Adatok betöltése a lakehouse-ba jegyzetfüzet használatával
Ebben az oktatóanyagban megtudhatja, hogyan olvashat és írhat adatokat a Fabric lakehouse-ba egy jegyzetfüzettel. A Fabric támogatja a Spark API-t, és a Pandas API célja ennek elérése.
Adatok betöltése Apache Spark API-val
A jegyzetfüzet kódcellájában az alábbi példakód használatával olvassa be az adatokat a forrásból, és töltse be őket a Fájlok, táblázatok vagy a tóház mindkét szakaszába.
Az olvasás helyének megadásához használhatja a relatív elérési utat, ha az adatok az aktuális jegyzetfüzet alapértelmezett lakehouse-jából származnak. Vagy ha az adatok egy másik lakehouse-ból származnak, használhatja az abszolút Azure Blob Fájlrendszer (ABFS) elérési utat. Másolja ezt az elérési utat az adatok helyi menüjéből.
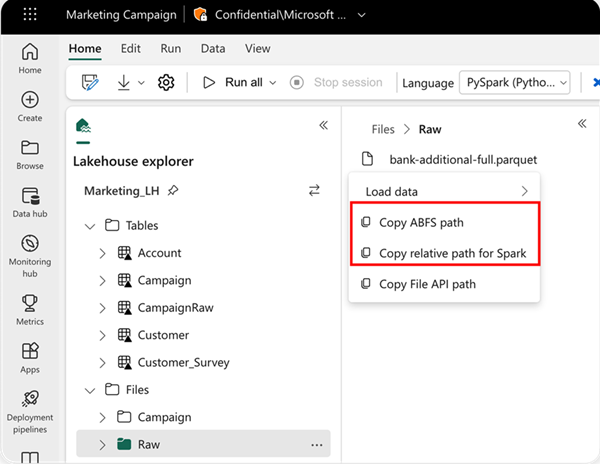
ABFS-elérési út másolása: Ez a beállítás a fájl abszolút elérési útját adja vissza.
A Spark relatív elérési útjának másolása: Ez a beállítás a fájl relatív elérési útját adja vissza az alapértelmezett lakehouse-ban.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Adatok betöltése a Pandas API-val
A Pandas API támogatásához a rendszer automatikusan csatlakoztatja az alapértelmezett lakehouse-t a jegyzetfüzethez. A csatlakoztatási pont a következő: "/lakehouse/default/". Ezzel a csatlakoztatási ponttal adatokat olvashat/írhat az alapértelmezett lakehouse-ból vagy onnan az alapértelmezett tóházba. A helyi menü "Fájl API-elérési útjának másolása" lehetőség a Fájl API elérési útját adja vissza a csatlakoztatási pontról. Az ABFS-elérési út másolása lehetőségből visszaadott elérési út a Pandas API-hoz is működik.
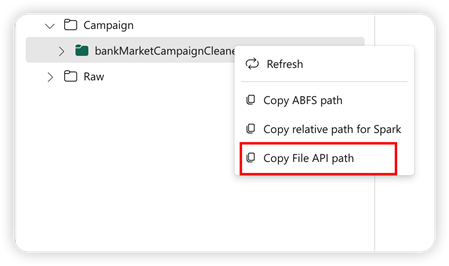
Fájl API elérési útjának másolása: Ez a beállítás az alapértelmezett lakehouse csatlakoztatási pontja alatti elérési utat adja vissza.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tipp.
A Spark API-hoz használja az ABFS-elérési út másolása vagy a Spark relatív elérési útjának másolása lehetőséget a fájl elérési útjának lekéréséhez. Pandas API esetén használja az ABFS-elérési út másolása vagy a Fájl másolása API-elérési út beállítását a fájl elérési útjának lekéréséhez.
A Spark API-val vagy a Pandas API-val való együttműködés leggyorsabb módja az adatok betöltése és a használni kívánt API kiválasztása. A kód automatikusan létrejön a jegyzetfüzet új kódcellájában.
