Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A burkolással maximalizálhatja az alkalmazás gyorsítását. A burkolás egyenlő téglalap alakú részhalmazokra vagy csempékre osztja a szálakat. Ha a megfelelő csempeméretet és csempézett algoritmust használja, még nagyobb teljesítménynövekedést érhet el a C++ AMP-kóddal. A burkolás alapvető összetevői a következők:
tile_staticVáltozók. A burkolás legfőbb előnye atile_statichozzáférésből adódó teljesítményjavulás. A memóriában lévőtile_staticadatokhoz való hozzáférés jelentősen gyorsabb lehet, mint a globális térben (arrayvagyarray_viewobjektumokban) lévő adatokhoz való hozzáférés. Minden csempéhez létrejön egy változópéldánytile_static, és a csempe összes szála hozzáfér a változóhoz. Egy tipikus csempézett algoritmusban az adatokat egyszer bemásolják atile_staticmemóriába a globális memóriából, majd többször hozzáférnek atile_staticmemóriából.tile_barrier::wait metódus. A
tile_barrier::waithívás felfüggeszti az aktuális szál végrehajtását, amíg az adott táblán lévő összes szál el nem éri atile_barrier::waithívást. Nem garantálhatja a szálak futtatásának sorrendjét, csak azt, hogy a csempe egyetlen szála sem fog atile_barrier::waithívás után tovább futni, amíg az összes szál el nem éri a hívási pontot. Ez azt jelenti, hogy atile_barrier::waitmódszer használatával a feladatok végrehajtását csempénként, nem pedig szálonként végezheti el. Egy tipikus burkoló algoritmus először inicializálja atile_staticmemóriát a teljes csempe számára, majd meghívja atile_barrier::wait. Az alábbitile_barrier::waitkód olyan számításokat tartalmaz, amelyek minden értékhez hozzáférést igényelnektile_static.Helyi és globális indexelés. Hozzáféréssel rendelkezik a szál indexéhez a teljes
array_viewvagyarrayobjektumhoz viszonyítva, és az indexhez a csempéhez viszonyítva. A helyi index használata megkönnyíti a kód olvasását és hibakeresését. Általában helyi indexelést használ a változók eléréséheztile_static, a globális indexelést pedig a hozzáféréshezarrayésarray_viewa változókhoz.tiled_extent osztály és tiled_index osztály. A
tiled_extenthívásbanextentobjektumot használparallel_for_eachobjektum helyett. Atiled_indexhívásbanindexobjektumot használparallel_for_eachobjektum helyett.
A burkolás előnyeinek kihasználásához az algoritmusnak csempékre kell particionolnia a számítási tartományt, majd a csempeadatokat változókba tile_static kell másolnia a gyorsabb hozzáférés érdekében.
Példa a globális, a csempe és a helyi indexekre
Megjegyzés:
A C++ AMP fejlécek elavultak a Visual Studio 2022 17.0-s verziójától kezdve.
Az AMP-fejlécek beépítése építési hibákat fog okozni. A figyelmeztetések elnémításához a _SILENCE_AMP_DEPRECATION_WARNINGS definiálása előtt az AMP-fejléceket be kell vonni.
Az alábbi diagram egy 8x9-et ábrázoló adatmátrixot jelöl, amely 2x3 csempékbe van rendezve.
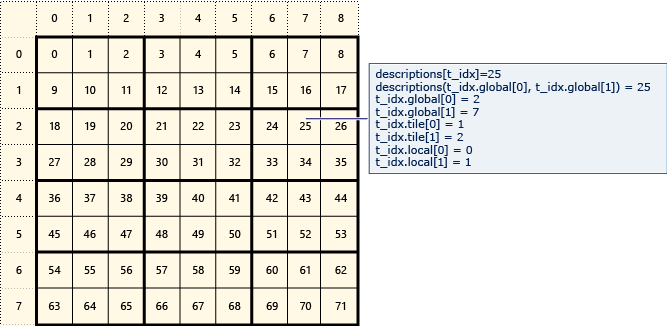
Az alábbi példa a csempézett mátrix globális, csempe- és helyi indexeit jeleníti meg. Az array_view objektumot a rendszer a típuselemekkel Descriptionhozza létre. A Description mátrix elemének globális, csempe- és helyi indexeit tartalmazza. A hívásban parallel_for_each szereplő kód az egyes elemek globális, csempe- és helyi indexeinek értékeit állítja be. A kimenet megjeleníti a struktúrák értékeit Description .
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
A példa fő munkája az objektum array_view meghatározása és a parallel_for_each hívása.
A struktúrák vektorát
Descriptionegy 8x9-objektumbaarray_viewmásolja a rendszer.A
parallel_for_eachmetódus számítási tartományként egytiled_extentobjektummal van meghívva. Atiled_extentobjektum aextent::tile()változódescriptionsmetódusának meghívásával jön létre. A hívásextent::tile()<2,3>típusparaméterei 2x3 csempét hoznak létre. Így a 8x9-es mátrix 12 csempére, négy sorra és három oszlopra van felosztva.Egy
parallel_for_eachobjektum (tiled_index<2,3>) indexének használatával hívjuk meg at_idxmetódust. Az index (t_idx) típusparamétereinek meg kell egyeznie a számítási tartomány (descriptions.extent.tile< 2, 3>()) típusparaméterével.Az egyes szálak végrehajtásakor az index
t_idxinformációt ad vissza arról, hogy melyik csempén található a szál (tiled_index::tiletulajdonság), valamint a szál helyét a csempén belül (tiled_index::localtulajdonság).
Csempeszinkronizálás – tile_static és tile_barrier::wait
Az előző példa a csempe elrendezését és indexeit szemlélteti, de önmagában nem túl hasznos. A burkolás akkor válik hasznossá, ha a csempék az algoritmus szerves részét képezik, és kihasználják tile_static a változókat. Mivel a csempén belül minden szálnak hozzáférése van a tile_static változókhoz, a tile_barrier::wait hívásokat arra használják, hogy szinkronizálják a hozzáférést a tile_static változókhoz. Bár a csempék összes szála hozzáfér a tile_static változókhoz, a csempén nincs garantált végrehajtási sorrend. Az alábbi példa bemutatja, hogyan használható tile_static változók és az tile_barrier::wait egyes csempék átlagértékének kiszámítására szolgáló módszer. A példa megértéséhez az alábbi kulcsok szükségesek:
A rawData egy 8x8-os mátrixban van tárolva.
A csempe mérete 2x2. Ez létrehoz egy 4x4-alapú csempékből álló rácsot, és az átlagok egy 4x4-alapú mátrixban tárolhatók egy
arrayobjektum használatával. Az AMP-korlátozott függvényekben csak korlátozott számú típust rögzíthet hivatkozással. Azarrayosztály az egyik.A mátrix mérete és mintamérete a
#defineutasítások használatával van meghatározva, mivel aarray,array_view,extentéstiled_indextípusparaméterek állandó értékeknek kell lenniük. A deklarációt is használhatjaconst int static. További előnyként a mintaméret módosítása a 4x4-es csempék átlagának kiszámításához egyszerű.Minden
tile_staticcsempéhez 2x2 lebegőpontos értéktömb van deklarálva. Bár a deklaráció minden szál kódútvonalában szerepel, a mátrix minden csempéjére csak egy tömb jön létre.Az egyes csempék értékeit egy kódsor másolja a
tile_statictömbbe. Minden szál esetében, miután az értéket átmásolta a tömbbe, a szálon a végrehajtás leáll a hívástile_barrier::waitmiatt.Ha egy csempe összes szála elérte a korlátot, az átlag kiszámítható. Mivel a kód minden szálra végrehajtva van, van egy
ifutasítás, amely csak egy szál átlagát számítja ki. Az átlag az átlag változóban van tárolva. Az akadály lényegében az a szerkezet, amely a számításokat csempék szerint szabályozza, hasonlóan ahhoz, mint amikorforciklust használunk.A változóban lévő
averagesadatokat, mivel ez egyarrayobjektum, vissza kell másolni a gazdagépre. Ez a példa a vektorkonvertálási operátort használja.A teljes példában a SAMPLESIZE értékét 4-re módosíthatja, és a kód megfelelően fut, más módosítások nélkül.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Versenyfeltételek
Csábító lehet létrehozni egy tile_static változót, amelyet total néven nevezünk el, és minden szálhoz növeljük ezt a változót, például így:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Ezzel a megközelítéssel az első probléma az, hogy tile_static a változók nem rendelkeznek inicializálókkal. A második probléma az, hogy van egy versenyfeltétel az total értékadásánál, mert a csempe összes szála bármely sorrendben hozzáférhet a változóhoz. Úgy is programozhatsz egy algoritmust, hogy a szálak közül csak egy férhessen hozzá az összegzéshez az egyes korlátoknál, ahogyan a következő példában látható. Ez a megoldás azonban nem bővíthető.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Memóriakerítések
Kétféle memóriahozzáférést kell szinkronizálni: a globális memóriahozzáférést és a tile_static memóriahozzáférést. Egy concurrency::array objektum csak globális memóriát foglal le. A concurrency::array_view globális memóriára, tile_static memóriára vagy mindkettőre hivatkozhat, attól függően, hogy hogyan lett létrehozva. Kétféle memóriát kell szinkronizálni:
globális memória
tile_static
A memóriakerítés biztosítja, hogy a szálcsempe más szálai számára is elérhetők legyenek a memóriahozzáférések, és hogy a memóriahozzáférések a program sorrendje szerint legyenek végrehajtva. Ennek biztosítása érdekében a fordítók és a processzorok nem újrendezik az olvasásokat és írásokat a memóriagáton. A C++ AMP-ben egy memóriakerítést az alábbi módszerek egyikének hívása hoz létre:
tile_barrier::wait metódus: Kerítést hoz létre a globális és a
tile_staticmemória körül.tile_barrier::wait_with_all_memory_fence metódus: Korlátot hoz létre mind a globális, mind a
tile_staticmemória körül.tile_barrier::wait_with_global_memory_fence metódus: Csak a globális memória körül hoz létre memória korlátot.
tile_barrier::wait_with_tile_static_memory_fence metódus: Kerítést hoz létre csak
tile_statica memória körül.
Ha meghívja a kívánt kerítést, az javíthatja az alkalmazás teljesítményét. A sorompó típusa befolyásolja, hogyan rendezi át a fordító és a hardver az utasításokat. Ha például globális memóriakerítést használ, az csak a globális memóriahozzáférésekre vonatkozik, ezért előfordulhat, hogy a fordító és a hardver a kerítés két oldalán lévő változókra tile_static átrendezi az olvasást és az írást.
A következő példában az akadály szinkronizálja az írásokat egy tileValues változóvaltile_static. Ebben a példában a tile_barrier::wait_with_tile_static_memory_fence kerül meghívásra a tile_barrier::wait helyett.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Lásd még
C++ AMP (C++ gyorsított masszív párhuzamosság)
tile_static kulcsszó