Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk bemutatja, hogyan teszi lehetővé a beolvasással bővített generáció, hogy az LLM-ek betanítás nélkül, tudásként kezeljék az adatforrásokat.
Az LLM-eknek számos tudásbázis van a betanításon keresztül. A legtöbb forgatókönyv esetében kiválaszthatja a követelményeknek megfelelő LLM-et, de ezek az LLM-eknek továbbra is további betanításra van szükségük az adott adatok megértéséhez. A visszakereséssel bővített generáció lehetővé teszi, hogy adatai elérhetők legyenek az LLM-ek számára anélkül, hogy először be kellene tanítani őket ezekre.
A RAG működése
A keresés-alapú generáció végrehajtásához beágyazott reprezentációkat kell létrehoznia az adataihoz, valamint az ezekkel kapcsolatos gyakori kérdéseket. Ezt menet közben is megteheti, vagy vektoradatbázis-megoldással hozhatja létre és tárolhatja a beágyazásokat.
Amikor egy felhasználó kérdést tesz fel, az LLM a beágyazásokkal hasonlítja össze a felhasználó kérdését az adataival, és megkeresi a legrelevánsabb környezetet. Ez a környezet és a felhasználó kérdése ezután egy promptként kerül az LLM-hez, amely az Ön adatai alapján ad választ.
Alapszintű RAG-folyamat
A RAG végrehajtásához minden olyan adatforrást fel kell dolgoznia, amelyet használni szeretne a lekérdezésekhez. Az alapfolyamat a következő:
- Nagy mennyiségű adatot kezelhető darabokra bontsunk.
- Konvertálja az adattömböket kereshető formátumba.
- A konvertált adatokat olyan helyen tárolja, amely lehetővé teszi a hatékony hozzáférést. Emellett fontos az idézetek vagy hivatkozások releváns metaadatainak tárolása, amikor az LLM választ ad.
- A konvertált adatok betáplálása az LLM-ekre a parancssorokban.
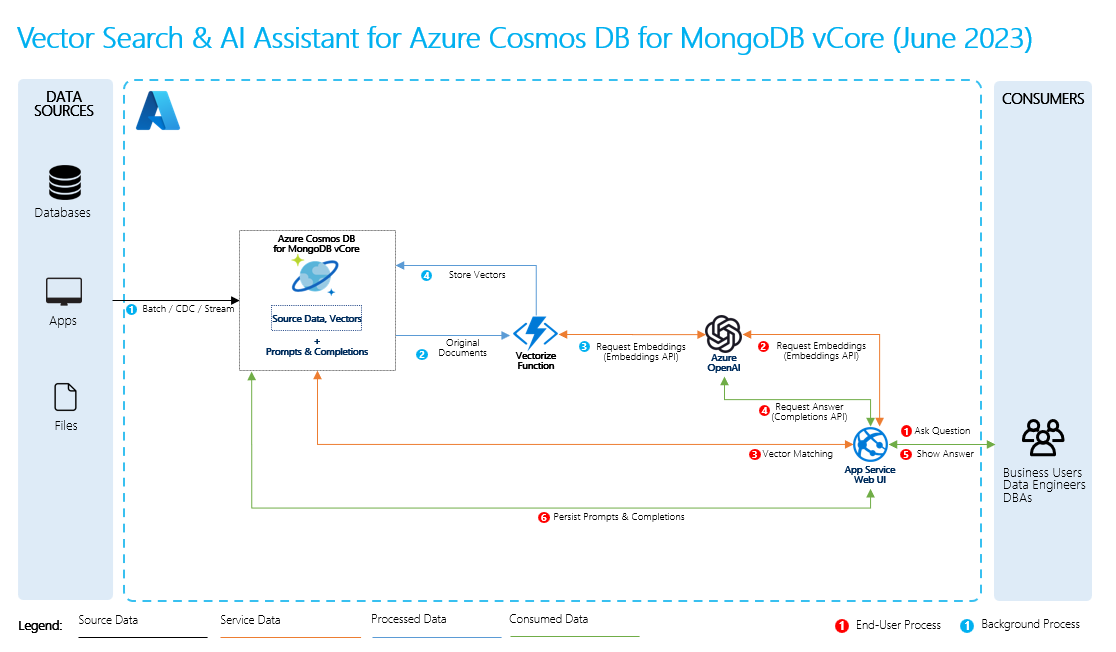
- Forrásadatok: Itt találhatók az adatok. Ez lehet egy fájl/mappa a számítógépen, egy felhőbeli tárolóban lévő fájl, egy Azure Machine Learning-adategység, egy Git-adattár vagy egy SQL-adatbázis.
- Adattömb: A forrásban lévő adatokat egyszerű szöveggé kell konvertálni. A word-dokumentumokat vagy PDF-fájlokat például meg kell nyitni, és szöveggé kell konvertálni. A szöveg ezután kisebb darabokra van osztva.
- A szöveg vektorokká alakítása: Ezek beágyazások. A vektorok a fogalmak számsorozatokká alakított numerikus ábrázolásai, amelyek megkönnyítik a számítógépek számára a fogalmak közötti kapcsolatok megértését.
- Hivatkozások a forrásadatok és a beágyazások között: Ezeket az információkat a rendszer metaadatként tárolja a létrehozott adattömbökben, amelyek aztán a válaszok generálása során segítenek az LLM-eknek idézeteket létrehozni.
Kapcsolódó tartalom
Dolgozzon együtt velünk a GitHubon
A tartalom forrása a GitHubon található, ahol létrehozhat és áttekinthet problémákat és lekéréses kérelmeket is. További információért tekintse meg a közreműködői útmutatónkat.