Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Megtudhatja, hogyan taníthat be egyéni mélytanulási modellt a transfer learning, egy előre betanított TensorFlow-modell és a ML.NET Képbesorolási API használatával, a betonfelületek lemezképeinek repedtként vagy fel nem vettként való besorolásához.
Ebben az oktatóanyagban a következőket sajátíthatja el:
- A probléma ismertetése
- Tudnivalók a ML.NET Képosztályozási API-ról
- Az előre betanított modell ismertetése
- Átviteltanulás használata egyéni TensorFlow-rendszerkép-besorolási modell betanításához
- Képek osztályozása az egyéni modellel
Előfeltételek
- Visual Studio 2022 vagy újabb verzió.
A probléma ismertetése
A képbesorolás számítógépes látási probléma. A képbesorolás bemenetként veszi fel a képet, és kategorizálja azt egy előírt osztályba. A képbesorolási modelleket általában mélytanulási és neurális hálózatok használatával tanítják be. További információ: Mély tanulás és gépi tanulás.
Néhány olyan forgatókönyv, ahol a képbesorolás hasznos:
- Arcfelismerés
- Érzelemészlelés
- Orvosi diagnózis
- Jellegzetesség észlelése
Ez az oktatóanyag betanított egy egyéni képbesorolási modellt a hídfedélzetek automatikus vizuális ellenőrzésére a repedések által sérült struktúrák azonosításához.
ML.NET Képbesorolási API
ML.NET a képbesorolás különböző módjait kínálja. Ez az oktatóanyag az Image Classification API használatával alkalmazza a transzfertanulást. A Képbesorolási API a TensorFlow.NET, egy alacsony szintű kódtárat használ, amely C#-kötéseket biztosít a TensorFlow C++ API-hoz.
Mi az a tudásátadás?
A tanulás átadása az egyik probléma megoldásából származó tudást egy másik kapcsolódó problémára alkalmazza.
A mélytanulási modell alapoktól való betanításához több paramétert, nagy mennyiségű címkézett betanítási adatot és nagy mennyiségű számítási erőforrást (több száz GPU-órát) kell beállítani. Az előre betanított modell és a transzfertanulás használata lehetővé teszi a betanítási folyamat gyorsítását.
Betanítási folyamat
A Képbesorolási API egy előre betanított TensorFlow-modell betöltésével indítja el a betanítási folyamatot. A betanítási folyamat két lépésből áll:
- Szűk keresztmetszeti fázis.
- Betanítási fázis.
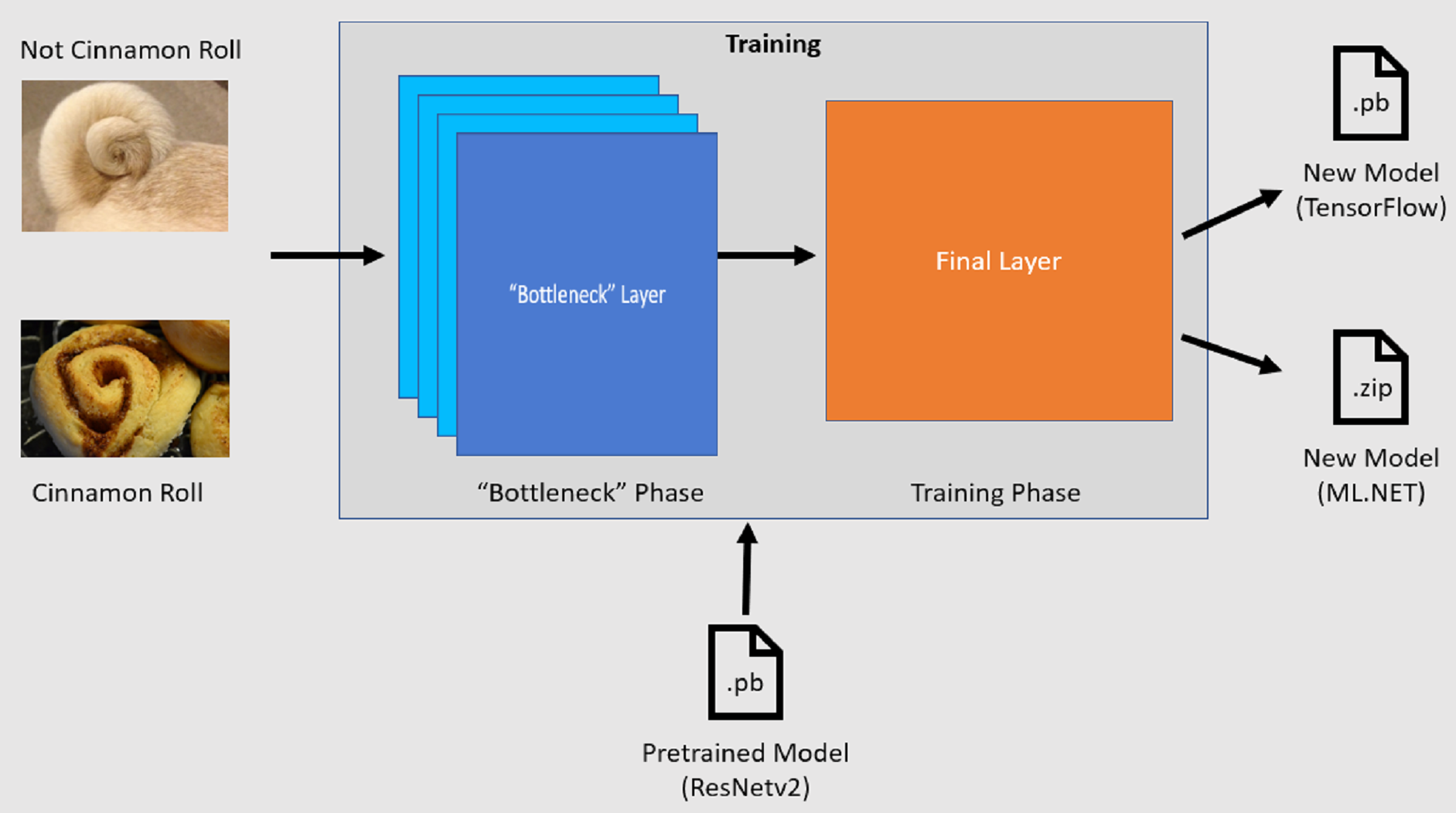
Szűk keresztmetszet fázis
A szűk keresztmetszeti fázisban a rendszer betölti a betanítási képek készletét, és a képpontértékeket használja bemenetként vagy jellemzőként az előre betanított modell fix rétegeihez. A fagyasztott rétegek magukban foglalják a neurális hálózat összes rétegét az utolsó előtti rétegig, ismertebb nevén a szűk keresztmetszeti réteg néven. Ezeket a rétegeket fagyasztottnak nevezzük, mert ezeken a rétegeken nem történik betanítás, és a műveletek átmennek. Ezekben a befagyott rétegekben vannak kiszámítva az alacsonyabb szintű minták, amelyek segítenek a modelleknek különbséget tenni a különböző osztályok között. Minél nagyobb a rétegek száma, annál nagyobb számítási igényű ez a lépés. Szerencsére, mivel ez egy egyszeri számítás, az eredmények gyorsítótárazhatók és felhasználhatók a későbbi futtatásokban, amikor különböző paraméterekkel kísérleteznek.
Betanítási fázis
A szűk keresztmetszeti fázis kimeneti értékeinek kiszámítása után a rendszer bemenetként használja őket a modell utolsó rétegének újratanításához. Ez a folyamat iteratív, és a modellparaméterek által megadott számú alkalommal fut. Minden futtatás során a rendszer kiértékeli a veszteséget és a pontosságot. Ezután a megfelelő módosításokat hajtjuk végre a modell javítása érdekében a veszteség minimalizálása és a pontosság maximalizálása érdekében. A betanítás befejezése után két modellformátum lesz kimenet. Az egyik a .pb modell verziója, a másik pedig a .zip modell ML.NET szerializált verziója. Ha ML.NET által támogatott környezetekben dolgozik, javasoljuk, hogy a .zip modell verzióját használja. Azokban a környezetekben azonban, ahol a ML.NET nem támogatott, lehetősége van a .pb verzió használatára.
Az előre betanított modell ismertetése
Az oktatóanyagban használt előre betanított modell a ResNet v2 modell 101 rétegű változata. Az eredeti modell be van tanítva, hogy a képeket ezer kategóriába sorolja. A modell bemenetként egy 224 x 224-es méretű képet vesz fel, és a betanított osztályok osztály-valószínűségeit adja ki. Ennek a modellnek egy részét arra használják, hogy egy új modellt képezzenek ki egyedi képek felhasználásával, és így előrejelzéseket készítsenek két osztály között.
Konzolalkalmazás létrehozása
Most, hogy általános ismereteket szerezhet a transzfertanulásról és a Képbesorolási API-ról, ideje létrehozni az alkalmazást.
Hozzon létre egy "DeepLearning_ImageClassification_Binary" nevű C# -konzolalkalmazást . Kattintson a Tovább gombra.
Válassza a .NET 8-at a használni kívánt keretrendszerként, majd válassza a Létrehozás lehetőséget.
Telepítse a Microsoft.ML NuGet-csomagot:
Megjegyzés
Ez a minta az említett NuGet-csomagok legújabb stabil verzióját használja, hacsak másként nem rendelkezik.
- A Megoldáskezelőben kattintson a jobb gombbal a projektre, és válassza a NuGet-csomagok kezeléselehetőséget.
- Válassza a "nuget.org" lehetőséget a Csomag forrásaként.
- Válassza a Tallózás lapot.
- Jelölje be az Include prerelease (Előzetes befoglalás) jelölőnégyzetet.
- Keresse meg a Microsoft.ML.
- Válassza a Telepítés gombot.
- Ha elfogadja a felsorolt csomagok licencfeltételét, válassza az Elfogadom gombot a Licenc elfogadása párbeszédpanelen.
- Ismételje meg ezeket a lépéseket a Microsoft.ML.Vision, a SciSharp.TensorFlow.Redist (2.3.1-es verzió) és a Microsoft.ML.ImageAnalytics NuGet-csomagok esetében.
Az adatok előkészítése és értelmezése
Megjegyzés
Az oktatóanyaghoz tartozó adatkészletek Maguire, Marc; Dorafshan, Sattar; és Thomas, Robert J. "SDNET2018: Egy betonrepedés képadatkészlet gépi tanulási alkalmazásokhoz" (2018) származnak. Tallózás az összes adatkészlet között. Papír 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 egy képadatkészlet, amely széljegyzeteket tartalmaz repedezett és nem repedezett betonszerkezetekhez (hídfedések, falak és járda).

Az adatok három alkönyvtárban lesznek rendszerezve:
- A D hídfedélzeti képeket tartalmaz
- P járdaképeket tartalmaz
- A W faliképeket tartalmaz
Ezek az alkönyvtárak két további előtagú alkönyvtárat tartalmaznak:
- C a repedezett felületekhez használt előtag
- U a törésmentes felületekhez használt előtag
Ebben az oktatóanyagban csak hídfedélzeti rendszerképeket használunk.
- Töltse le az adathalmazt, és bontsa ki.
- Hozzon létre egy "Assets" nevű könyvtárat a projektben az adathalmazfájlok mentéséhez.
- Másolja a CD- és UD-alkönyvtárakat a nemrég kicsomagolt könyvtárból az Assets könyvtárba.
Bemeneti és kimeneti osztályok létrehozása
Nyissa meg a Program.cs fájlt, és cserélje le a meglévő tartalmat a következő
usingirányelvekre:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Hozzon létre egy .
ImageDataEz az osztály az eredetileg betöltött adatok megjelenítésére szolgál.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDataa következő tulajdonságokat tartalmazza:-
ImagePatha teljesen kvalifikált elérési út, ahol a képfájl tárolva van. -
Labelaz a kategória, amelyhez a kép tartozik. Ezt az értéket kell előrejelezni.
-
Osztályokat hozhat létre a bemeneti és kimeneti adatokhoz.
ImageDataAz osztály alatt definiálja a bemeneti adatok sémáját egy új, úgynevezettModelInputosztályban.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputa következő tulajdonságokat tartalmazza:-
Imageabyte[]kép ábrázolása. A modell elvárja, hogy a képadatok ilyen típusúak legyenek a betanításhoz. -
LabelAsKeyaLabelszámszerű ábrázolása. -
ImagePatha teljesen kvalifikált elérési út, ahol a képfájl tárolva van. -
Labelaz a kategória, amelyhez a kép tartozik. Ezt az értéket kell előrejelezni.
Csak
ImageésLabelAsKeykerülnek felhasználásra a modell betanításához és az előrejelzések készítéséhez. AzImagePathésLabeltulajdonságok megmaradnak, hogy kényelmesen elérhessük az eredeti képfájl nevét és kategóriáját.-
Ezután az
ModelInputosztály alatt definiálja a kimeneti adatok sémáját egy új, úgynevezettModelOutputosztályban.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputa következő tulajdonságokat tartalmazza:-
ImagePatha teljesen kvalifikált elérési út, ahol a képfájl tárolva van. -
Labelaz az eredeti kategória, amelyhez a kép tartozik. Ezt az értéket kell előrejelezni. -
PredictedLabela modell által előrejelzett érték.
ModelInputEhhez hasonlóan csak azPredictedLabelelőrejelzések készítéséhez szükséges, mivel a modell által készített előrejelzést tartalmazza. AzImagePathésLabeltulajdonságokat a rendszer megőrzi, hogy könnyebben hozzáférhessen az eredeti képfájl nevéhez és kategóriájához.-
Elérési utak definiálása és változók inicializálása
usingAz utasítások alatt adja hozzá a következő kódot:Határozza meg az eszközök helyét.
Inicializálja a
mlContextváltozót az MLContext új példányával.Az MLContext osztály az összes ML.NET művelet kiindulópontja, és az mlContext inicializálása új ML.NET környezetet hoz létre, amely megosztható a modelllétrehozási munkafolyamat-objektumok között. Ez fogalmilag hasonlít az Entity Frameworkben lévő
DbContext-ra.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Adatok betöltése
Adatbetöltési segédprogram létrehozása
A rendszer két alkönyvtárban tárolja a képeket. Az adatok betöltése előtt az objektumokat egy objektumlistába ImageData kell formázni. Ehhez hozza létre a metódust LoadImagesFromDirectory :
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
A LoadImagesFromDirectory módszer:
- Lekéri az összes fájl elérési útját az alkönyvtárakból.
- Egy utasítással
foreachvégigvezeti az egyes fájlokat, és ellenőrzi, hogy a fájlkiterjesztések támogatottak-e. A Képbesorolási API támogatja a JPEG- és PNG-formátumokat. - Lekéri a fájl címkéjét. Ha a
useFolderNameAsLabelparaméter értéke a következő,trueakkor a rendszer a szülőkönyvtárat használja címkeként, amelyben a fájl mentésre kerül. Ellenkező esetben arra számít, hogy a címke a fájlnév vagy maga a fájlnév előtagja lesz. - Létrehoz egy új példányt a
ModelInput.
Az adatok előkészítése
Adja hozzá a következő kódot ahhoz a sorhoz, amelyben létrehozza az új MLContext példányt.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
Az előző kód:
Meghívja a
LoadImagesFromDirectorysegédprogram metódust, hogy lekérje a betanításhoz használt képek listáját a változó inicializálásamlContextután.Betölti a képeket egy
IDataViewelembe aLoadFromEnumerablemetódus használatával.A metódus használatával elkeveri az
ShuffleRowsadatokat. Az adatok betöltése a könyvtárakból beolvasott sorrendben történik. A keverést a kiegyensúlyozás érdekében hajtják végre.A betanítás előtt végez némi előfeldolgozást az adatokon. Ez azért van így, mert a gépi tanulási modellek numerikus formátumban várják a bemenetet. Az előfeldolgozási kód egy
EstimatorChain-t hoz létre, amely aMapValueToKeyésLoadRawImageBytesátalakításokból áll. AzMapValueToKeyátalakítás az oszlop kategorikus értékétLabelveszi át, numerikusKeyTypeértékké alakítja, és egy új, úgynevezettLabelAsKeyoszlopban tárolja. ALoadImagesaImagePathoszlop értékeit és aimageFolderparamétert használja a képek betöltésére a betanításhoz.Fitmetódust használva alkalmazza az adatokat apreprocessingPipelineEstimatorChainelemre, majd aTransformmetódust, amely egyIDataViewértéket ad vissza, az előre feldolgozott adatokat tartalmazva.Az adatokat betanítási, érvényesítési és tesztelési csoportokra osztja.
A modellek betanításához fontos, hogy betanítási adatkészlet és érvényesítési adatkészlet is legyen. A modell képzése a képzési adathalmazon történik. Az, hogy a nem látható adatokra milyen jól tesz előrejelzéseket, a validációs halmazzal szembeni teljesítménnyel mérjük. Ennek a teljesítménynek az eredményei alapján a modell módosításokat végez a tanultakon a fejlesztés érdekében. Az érvényesítési csoport származhat az eredeti adatkészlet felosztásából, vagy egy másik forrásból, amelyet erre a célra már félretettek.
A kódminta két felosztást hajt végre. Először az előre feldolgozott adatok felosztásra kerülnek, és 70% a betanításhoz, míg a fennmaradó 30% a validáláshoz. Ezt követően a 30% érvényesítési csoport további érvényesítési és tesztelési csoportokra lesz felosztva, ahol 90% szolgál az ellenőrzéshez, és 10% a teszteléshez.
Az adatpartíciók céljáról úgy is gondolkodhatunk, mint egy vizsgáról. A vizsgára való tanulás során áttekintheti jegyzeteit, könyveit vagy egyéb erőforrásait, hogy megismerkedjen a vizsgán szereplő fogalmakkal. Erre való a vonatkészlet. Ezután előfordulhat, hogy egy próbavizsga, hogy érvényesítse a tudását. Itt válik hasznossá a validációs adathalmaz. A tényleges vizsga előtt ellenőrizni szeretné, hogy jól érti-e a fogalmakat. Az eredmények alapján vegye figyelembe, hogy mit tévedett, vagy nem értette jól, és beépíti a módosításokat, amikor áttekinti a valódi vizsgát. Végül vizsgáznak. Erre szolgál a tesztkészlet. Még soha nem látta a vizsga kérdéseit, és most a betanításból és ellenőrzésből tanultakat felhasználva alkalmazza tudását a feladatra.
Hozzárendeli a partíciókhoz a megfelelő értékeket a tanítási, az érvényesítési és a tesztadatokhoz.
A betanítási folyamat definiálása
A modell betanítása két lépésből áll. Először az Image Classification API-t használja a modell betanítása. Ezután az oszlop kódolt címkéi PredictedLabel vissza lesznek alakítva az eredeti kategorikus értékükre az MapKeyToValue átalakítással.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Az előző kód:
Létrehoz egy új változót a szükséges és választható paraméterek tárolásához.ImageClassificationTrainer Az an ImageClassificationTrainer több választható paramétert is igénybe vehet:
-
FeatureColumnNamea modell bemeneteként használt oszlop. -
LabelColumnNameaz előrejelezendő érték oszlopa. -
ValidationSetazIDataViewérvényesítési adatokat tartalmazó adat. -
Archmeghatározza az előre betanított modellarchitektúrák közül melyiket kell használni. Ez az oktatóanyag a ResNetv2 modell 101 rétegű változatát használja. -
MetricsCallbackegy függvényt köt össze a betanítás során elért haladás nyomon követéséhez. -
TestOnTrainSetazt jelzi a modellnek, hogy mérje meg a teljesítményt a betanítási készleten, ha nincs érvényesítési készlet. -
ReuseTrainSetBottleneckCachedValuesjelzi a modellnek, hogy használja-e a gyorsítótárazott értékeket a szűk keresztmetszeti fázisból a későbbi futtatások során. A szűk keresztmetszeti fázis egy egyszeri átmenő számítás, amely számításigényes az első alkalommal. Ha a betanítási adatok nem változnak, és eltérő számú korszak vagy kötegméret használatával szeretne kísérletezni, a gyorsítótárazott értékek használata jelentősen csökkenti a modell betanításához szükséges időt. -
ReuseValidationSetBottleneckCachedValueshasonlóReuseTrainSetBottleneckCachedValues-hez, csak ebben az esetben az érvényesítési adatkészlethez.
-
Meghatározza a betanítási csővezetékét, amely mind a
EstimatorChain, mind amapLabelEstimatorés a ImageClassificationTrainer részeit tartalmazza.A
Fitmódszert használja a modell betanítására.
A modell használata
Most, hogy betanított egy modellt, itt az ideje, hogy a rendszerképek osztályozására használja.
Hozzon létre egy új segédprogram metódust, amely az előrejelzési információk megjelenítésére szolgál OutputPrediction a konzolon.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Egyetlen kép besorolása
Hozzon létre egy metódust
ClassifySingleImage, amely egyetlen képelőrejelzést készít és kiír.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }A
ClassifySingleImagemódszer:- Létrehoz egy belső
PredictionEnginemetódustClassifySingleImage. Ez aPredictionEngineegy kényelmi API, amely lehetővé teszi, hogy megadjon adatokat, majd előrejelzést készítsen egyetlen adatpéldányon. - Egyetlen
ModelInputpéldány eléréséhez adataIDataView-t konvertálja egyIEnumerable-ra aCreateEnumerablemetódus segítségével, majd lekéri az első megfigyelést. -
PredictA módszerrel osztályozza a képet. - Az előrejelzést a metódussal adja ki a konzolnak
OutputPrediction.
- Létrehoz egy belső
Hívás
ClassifySingleImage, miután meghívta a metódustFita képek tesztkészletével.ClassifySingleImage(mlContext, testSet, trainedModel);
Több kép osztályozása
Hozzon létre egy metódust
ClassifyImages, amely több kép-előrejelzést készít és ad ki.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }A
ClassifyImagesmódszer:- Létrehoz egy
IDataView-t, amely azTransformmetódus használatával tartalmazza az előrejelzéseket. - Az előrejelzések iterálásához konvertálja a
predictionDataIDataViewmetódust,IEnumerableCreateEnumerablemajd megkapja az első 10 megfigyelést. - Végigmegy rajta és kiírja az előrejelzések eredeti és előrejelzett címkéit.
- Létrehoz egy
Hívás
ClassifyImages, miután meghívta a metódustClassifySingleImage()a képek tesztkészletével.ClassifyImages(mlContext, testSet, trainedModel);
Az alkalmazás futtatása
Futtassa a konzolalkalmazást. A kimenetnek az alábbi kimenethez hasonlónak kell lennie.
Megjegyzés
Előfordulhat, hogy figyelmeztetések vagy üzenetek feldolgozása jelenik meg; ezek az üzenetek az egyértelműség érdekében el lettek távolítva az alábbi eredményekből. A rövidség kedvéért a kimenet kondenzálva lett.
Szűk keresztmetszeti fázis
A képnévhez nem nyomtatódik ki érték, mert a képek byte[]-ként töltődnek be, ezért nincs megjeleníthető képnév.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Betanítási fázis
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Képek kimenetének osztályozása
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
A 7001-220.jpg rendszerkép ellenőrzésekor ellenőrizheti, hogy nem repedt-e meg, ahogy azt a modell előrejelezte.

Gratulálok! Most már sikeresen létrehozott egy mélytanulási modellt a képek besorolásához.
A modell fejlesztése
Ha nem elégedett a modell eredményeivel, az alábbi módszerek kipróbálásával javíthatja a teljesítményét:
- További adatok: Minél több példát ismer egy modell, annál jobb teljesítményt nyújt. Töltse le a teljes SDNET2018 adatkészletet, és használja fel a betanításhoz.
- Az adatok bővítése: Az adatok változatossá tételének gyakori technikája az adatok kibővítése egy kép készítésével és különböző átalakítások (forgatás, tükrözés, váltás, körülvágás) alkalmazásával. Ez változatosabb példákat ad a modellhez, ahonnan tanulhat.
- Edzés hosszabb ideig: Minél tovább edz, annál jobban hangolt lesz a modell. A korszakok számának növelése javíthatja a modell teljesítményét.
- Kísérletezzen a hiperparaméterekkel: Az oktatóanyagban használt paraméterek mellett más paraméterek is hangolhatók a teljesítmény javítása érdekében. A tanulási sebesség módosítása, amely meghatározza a modellben az egyes korszakok után végrehajtott frissítések nagyságát, javíthatja a teljesítményt.
- Más modellarchitektúra használata: Attól függően, hogy az adatok hogyan néznek ki, az a modell, amely a legjobban tudja megismerni a funkcióit, eltérhet. Ha nem elégedett a modell teljesítményével, próbálja meg módosítani az architektúrát.
Következő lépések
Ebben az oktatóanyagban megtanulta, hogyan hozhat létre egyéni mélytanulási modellt a transfer learning, egy előre betanított képbesorolási TensorFlow-modell és a ML.NET Képbesorolási API használatával, a betonfelületek lemezképeinek repedtként vagy fel nem vettként való besorolásához.
További információért lépjen tovább a következő oktatóanyagra.
Lásd még
Dolgozzon együtt velünk a GitHubon
A tartalom forrása a GitHubon található, ahol létrehozhat és áttekinthet problémákat és lekéréses kérelmeket is. További információért tekintse meg a közreműködői útmutatónkat.