Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk áttekintést nyújt azokról a típusokról, amelyek segítenek a több pufferben futó adatok olvasásában. Elsősorban PipeReader objektumok támogatására szolgálnak.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> szinkron pufferelt írásra vonatkozó szerződés. A legalacsonyabb szinten a felület:
- Alapszintű és nem nehéz használni.
- Engedélyezi a hozzáférést egy Memory<T> vagy Span<T>. A
Memory<T>vagySpan<T>megírható, és meghatározhatja, hogy hányTelemet írtak.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
Az előző módszer:
- Kér egy legalább 5 bájtos puffert a
IBufferWriter<byte>-tól aGetSpan(5)használatával. - ASCII "Hello" karakterlánc bájtjait írja az így kapott
Span<byte>elemre. - Hívások IBufferWriter<T> a pufferbe írt bájtok számának jelzésére.
Ez az írási módszer a Memory<T>/Span<T> puffer használatát alkalmazza, amelyet a IBufferWriter<T> biztosít. Másik lehetőségként a Write kiterjesztési metódus használható egy meglévő puffer másolására a IBufferWriter<T>-be.
Write a megfelelő módon hívja meg a GetSpan/Advance-t, így nincs szükség külön Advance hívására írás után.
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> annak a implementációja IBufferWriter<T> , amelynek háttértárolója egyetlen egybefüggő tömb.
Az IBufferWriter gyakori problémái
-
GetSpanésGetMemoryadjon vissza egy puffert legalább a kért memóriamennyiséggel. Ne feltételezze a puffer pontos méretét. - Nincs garancia arra, hogy az egymást követő hívások ugyanazt a puffert vagy azonos méretű puffert fogják visszaadni.
- A további adatok írásának folytatásához a hívás
Advanceután új puffert kell kérni. Egy korábban megszerzett puffer nem írható, miután aAdvancehívásra került.
ReadOnlySequence<T>
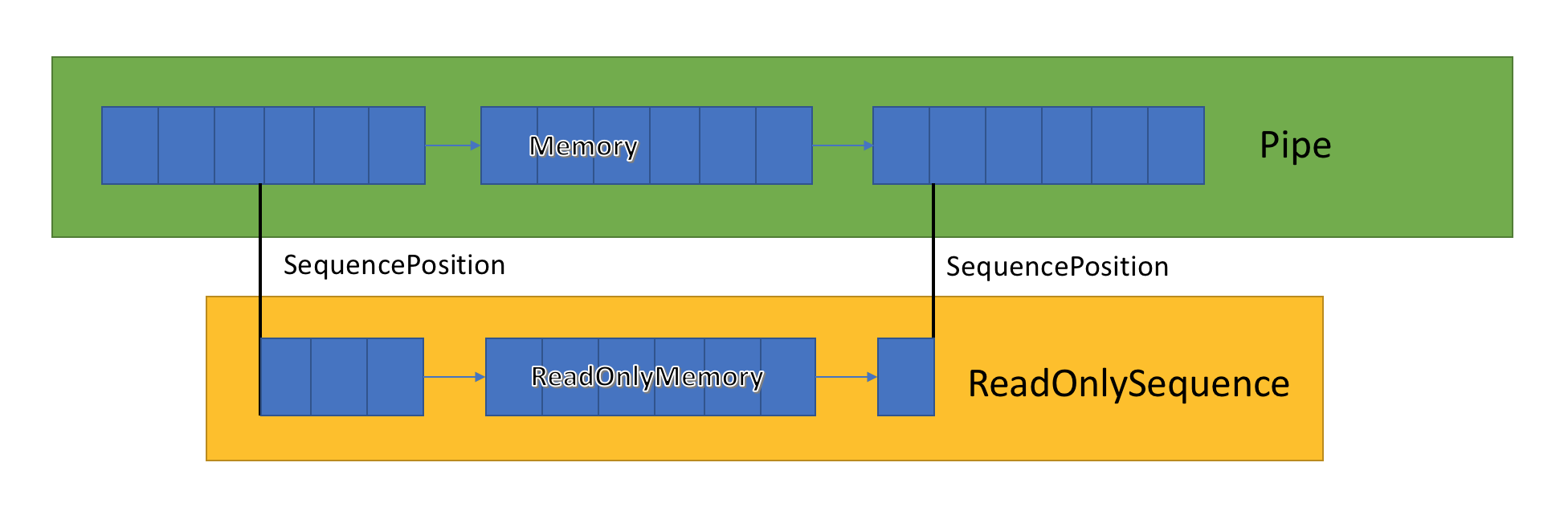
ReadOnlySequence<T> egy struktúra, amely egy egybefüggő vagy nem folytonos sorozatot jelölhet T-ből. Az alábbi elemekből építhető ki:
- Egy
T[] - Egy
ReadOnlyMemory<T> - Csatolt listacsomópont ReadOnlySequenceSegment<T> és indexpár, amely a sorozat kezdő és záró pozícióját jelöli.
A harmadik ábrázolás a legérdekesebb, mivel teljesítménybeli hatásokkal van a különböző műveletekre a ReadOnlySequence<T> esetében.
| Képviselet | Művelet | Összetettség |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
A vegyes ábrázolás miatt az ReadOnlySequence<T> indexeket egész szám helyett SequencePosition teszi elérhetővé. A SequencePosition:
- Átlátszatlan érték, amely egy indexet jelöl a
ReadOnlySequence<T>kiindulási helyre. - Két részből, egy egész számból és egy objektumból áll. Az a két érték kapcsolódik a
ReadOnlySequence<T>végrehajtásához.
Adatok elérése
A ReadOnlySequence<T> az adatokat ReadOnlyMemory<T> felsorolhatóként teszi elérhetővé. Az egyes szegmensek számbavétele egy alapszintű foreach használatával végezhető el:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
Az előző metódus az egyes szegmensekben keres egy adott bájtot. Ha minden egyes szegmenst nyomon kell követnie, akkor a SequencePosition célszerűbb. A következő minta úgy módosítja az előző kódot, hogy egész szám helyett egy SequencePosition értéket adjon vissza. A visszaadott adatok SequencePosition előnye, hogy lehetővé teszik a hívó számára, hogy elkerülje a második vizsgálatot az adatok adott indexben való lekéréséhez.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
A kombináció, SequencePosition és TryGet úgy viselkedik, mint egy enumerátor. A pozíciómező az egyes iterációk elején módosul, hogy az egyes szegmensek kezdetét jelezze a ReadOnlySequence<T>-ben.
Az előző metódus bővítménymetódusként létezik a következőn ReadOnlySequence<T>: .
PositionOf az előző kód egyszerűsítése érdekében használható:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Feldolgozza a ReadOnlySequence<T> rendszert
Egy ReadOnlySequence<T> feldolgozása kihívást jelenthet, mivel az adatok lehet, hogy több szegmensre oszlanak a sorozaton belül. A legjobb teljesítmény érdekében ossza fel a kódot két útvonalra:
- Egy gyors útvonal, amely az egyetlen szegmenses esettel foglalkozik.
- Lassú folyamat, amely a szegmensek közötti adatmegosztással foglalkozik.
Az adatok többszegmenses szekvenciákban történő feldolgozásához néhány módszer használható:
- Használja a
SequenceReader<T>. - Elemezze az adatszegmenseket szegmensen ként, nyomon követve az
SequencePositionpozícióját és az elemzett szegmensen belüli indexet. Ez elkerüli a szükségtelen foglalásokat, de nem hatékony, különösen a kis pufferek esetében. - Másolja a
ReadOnlySequence<T>tömböt egy összefüggő tömbbe, és kezelje egyetlen pufferként:- Ha a
ReadOnlySequence<T>mérete kicsi, ésszerű lehet az adatokat egy veremre lefoglalt pufferbe másolni a stackalloc operátor segítségével. - Másolja a
ReadOnlySequence<T>a ArrayPool<T>.Shared segítségével a készletezett tömbbe. - Használja a
ReadOnlySequence<T>.ToArray(). Ez nem ajánlott a gyakori elérésű útvonalakon, mivel újatT[]foglal le a halomra.
- Ha a
Az alábbi példák a feldolgozás ReadOnlySequence<byte>néhány gyakori esetét szemléltetik:
Bináris adatok feldolgozása
Az alábbi példa egy 4 bájtos big-endian egész szám hosszát értelmezi a ReadOnlySequence<byte> elejétől.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Szövegadatok feldolgozása
A következő példa:
- Megkeresi az első új sort (
\r\n) aReadOnlySequence<byte>-ben, és a 'line' kimeneti paraméteren keresztül adja vissza. - Eltávolítja a sort úgy, hogy a
\r\n-t kihagyja a bemeneti pufferből.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Üres szegmensek
Érvényes üres szegmensek tárolása egy ReadOnlySequence<T>-ben. Üres szegmensek fordulhatnak elő a szegmensek explicit számbavétele során:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
Az előző kód létrehoz egy ReadOnlySequence<byte> üres szegmenseket, és bemutatja, hogy ezek az üres szegmensek hogyan befolyásolják a különböző API-kat:
-
ReadOnlySequence<T>.Sliceha egySequencePositionüres szegmensre mutat, az megőrzi ezt a szegmenst. -
ReadOnlySequence<T>.Sliceegy inttel átugorjuk az üres szegmenseket. - A
ReadOnlySequence<T>felsorolja az üres szegmenseket.
A ReadOnlySequence<T> és a SequencePosition lehetséges problémái
A ReadOnlySequence<T>/SequencePosition és egy normál ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int összehasonlításakor számos szokatlan eredmény érhető el.
-
SequencePositionegy adottReadOnlySequence<T>, nem abszolút pozícióhoz tartozó pozíciójelölő. Mivel egy adotthozReadOnlySequence<T>viszonyítva van, nincs értelme, ha aReadOnlySequence<T>kiindulási helyén kívül használják. - Az aritmetikai műveletek nem végezhetők el
SequencePositionnélkül aReadOnlySequence<T>. Ez azt jelenti, hogy alapvető dolgokat, mint példáulposition++, ígyposition = ReadOnlySequence<T>.GetPosition(1, position)írni. -
GetPosition(long)nem támogatja a negatív indexeket. Ez azt jelenti, hogy lehetetlen megszerezni az utolsó előtti karaktert anélkül, hogy végigjárnánk az összes szakaszt. - Kettő
SequencePositionnem hasonlítható össze, ami megnehezíti a következőt:- Annak megállapítása, hogy az egyik helyzet nagyobb vagy kisebb, mint egy másik helyzet.
- Írjon elemzési algoritmusokat.
-
ReadOnlySequence<T>nagyobb, mint egy objektumhivatkozás, és ahol lehetséges, in vagy ref alapján kell átadni. ÁtadásReadOnlySequence<T>invagyrefcsökkenti a szerkezet másolatait. - Üres szegmensek:
- Érvényes
ReadOnlySequence<T>-on belül. - Az iterálás során a
ReadOnlySequence<T>.TryGetmetódus használatakor megjelenhet. - A sorozat szeletelése a
ReadOnlySequence<T>.Slice()módszerrelSequencePositionobjektumok segítségével jelenhet meg.
- Érvényes
SequenceReader<T>
- A .NET Core 3.0-ban bevezetett egy új típus egyszerűsíti a
ReadOnlySequence<T>feldolgozását. - Egyesíti az egy szegmens és a több szegmens
ReadOnlySequence<T>ReadOnlySequence<T>közötti különbségeket. - Segítséget nyújt olyan bináris és szöveges adatok (
byteéschar) olvasásához, amelyek szegmensekre oszthatók vagy nem oszthatók fel.
A bináris és a tagolt adatok feldolgozásának kezelésére beépített módszerek is léteznek. Az alábbi szakasz megmutatja, hogyan néznek ki ezek a metódusok a SequenceReader<T> használatával.
Adatok elérése
A SequenceReader<T>-nak vannak metódusai az adatok közvetlen számbavételére a ReadOnlySequence<T>-ban. Az alábbi kód egy példa arra, hogyan dolgozzunk fel egyszerre egy ReadOnlySequence<byte> és egy byte:
while (reader.TryRead(out byte b))
{
Process(b);
}
A CurrentSpan művelet az aktuális szegmenseket Spanteszi elérhetővé, ami hasonló a módszer manuális műveletéhez.
Pozíció használata
Az alábbi kód egy példa a FindIndexOf implementálására a SequenceReader<T> használatával.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Bináris adatok feldolgozása
Az alábbi példa egy 4 bájtos big-endian egész szám hosszát értelmezi a ReadOnlySequence<byte> elejétől.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Szövegadatok feldolgozása
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
SequenceReader<T> – gyakori problémák
- Mivel
SequenceReader<T>ez egy mutable struct, azt mindig hivatkozással kell átadni. -
SequenceReader<T>egy refstruct , így csak szinkron metódusokban használható, és nem tárolható mezőkben. További információért lásd: A foglalások elkerülése. -
SequenceReader<T>csak továbbítható olvasóként való használatra van optimalizálva.Rewindolyan kis biztonsági mentésekhez készült, amelyek más ,ReadésPeekAPI-k használatávalIsNextnem kezelhetők.
Dolgozzon együtt velünk a GitHubon
A tartalom forrása a GitHubon található, ahol létrehozhat és áttekinthet problémákat és lekéréses kérelmeket is. További információért tekintse meg a közreműködői útmutatónkat.