Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez az oktatóanyag bemutatja, hogyan készíthet filmajánlót ML.NET egy .NET-konzolalkalmazásban. A lépések a C# és a Visual Studio 2019-et használják.
Ebben az oktatóanyagban a következőket sajátíthatja el:
- Gépi tanulási algoritmus kiválasztása
- Adatok előkészítése és betöltése
- Modell létrehozása és betanítása
- Modell kiértékelése
- Modell üzembe helyezése és felhasználása
Az oktatóanyag forráskódját a dotnet/samples adattárban találja.
Gépi tanulási munkafolyamat
A következő lépésekkel hajthatja végre a feladatot, valamint bármely más ML.NET feladatot:
Előfeltételek
- Visual Studio 2022 vagy újabb verzió.
Válassza ki a megfelelő gépi tanulási feladatot
A javaslati problémák többféleképpen is közelíthetők meg, például a filmek listájának ajánlása vagy a kapcsolódó termékek listájának ajánlása, de ebben az esetben előre jelezheti, hogy a felhasználó milyen minősítést (1-5) ad egy adott filmnek, és azt javasolja, hogy a film magasabb, mint egy meghatározott küszöbérték (minél magasabb az értékelés, annál nagyobb a valószínűsége annak, hogy egy felhasználó kedvel egy adott filmet).
Konzolalkalmazás létrehozása
Projekt létrehozása
Hozzon létre egy "MovieRecommender" nevű C#- konzolalkalmazást . Kattintson a Tovább gombra.
Válassza a .NET 8-at a használni kívánt keretrendszerként. Kattintson a Létrehozás gombra.
Hozzon létre egy Data nevű könyvtárat a projektben az adatkészlet tárolásához:
A Megoldáskezelőben kattintson a jobb gombbal a projektre, és válassza azÚj mappa> lehetőséget. Írja be az "Adatok" kifejezést, és válassza az Enter billentyűt.
Telepítse a Microsoft.ML és a Microsoft.ML.Recommender NuGet-csomagokat:
Megjegyzés:
Ez a minta az említett NuGet-csomagok legújabb stabil verzióját használja, hacsak másként nem rendelkezik.
A Megoldáskezelő kattintson a jobb gombbal a projektre, és válassza a NuGet-csomagok kezelése lehetőséget. Válassza a "nuget.org" lehetőséget csomagforrásként, válassza a Tallózás lapot, keresse meg a Microsoft.ML, jelölje ki a csomagot a listában, és válassza a Telepítés lehetőséget. Kattintson az OK gombra a Változások előnézete párbeszédpanelen, majd válassza az Elfogadom gombot a Licenc elfogadása párbeszédpanelen, ha elfogadja a felsorolt csomagok licencfeltételét. Ismételje meg ezeket a lépéseket a Microsoft.ML.Recommender esetében.
Adja hozzá a következő
usingirányelveket a Program.cs fájl tetején:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Töltsd le adataidat
Töltse le a két adathalmazt, és mentse őket a korábban létrehozott Adat mappába:
Kattintson a jobb egérgombbal a recommendation-ratings-train.csv-ra, és válassza a "Hivatkozás vagy cél mentése másként..." lehetőséget.
Kattintson a jobb gombbal a recommendation-ratings-test.csv , és válassza a "Hivatkozás (vagy cél) mentése..." lehetőséget.
Győződjön meg arról, hogy a *.csv fájlokat az Adat mappába menti, vagy ha máshová menti, helyezze át a *.csv fájlokat az Adat mappába.
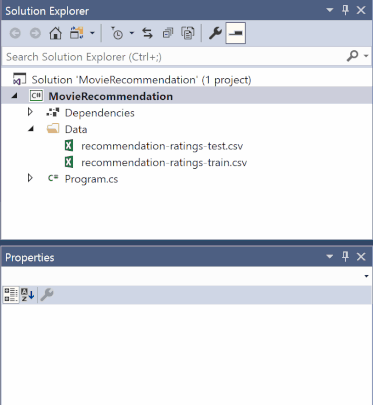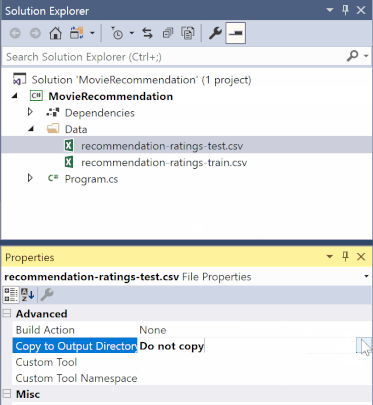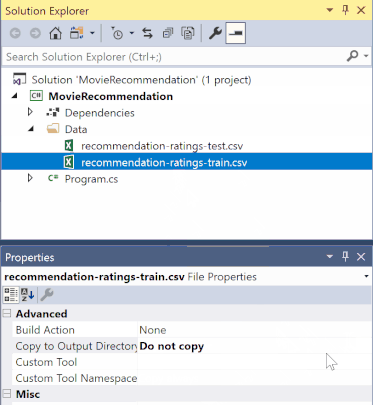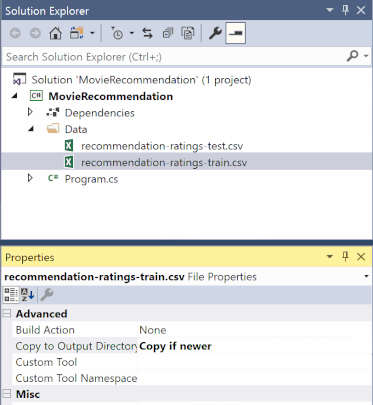
A Megoldáskezelőben kattintson a jobb gombbal az egyes *.csv fájlokra, és válassza a Tulajdonságok lehetőséget. A Speciális területen módosítsa a Kimeneti könyvtárba másolás értékét Másolás, ha újabb.
Adatok betöltése
A ML.NET folyamat első lépése a modell betanítási és tesztelési adatainak előkészítése és betöltése.
A javaslat minősítési adatai felosztásra Train és Test adathalmazokra oszlanak. A Train rendszer az adatokat a modellnek megfelelően használja. Az Test adatokkal előrejelzéseket készíthet a betanított modellel, és kiértékelheti a modell teljesítményét. Gyakori, hogy a 80/20-at felosztják az adatokkalTrain.Test
Az alábbiakban a *.csv fájlok adatainak előnézete látható:
A *.csv fájlokban négy oszlop található:
userIdmovieIdratingtimestamp
A gépi tanulásban az előrejelzéshez használt oszlopokat Szolgáltatásoknak nevezzük, a visszaadott előrejelzést tartalmazó oszlopot pedig címkének.
A filmértékeléseket szeretné előrejelezni, ezért az értékelési oszlop a Label. A másik három oszlop, userIdés movieIdtimestamp mind Features a következő előrejelzésére Labelszolgálnak.
| Features | Címke |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Ön dönti el, hogy melyiket Features használja a rendszer a Labelelőrejelzéshez. Olyan módszereket is használhat, mint a permutációs funkció fontossága , hogy segítsen kiválasztani a legjobbat Features.
Ebben az esetben meg kell szüntetnie az timestamp oszlopot Feature , mert az időbélyeg nem befolyásolja igazán, hogy egy felhasználó hogyan értékeli az adott filmet, és így nem járul hozzá a pontosabb előrejelzéshez:
| Features | Címke |
|---|---|
userId |
rating |
movieId |
Ezután meg kell határoznia az adatstruktúrát a bemeneti osztályhoz.
Adjon hozzá egy új osztályt a projekthez:
A Megoldáskezelőben kattintson a jobb gombbal a projektre, majd válassza az Új elem hozzáadása lehetőséget>.
Az Új elem hozzáadása párbeszédpanelen válassza az Osztály lehetőséget, és módosítsa a Név mezőt MovieRatingData.cs. Ezután válassza a Hozzáadás lehetőséget.
A MovieRatingData.cs fájl megnyílik a kódszerkesztőben. Adja hozzá a következő using irányelvet a MovieRatingData.cs elejéhez:
using Microsoft.ML.Data;
Hozzon létre egy MovieRating nevű osztályt a meglévő osztálydefiníció eltávolításával és a következő kód hozzáadásával a MovieRatingData.cs fájlba:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating egy bemeneti adatosztályt határoz meg. A LoadColumn attribútum azt határozza meg, hogy az adathalmaz mely oszlopait (oszlopindex alapján) kell betölteni. Az userId és movieId oszlopok az Ön Features (ezek a bemenetek, amelyeket a modellnek ad előrejelzés céljából Label), és a minősítési oszlop az Label, amelyet a modell előre jelez (a modell kimenete).
Hozzon létre egy másik osztályt az MovieRatingPredictionelőrejelzett eredmények megjelenítéséhez a következő kód hozzáadásával a MovieRatingMovieRatingData.cs osztálya után:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
A Program.cs cserélje le a Console.WriteLine("Hello World!") következő kódra:
MLContext mlContext = new MLContext();
Az MLContext osztály minden ML.NET művelet kiindulópontja, és az inicializálás mlContext új ML.NET környezetet hoz létre, amely megosztható a modelllétrehozási munkafolyamat-objektumok között. Ez fogalmilag hasonló az Entity Frameworkhez DBContext .
A fájl alján hozzon létre egy metódust LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Megjegyzés:
Ez a metódus hibaüzenetet ad, amíg a következő lépésekben meg nem adja a visszatérési utasítást.
Inicializálja az adatelérési út változóit, töltse be az adatokat a *.csv fájlokból, és adja vissza az Train és Test adatokat IDataView objektumokként. Ehhez adja hozzá a következő kódsort LoadData():
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
A ML.NET adatai IDataView-felületként jelenik meg.
IDataView a táblázatos adatok (numerikus és szöveges) leírásának rugalmas, hatékony módja. Az adatok betölthetők szövegfájlból vagy valós időben (például SQL-adatbázisból vagy naplófájlokból) egy IDataView objektumba.
A LoadFromTextFile() meghatározza az adatsémát, és beolvassa a fájlban. Felveszi az adatelérési út változóit, és visszaad egy IDataView. Ebben az esetben megadja a Test és Train fájlok elérési útját, valamint a szövegfájl fejlécét (így megfelelően használhatja az oszlopneveket) és a vessző karaktert mint adatelválasztót (az alapértelmezett elválasztó a tabulátor).
Adja hozzá a következő kódot a metódus meghívásáhozLoadData(), és adja vissza az és Train az Test adatokat:
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
A modell összeállítása és betanítása
Hozza létre a metódust BuildAndTrainModel() a metódus után LoadData() , a következő kóddal:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Megjegyzés:
Ez a metódus hibaüzenetet ad, amíg a következő lépésekben meg nem adja a visszatérési utasítást.
Az adatátalakítások definiálásához adja hozzá a következő kódot BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Mivel userId a felhasználókat és movieId a mozgóképcímeket jeleníti meg, nem pedig a valós értékeket, a MapValueToKey() metódussal mindegyiket userIdmovieId numerikus kulcs típusú Feature oszlopmá alakíthatja (ez a javaslati algoritmusok által elfogadott formátum), és új adathalmazoszlopként adja hozzá őket:
| userId | movieId | Címke | felhasználóAzonosítóKódolt | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Válassza ki a gépi tanulási algoritmust, és fűzze hozzá az adatátalakítási definíciókhoz a következő kódsor BuildAndTrainModel()hozzáadásával:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
A MatrixFactorizationTrainer a javaslati betanítási algoritmus. A Matrix Factorization a javaslatok gyakori módszere, ha olyan adatokkal rendelkezik, amelyek azt jelzik, hogy a felhasználók hogyan értékelték a termékeket a múltban, ami az oktatóanyagban szereplő adathalmazok esetében is így van. Vannak más ajánlási algoritmusok is, ha különböző adatok állnak rendelkezésre (további információért tekintse meg az Egyéb javaslati algoritmusok szakaszt).
Ebben az esetben az Matrix Factorization algoritmus egy "együttműködésen alapuló szűrés" nevű módszert használ, amely feltételezi, hogy ha az 1. felhasználó véleménye megegyezik a 2. felhasználóval egy bizonyos problémáról, akkor az 1. felhasználó valószínűleg ugyanúgy érzi magát, mint a 2. felhasználó egy másik problémáról.
Ha például az 1. felhasználó és a 2. felhasználó is hasonlóan értékel filmeket, akkor a 2. felhasználó nagyobb valószínűséggel élvezi az 1. felhasználó által megtekintett és magas minősítéssel rendelkező filmet:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Felhasználó 1 | Megtekintett és kedvelt film | Megtekintett és kedvelt film | Megtekintett és kedvelt film |
| 2. felhasználó | Megtekintett és kedvelt film | Megtekintett és kedvelt film | Nem figyelt -- AJÁNLom a filmet |
A Matrix Factorization tréner számos lehetőséggel rendelkezik, amelyekről az alábbi Algoritmus hiperparaméterek című szakaszban olvashat bővebben.
Illesztse a modellt az Train adatokhoz, és adja vissza a betanított modellt úgy, hogy a következő kódsort adja hozzá a BuildAndTrainModel() metódushoz:
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
A Fit() metódus a megadott betanítási adatkészlettel tanítja be a modellt. Technikailag végrehajtja a definíciókat az Estimator adatok átalakításával és a betanítás alkalmazásával, és visszaadja a betanított modellt, amely egy Transformer.
A ML.NET modellbetanítási munkafolyamatáról további információt a Mi ML.NET és hogyan működik?
A metódus meghívásához LoadData() és a betanított modell visszaadásához adja hozzá a következő kódsort a metódus hívása BuildAndTrainModel() alatt:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
A modell kiértékelése
A modell betanítása után a tesztadatok segítségével értékelje ki, hogyan teljesít a modell.
Hozza létre a metódust EvaluateModel() a metódus után BuildAndTrainModel() , a következő kóddal:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Az adatok átalakításához Test adja hozzá a következő kódot EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
A Transform() metódus egy tesztadatkészlet több megadott bemeneti sorára vonatkozó előrejelzéseket készít.
Értékelje ki a modellt úgy, hogy a következő kódsort adja hozzá a EvaluateModel() metódushoz:
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Miután elkészült az előrejelzési csoporttal, a Evaluate() metódus kiértékeli a modellt, amely összehasonlítja az előrejelzett értékeket a tesztadatkészlet tényleges Labels értékeivel, és metrikákat ad vissza a modell teljesítményéről.
Nyomtassa ki a kiértékelési metrikákat a konzolon a következő kódsor hozzáadásával a EvaluateModel() metódusban:
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
A metódus meghívásához adja hozzá a következő kódsort BuildAndTrainModel() a EvaluateModel() metódus hívása alatt:
EvaluateModel(mlContext, testDataView, model);
Az eddigi kimenetnek az alábbi szöveghez hasonlóan kell kinéznie:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
Ebben a kimenetben 20 iteráció található. Minden iterációban a hiba mértéke csökken, és közelebb kerül a 0-hoz.
Az root of mean squared error (RMS vagy RMSE) a modell által előrejelzett értékek és a vizsgált adathalmaz megfigyelt értékei közötti különbségek mérésére szolgál. Technikailag ez a hibák négyzetének átlagának négyzetgyöke. Minél alacsonyabb, annál jobb a modell.
R Squared azt jelzi, hogy az adatok mennyire illenek egy modellhez. 0 és 1 közötti tartomány. A 0 érték azt jelenti, hogy az adatok véletlenszerűek, vagy más módon nem felelnek meg a modellnek. Az 1 érték azt jelenti, hogy a modell pontosan egyezik az adatokkal. Azt szeretné, hogy a R Squared pontszám a lehető legközelebb legyen az 1-hez.
A sikeres modellek létrehozása iteratív folyamat. Ez a modell kezdeti minősége alacsonyabb, mivel az oktatóanyag kis adatkészleteket használ a modell gyors betanításához. Ha nem elégedett a modell minőségével, nagyobb betanítási adatkészletek biztosításával vagy az egyes algoritmusokhoz különböző hiperparaméterekkel rendelkező különböző betanítási algoritmusok kiválasztásával próbálhatja javítani. További információkért tekintse meg az alábbi Modell fejlesztése című szakaszt .
A modell használata
Most már használhatja a betanított modellt, hogy előrejelzéseket készítsen az új adatokról.
Hozza létre a metódust UseModelForSinglePrediction() a metódus után EvaluateModel() , a következő kóddal:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
PredictionEngine A minősítés előrejelzéséhez adja hozzá a következő kódot a következőhözUseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
A PredictionEngine egy egyszerű API, amely lehetővé teszi az előrejelzés végrehajtását egyetlen adatpéldányon.
PredictionEngine nincs szálbiztos. Egyszálas vagy prototípusos környezetben is használható. Az éles környezetekben a jobb teljesítmény és a szálbiztonság érdekében használja a PredictionEnginePool szolgáltatást, amely objektumokat hoz létre ObjectPoolPredictionEngine az alkalmazás teljes területén való használatra. Ebből az útmutatóból megtudhatja, hogyan használható PredictionEnginePool egy ASP.NET Core Web API-ban.
Megjegyzés:
PredictionEnginePool A szolgáltatásbővítmény jelenleg előzetes verzióban érhető el.
Hozzon létre egy meghívott MovieRating példányttestInput, és adja át az előrejelzési motornak a következő kódsorok hozzáadásával a UseModelForSinglePrediction() metódusban:
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
A Predict() függvény egyetlen adatoszlopon készít előrejelzést.
Ezután a Score(vagy az előrejelzett) minősítéssel meghatározhatja, hogy a 10. filmazonosítóval a 6. felhasználónak szeretné-e ajánlani a filmet. Minél magasabb, Scoreannál nagyobb annak a valószínűsége, hogy egy felhasználó kedvel egy adott filmet. Ebben az esetben tegyük fel, hogy 3,5-ös > előrejelzéssel rendelkező filmeket ajánl.
Az eredmények nyomtatásához adja hozzá a következő kódsorokat a UseModelForSinglePrediction() metódushoz:
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Adja hozzá a következő kódsort a metódus EvaluateModel() meghívása UseModelForSinglePrediction() után:
UseModelForSinglePrediction(mlContext, model);
A metódus kimenetének a következő szöveghez hasonlóan kell kinéznie:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
A modell mentése
Ha a modell használatával előrejelzéseket szeretne készíteni a végfelhasználói alkalmazásokban, először mentenie kell a modellt.
Hozza létre a metódust SaveModel() a metódus után UseModelForSinglePrediction() , a következő kóddal:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
A betanított modell mentéséhez adja hozzá a következő kódot a SaveModel() metódushoz:
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Ez a módszer egy .zip fájlba menti a betanított modellt (az "Adatok" mappába), amely aztán más .NET-alkalmazásokban is használható előrejelzések készítésére.
Adja hozzá a következő kódsort a metódus UseModelForSinglePrediction() meghívása SaveModel() után:
SaveModel(mlContext, trainingDataView.Schema, model);
A mentett modell használata
Miután mentette a betanított modellt, különböző környezetekben használhatja a modellt. A betanított modellek mentéséről és betöltéséről a betanított gépi tanulási modellek alkalmazásokban való üzembe helyezése című témakörben olvashat.
Results
A fenti lépések elvégzése után futtassa a konzolalkalmazást (Ctrl + F5). A fenti egyetlen előrejelzés eredményeinek az alábbihoz hasonlónak kell lenniük. Megjelenhetnek figyelmeztetések vagy feldolgozással kapcsolatos üzenetek, de ezeket az üzeneteket eltávolítottuk az alábbi eredményekből az egyértelműség érdekében.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Gratulálok! Sikeresen létrehozott egy gépi tanulási modellt a filmek ajánlásához. Az oktatóanyag forráskódját a dotnet/samples adattárban találja.
Modell továbbfejlesztése
Számos módon javíthatja a modell teljesítményét, hogy pontosabb előrejelzéseket kapjon.
Adat
Ha több olyan betanítási adatot ad hozzá, amely elegendő mintával rendelkezik az egyes felhasználókhoz és mozgókép-azonosítókhoz, javíthatja a javaslati modell minőségét.
A keresztérvényesítés egy olyan módszer, amellyel olyan modelleket lehet kiértékelni, amelyek véletlenszerűen osztják fel az adatokat részhalmazokra (ahelyett, hogy tesztadatokat nyernek ki az adathalmazból, mint ebben az oktatóanyagban), és néhány csoportot betanítási adatként, néhány csoportot pedig tesztadatokként használnak. Ez a módszer a modellminőség szempontjából felülmúlja a vonattesztek felosztását.
Features
Ebben az oktatóanyagban csak az adathalmaz által biztosított három Features-t (user id, movie id és rating) használja.
Bár ez jó kezdet, a valóságban érdemes lehet más attribútumokat vagy Features (például életkort, nemet, földrajzi helyet stb.) hozzáadni, ha azok szerepelnek az adathalmazban. Ha relevánsabb Features elemet ad hozzá, azzal javíthatja a javaslatmodell teljesítményét.
Ha nem biztos benne, hogy melyik Features lehet a leginkább releváns a gépi tanulási feladathoz, a funkcióbevonási számítás (FCC) és a permutációs funkció fontosságát is használhatja, amely ML.NET biztosítja a legbefolyásosabbak Featuresfelfedezéséhez.
Algoritmus hiperparaméterei
Bár ML.NET jó alapértelmezett betanítási algoritmusokat biztosít, az algoritmus hiperparamétereinek módosításával tovább finomhangolhatja a teljesítményt.
Például Matrix Factorizationkísérletezhet olyan hiperparaméterekkel, mint a NumberOfIterations és az ApproximationRank , hogy lássa, ez jobb eredményt ad-e.
Ebben az oktatóanyagban például az algoritmus beállításai a következők:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Egyéb javaslati algoritmusok
A mátrix-faktorizációs algoritmus az együttműködésen alapuló szűréssel csak egy megközelítés a filmjavaslatok végrehajtásához. Sok esetben előfordulhat, hogy a minősítési adatok nem érhetők el, és csak a felhasználók számára érhetők el a filmelőzmények. Más esetekben előfordulhat, hogy nem csak a felhasználó minősítési adataival rendelkezik.
| Algorithm | Scenario | Sample |
|---|---|---|
| Egyosztályos mátrix faktorizálása | Ezt akkor használja, ha csak userId és movieId azonosítóval rendelkezik. Ez a javaslati stílus az együttes vásárlás forgatókönyvén vagy a gyakran együtt vásárolt termékeken alapul, ami azt jelenti, hogy a saját vásárlási rendelési előzményeik alapján javasolni fogja az ügyfeleknek a termékek egy készletét. | >Próbálja ki |
| Mezőérzékeny faktorizációs gépek | Ezzel javaslatokat tehet, ha több, a userId-n, a productId-n és az értékelésen (például termékleíráson vagy termékáron) túlmutató szolgáltatással rendelkezik. Ez a módszer együttműködésen alapuló szűrési módszert is használ. | >Próbálja ki |
Új felhasználói forgatókönyv
Az együttműködésen alapuló szűrés egyik gyakori problémája a hidegindítási probléma, amely akkor jelentkezik, ha olyan új felhasználóval rendelkezik, aki nem rendelkezik korábbi adatokkal, hogy következtetéseket vonjon le. Ezt a problémát gyakran azzal oldják meg, hogy új felhasználókat kérnek egy profil létrehozására, és például értékelik a korábban látott filmeket. Bár ez a módszer némi terhet ró a felhasználóra, néhány kezdőadatot biztosít azoknak az új felhasználóknak, akik nem rendelkeznek minősítési előzményekkel.
Resources
Az oktatóanyagban használt adatok a MovieLens-adathalmazból származnak.
Következő lépések
Ez az oktatóanyag bemutatta, hogyan végezheti el az alábbi műveleteket:
- Gépi tanulási algoritmus kiválasztása
- Adatok előkészítése és betöltése
- Modell létrehozása és betanítása
- Modell kiértékelése
- Modell üzembe helyezése és felhasználása
További információért lépjen tovább a következő oktatóanyagra
Dolgozzon együtt velünk a GitHubon
A tartalom forrása a GitHubon található, ahol létrehozhat és áttekinthet problémákat és lekéréses kérelmeket is. További információért tekintse meg a közreműködői útmutatónkat.