkor is szükség van, ha csak egyetlen HANA-példánysal rendelkező virtuális gépet használ, hogy az AVG azonosítsa az ANF-hardver legközelebbi közelségét. Az NFS-kötet anf-en való lefoglalása a lehető legközelebb az NFS-köteteket használó virtuális gép(ek)hez.
Ez a módszer az alacsony késéssel kapcsolatos legoptimálisabb eredményeket hozza létre. Nem csak azzal, hogy az NFS-köteteket és virtuális gépeket a lehető legközelebb hozza egymáshoz. Figyelembe veszik azonban az adatok elhelyezésének és a naplók köteteinek a NetApp háttérrendszer különböző vezérlőire történő ismételt elküldésének szempontjait is. A hátránya azonban az, hogy a virtuális gép üzembe helyezése egy adatközpontba van rögzítve. Ezzel elveszíti a rugalmasságot a virtuálisgép-típusok és -családok módosításában. Ennek eredményeképpen korlátoznia kell ezt a módszert az olyan rendszerekre, amelyek feltétlenül ilyen alacsony tárolási késést igényelnek. Minden más rendszer esetében meg kell kísérelni az üzembe helyezést a virtuális gép és az ANF hagyományos zonális üzembe helyezésével. A legtöbb esetben ez az alacsony késés szempontjából elegendő. Ez a virtuális gép és az ANF egyszerű karbantartását és felügyeletét is biztosítja.
Elérhetőség
Az ANF rendszerfrissítései és frissítései az ügyfélkörnyezet befolyásolása nélkül kerülnek alkalmazásra. A definiált SLA 99,99%.
Kötetek és IP-címek és kapacitáskészletek
Az ANF használatával fontos tisztában lenni a mögöttes infrastruktúra felépítésével. A kapacitáskészletek csak olyan szerkezetek, amelyek kapacitás- és teljesítménykeretet és számlázási egységet biztosítanak a kapacitáskészlet szolgáltatási szintje alapján. A kapacitáskészletnek nincs fizikai kapcsolata a mögöttes infrastruktúrával. Amikor kötetet hoz létre a szolgáltatásban, létrejön egy tárolási végpont. Ehhez a tárvégponthoz egyetlen IP-cím van hozzárendelve, hogy adathozzáférést biztosítson a kötethez. Ha több kötetet hoz létre, az összes kötet el lesz osztva a mögöttes operációs rendszer nélküli flotta között, amely ehhez a tárolási végponthoz van kötve. Az ANF olyan logikával rendelkezik, amely automatikusan elosztja az ügyfél számítási feladatait, amint a konfigurált tárterület kötetei vagy/és kapacitása eléri a belső előre meghatározott szintet. Ilyen eseteket tapasztalhat, mert egy új, új IP-címmel rendelkező tárolási végpont automatikusan létrejön a kötetek eléréséhez. Az ANF szolgáltatás nem biztosítja az ügyfelek számára a terjesztési logika ellenőrzését.
Naplókötet és napló biztonsági mentési kötete
A "naplókötet" (/hana/log) az online ismétlési napló megírására szolgál. Így a kötetben nyitott fájlok találhatók, és nincs értelme pillanatképet készíteni a kötetről. Az online újradokolási naplófájlok archiválása vagy biztonsági mentése a napló biztonsági mentési kötetére történik, miután az online újradokolási naplófájl megtelt, vagy a naplók ismételt biztonsági mentésének végrehajtása megtörtént. Az ésszerű biztonsági mentési teljesítmény biztosításához a napló biztonsági mentési kötete jó átviteli sebességet igényel. A tárolási költségek optimalizálása érdekében érdemes összevonni több HANA-példány napló-biztonsági mentési kötetét. Így több HANA-példány is ugyanazt a kötetet használja, és a biztonsági másolatokat különböző könyvtárakba írja. Egy ilyen összevonással nagyobb átviteli sebességet érhet el, mivel a kötetet egy kicsit nagyobbra kell méreteznie.
Ugyanez vonatkozik arra a kötetre is, amelybe teljes HANA-adatbázis-biztonsági mentéseket ír.
Backup
A streamelési biztonsági mentések és az Azure Back service mellett, amely az SAP HANA-adatbázisok biztonsági mentéséről készít biztonsági másolatot az Azure-beli virtuális gépeken futó SAP HANA biztonsági mentési útmutatójában leírtak szerint, az Azure NetApp Files lehetővé teszi a tárolóalapú pillanatképek biztonsági mentését.
Az SAP HANA a következőket támogatja:
- Tárolóalapú pillanatképek biztonsági mentése egyetlen tárolórendszerhez SAP HANA 1.0 SPS7 és újabb verzióval
- Tárolóalapú pillanatkép-biztonsági mentés támogatása többadatbázis-tároló (MDC) HANA-környezetekhez egyetlen bérlővel sap HANA 2.0 SPS1 és újabb verzióval
- Tárolóalapú pillanatkép-biztonsági mentés támogatása több adatbázistárolós (MDC) HANA-környezethez több bérlővel az SAP HANA 2.0 SPS4 és újabb verzióval
A tárolóalapú pillanatképek biztonsági mentése egy egyszerű, négylépéses eljárás,
- HANA(belső) adatbázis pillanatképének létrehozása – olyan tevékenység, amit vagy eszközöket kell elvégeznie
- Az SAP HANA adatokat ír az adatfájlokba, hogy konzisztens állapotot hozzon létre a tárolón – a HANA ezt a lépést hana-pillanatkép létrehozásakor hajtja végre
- Pillanatkép létrehozása a /hana/adatköteten a tárterületen – ezt a lépést önnek vagy eszközeinek kell elvégeznie. Nincs szükség pillanatkép végrehajtására a /hana/log köteten
- Törölje a HANA (belső) adatbázis pillanatképét, és folytassa a normál műveletet – ezt a lépést vagy eszközöket kell elvégeznie
Figyelmeztetés
Az utolsó lépés kihagyása vagy az utolsó lépés sikertelen végrehajtása súlyos hatással van az SAP HANA memóriaigényére, és az SAP HANA leállásához vezethet
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Ez a pillanatkép-biztonsági mentési eljárás különböző módokon, különböző eszközökkel kezelhető. Ilyen például a GitHubon https://github.com/netapp/ntaphana elérhető "ntaphana_azure.py" Python-szkript. Ez egy mintakód, amely karbantartás és támogatás nélkül is elérhető.
Figyelemfelhívás
A pillanatképek önmagukban nem védett biztonsági másolatok, mivel ugyanazon a fizikai tárolón találhatók, mint a kötet, amelyről most készített pillanatképet. Naponta legalább egy pillanatképet kötelező "védeni" egy másik helyre. Ez ugyanabban a környezetben, egy távoli Azure-régióban vagy az Azure Blob Storage-ban is elvégezhető.
Rendelkezésre álló megoldások a tároló pillanatkép-alapú alkalmazáskonzisztens biztonsági mentéséhez:
- A Microsoft What is Azure-alkalmazás Consistent Snapshot eszköz egy parancssori eszköz, amely lehetővé teszi a külső adatbázisok adatvédelmet. Ez kezeli az összes vezénylést, amely ahhoz szükséges, hogy az adatbázisokat alkalmazáskonzisztens állapotba helyezze a tárolási pillanatkép készítése előtt. A tárolási pillanatkép készítése után az eszköz az adatbázisokat működési állapotba állítja vissza. Az AzAcSnap támogatja a nagy HANA-példányok és az Azure NetApp Files pillanatképalapú biztonsági mentéseit. további részletekért olvassa el a Azure-alkalmazás Konzisztens pillanatkép eszköz
- A Commvault biztonsági mentési termékeinek felhasználói számára egy másik lehetőség a Commvault IntelliSnap V.11.21 és újabb verziók. A Commvault ezen vagy újabb verziói támogatják az Azure NetApp Files pillanatkép-támogatását. A Commvault IntelliSnap 11.21 című cikk további információkat tartalmaz.
Pillanatkép biztonsági mentése az Azure Blob Storage használatával
Az Azure Blob Storage-ra való biztonsági mentés költséghatékony és gyors módszer az ANF-alapú HANA-adatbázistár pillanatképeinek biztonsági mentéséhez. A pillanatképek Azure Blob Storage-ba való mentéséhez előnyben részesíti az AzCopy eszközt. Töltse le az eszköz legújabb verzióját, és telepítse például abban a bin könyvtárban, ahol a GitHubról származó Python-szkript telepítve van. Töltse le a legújabb AzCopy eszközt:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
A legfejlettebb funkció a SYNC lehetőség. Ha a SYNC beállítást használja, az azcopy szinkronizálja a forrás- és a célkönyvtárat. A --delete-destination paraméter használata fontos. E paraméter nélkül az azcopy nem törli a fájlokat a célhelyen, és a céloldalon a hely kihasználtsága növekedne. Hozzon létre egy blokkblobtárolót az Azure Storage-fiókjában. Ezután hozza létre a blobtároló SAS-kulcsát, és szinkronizálja a pillanatképmappát az Azure Blob-tárolóval.
Ha például egy napi pillanatképet szinkronizálni kell az Azure Blob-tárolóval az adatok védelme érdekében. És csak egy pillanatképet kell megőrizni, az alábbi parancs használható.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Következő lépések
Olvassa el az alábbi cikket: