AZ SAP HANA rendelkezésre állása az Azure-régiók között
Ez a cikk az SAP HANA különböző Azure-régiók közötti rendelkezésre állásával kapcsolatos forgatókönyveket ismerteti. Az Azure-régiók közötti távolság miatt az SAP HANA több Azure-régióban való rendelkezésre állásának beállítása különleges szempontokat is magában foglal.
Miért érdemes több Azure-régióban üzembe helyezni?
Az Azure-régiókat gyakran nagy távolságok választják el egymástól. A geopolitikai régiótól függően az Azure-régiók közötti távolság több száz mérföld, vagy akár több ezer mérföld is lehet, például a Egyesült Államok. A távolság miatt a két különböző Azure-régióban üzembe helyezett eszközök közötti hálózati forgalom jelentős hálózati kerekítési késést tapasztal. A késés elég jelentős ahhoz, hogy kizárja a szinkron adatcserét két SAP HANA-példány között a tipikus SAP számítási feladatokban.
Másrészt a szervezeteknek gyakran van távolsági követelményük az elsődleges adatközpont helye és egy másodlagos adatközpont között. A távolsági követelmények segítenek a rendelkezésre állásban, ha egy természeti katasztrófa szélesebb földrajzi helyen történik. Ilyenek például a 2017 szeptemberében és októberében a Karib-térséget és Floridát sújtó hurrikánok. Előfordulhat, hogy a szervezetnek legalább minimális távolsági követelménye van. A legtöbb Azure-ügyfél esetében a minimális távolság meghatározásához meg kell terveznie az Azure-régiók közötti rendelkezésre állást. Mivel a két Azure-régió közötti távolság túl nagy a HANA szinkron replikációs mód használatához, az RTO- és RPO-követelmények kényszeríthetik a rendelkezésre állási konfigurációk üzembe helyezését egy régióban, majd kiegészítheti a második régióban lévő további üzembe helyezésekkel.
Ebben a forgatókönyvben egy másik szempont a feladatátvétel és az ügyfél átirányítása. A feltételezés az, hogy az SAP HANA-példányok közötti feladatátvétel két különböző Azure-régióban mindig manuális feladatátvétel. Mivel az SAP HANA rendszerreplikációs módja aszinkronra van állítva, lehetséges, hogy az elsődleges HANA-példányban lekötött adatok még nem jutottak el a másodlagos HANA-példányra. Ezért az automatikus feladatátvétel nem használható olyan konfigurációkhoz, ahol a replikáció aszinkron. A feladatátvételi gyakorlathoz hasonlóan a manuális vezérlésű feladatátvétel esetén is intézkedéseket kell hoznia annak biztosítására, hogy az elsődleges oldalon lévő összes lekötött adat a másodlagos példányra kerüljön, mielőtt manuálisan áttér a másik Azure-régióba.
Az Azure Virtual Network más IP-címtartományt használ. Az IP-címek a második Azure-régióban vannak üzembe helyezve. Ezért vagy módosítania kell az SAP HANA ügyfélkonfigurációját, vagy lehetőség szerint létre kell hoznia a névfeloldás módosításához szükséges lépéseket. Így a rendszer átirányítja az ügyfeleket az új másodlagos hely kiszolgálói IP-címére. További információ: AZ ÜGYFÉLkapcsolat helyreállítása az átvétel után című SAP-cikk.
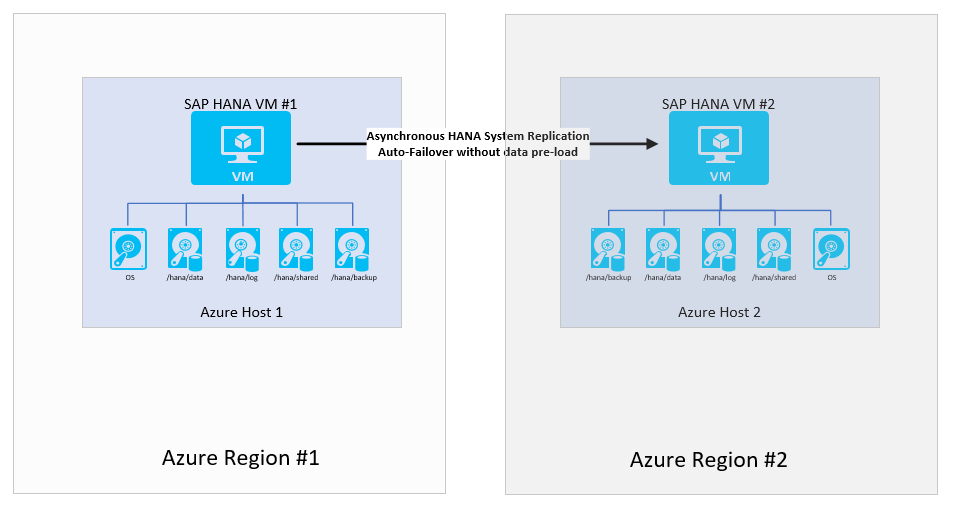
Egyszerű rendelkezésre állás két Azure-régió között
Dönthet úgy, hogy nem állít be rendelkezésre állási konfigurációt egyetlen régión belül, de továbbra is szüksége van a számítási feladat kiszolgálására katasztrófa esetén. Az ilyen forgatókönyvek tipikus esetei a nem gyártási rendszerek. Bár a rendszer leállása fél napra vagy akár egy napra is fenntartható, nem engedheti meg, hogy a rendszer 48 órán át vagy annál tovább elérhetetlen legyen. A telepítés költségesebbsé tétele érdekében futtasson egy másik rendszert, amely még kevésbé fontos a virtuális gépen. A másik rendszer célként működik. A másodlagos régióban lévő virtuális gépet kisebb méretre is méretezheti, és dönthet úgy, hogy nem szeretné előre betölteni az adatokat. Mivel a feladatátvétel manuális, és számos további lépéssel jár a teljes alkalmazásverem feladatátvétele, a virtuális gép leállításához, átméretezéséhez és újraindításához szükséges további idő elfogadható.
Ha a DR-cél egy minőségbiztosítási rendszerrel való megosztásának forgatókönyvét használja egy virtuális gépen, az alábbi szempontokat kell figyelembe vennie:
- A delta_datashipping és a logreplay két műveleti móddal rendelkezik, amelyek egy ilyen forgatókönyvhöz érhetők el
- Mindkét üzemmód eltérő memóriakövetelményekkel rendelkezik az adatok előzetes betöltése nélkül
- Delta_datashipping drasztikusan kevesebb memóriát igényelhet az előbetöltési beállítás nélkül, mint amennyit a logreplay megkövetelhet. Lásd az SAP-dokumentum 4.3. fejezetét: Rendszerreplikálás végrehajtása az SAP HANA-hoz
- Az előre betöltés nélküli logreplay üzemmód memóriakövetelménye nem determinisztikus, és a betöltött oszlopcentrikus struktúráktól függ. Szélsőséges esetekben az elsődleges példány memóriájának 50%-át igényelheti. A logreplay üzemmód memóriája független attól, hogy előre betöltötte-e az adatokat.
Megjegyzés:
Ebben a konfigurációban nem adhat meg RPO=0-t, mert a HANA-rendszer replikációs módja aszinkron. Ha RPO=0 értéket kell megadnia, ez a konfiguráció nem a választott konfiguráció.
A konfigurációban az adatok előzetes betöltésként való konfigurálása egy kis módosítás lehet. Azonban mivel a feladatátvétel manuális jellege és az alkalmazásrétegek a második régióba is áttérnek, nem feltétlenül érdemes előre betölteni az adatokat.
Rendelkezésre állás egyesítése egy régión belül és régiók között
A régiókon belüli és régiók közötti rendelkezésre állás kombinációját az alábbi tényezők vezérelhetik:
- Az RPO=0 követelménye egy Azure-régión belül.
- A szervezet nem hajlandó vagy nem képes globális műveleteket befolyásolni egy nagyobb régiót érintő jelentős természeti katasztrófa miatt. Ez volt a helyzet néhány hurrikánok, hogy sújtotta a Karib-térségben az elmúlt néhány évben.
- Olyan szabályozások, amelyek az elsődleges és a másodlagos helyek közötti távolságokat követelik meg, amelyek egyértelműen túllépik az Azure rendelkezésre állási zónák által biztosított távolságokat.
Ezekben az esetekben a HANA-rendszerreplikálás használatával beállíthatja, hogy az SAP mit hív SAP HANA többrétegű rendszerreplikációs konfigurációnak . Az architektúra a következőképpen nézne ki:
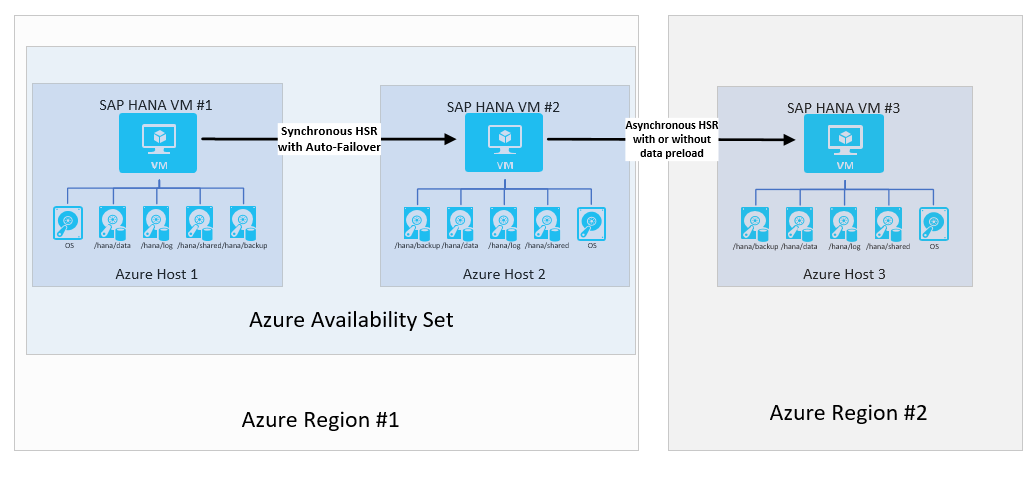
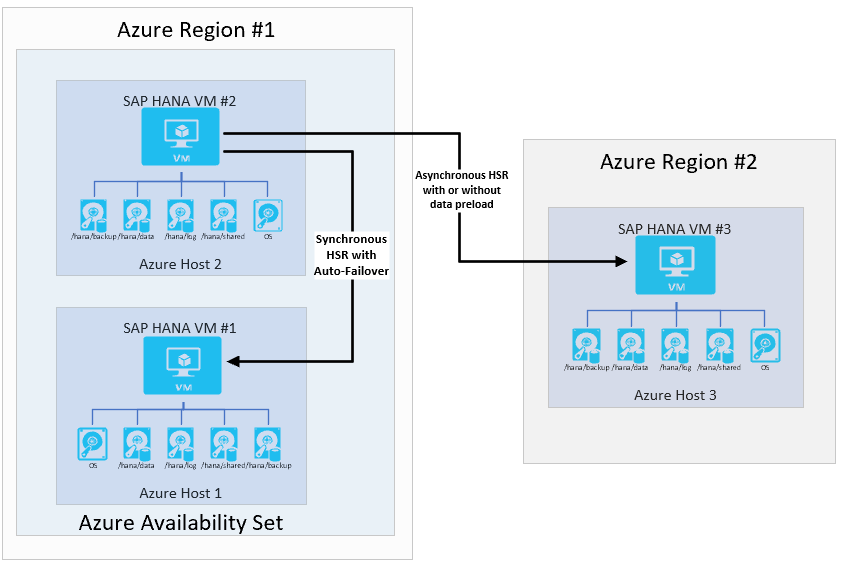
Az SAP többhelyes rendszerreplikációs rendszert vezetett be a HANA 2.0 SPS3 használatával. A többhelyes rendszerreplikációs szolgáltatás bizonyos előnyökkel jár a frissítési forgatókönyvekben. A DR-hely (2. régió) például nem lesz hatással, ha a másodlagos HA-hely karbantartás vagy frissítések miatt leállt. A TÖBBhelyes HANA-replikációról az SAP súgóportálján olvashat bővebben. A többhelyes replikációval rendelkező lehetséges architektúra a következőképpen nézne ki:
Ha a szervezetnek magas rendelkezésre állásra vonatkozó követelményei vannak a második (DR) Azure-régióban, az architektúra a következőképpen nézne ki:
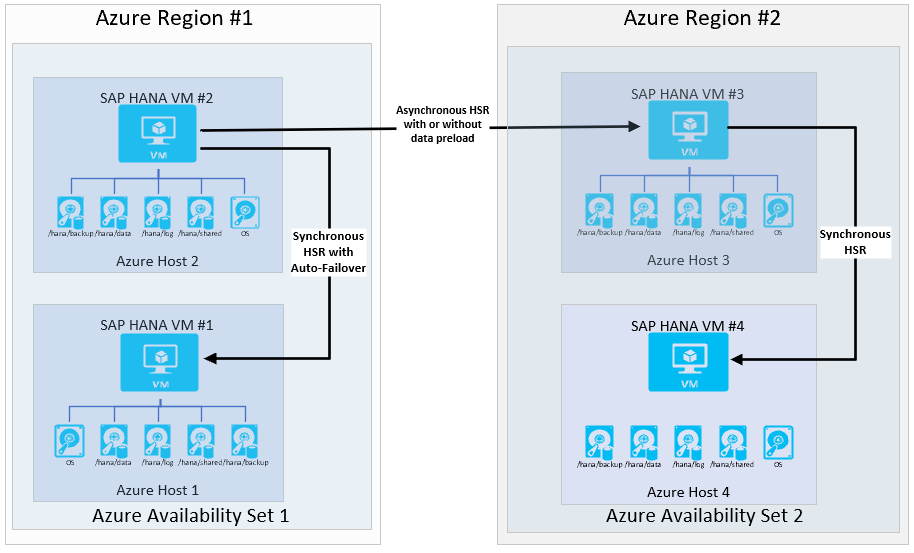
A logreplay műveleti módként való használatával ez a konfiguráció egy RPO=0,alacsony RTO-t biztosít az elsődleges régión belül. A konfiguráció megfelelő RPO-t is biztosít, ha a második régióba való áthelyezésről van szó. A második régió RTO-ideje attól függ, hogy az adatok előre vannak-e betöltve. Sok ügyfél a másodlagos régióban lévő virtuális gépet használja egy tesztrendszer futtatásához. Ebben a használati esetben az adatok nem tölthetők be előre.
Fontos
A különböző szintek közötti üzemeltetési módoknak homogénnek kell lenniük. A logreplay nem használható műveleti módként az 1. és a 2. réteg között, és delta_datashipping a 3. réteget. Csak azt az egyik vagy másik üzemmódot választhatja ki, amely minden szinten konzisztensnek kell lennie. Mivel delta_datashipping nem alkalmas RPO=0 használatára, az ilyen többrétegű konfigurációk egyetlen ésszerű működési módja továbbra is a logreplay marad. A műveleti módokkal és bizonyos korlátozásokkal kapcsolatos részletekért tekintse meg az SAP HANA-rendszerreplikációs sap-cikk működési módjait.
Következő lépések
A konfigurációk Azure-ban történő beállításával kapcsolatos részletes útmutatásért lásd: