Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A Microsoft Fabric egy integrált elemzési szolgáltatás, amely felgyorsítja az adattárházak és big data rendszerek elemzési idejét. A jegyzetfüzetek adatvizualizációja kulcsfontosságú funkció, amely lehetővé teszi, hogy betekintést nyerjen az adatokba, így a felhasználók könnyedén azonosíthatják a mintákat, trendeket és kiugró értékeket.
Az Apache Spark in Fabric használatakor beépített lehetőségek állnak rendelkezésre az adatok vizualizációjához, beleértve a Fabric-jegyzetfüzet diagramfunkcióit és a népszerű nyílt forráskódú kódtárakhoz való hozzáférést.
A hálójegyzetfüzetek lehetővé teszik, hogy a táblázatos eredményeket testre szabott diagramokká alakítsa anélkül, hogy kódokat írnál, így intuitívabb és zökkenőmentesebb adatfeltárási élményt biztosít.
Beépített vizualizációs parancs - display() függvény
A Fabric beépített vizualizációs funkciója lehetővé teszi az Apache Spark DataFrames, a Pandas DataFrames és az SQL-lekérdezési eredmények gazdag, interaktív adatvizualizációkká alakítását.
A megjelenítési függvény használatával dinamikus táblázatként vagy diagramként jelenítheti meg a PySparkot és a Scala Spark DataFrame-eket vagy a rugalmas elosztott adatkészleteket (RDD-ket).
Megadhatja a renderelt adatkeret sorszámát. Az alapértelmezett érték 1000. A jegyzetfüzet

A globális eszköztár szűrőfüggvényével testre szabott szabályokat alkalmazhat az adatokra. A szűrőfeltétel egy adott oszlopra lesz alkalmazva, és az eredmények a táblázat- és diagramnézetekben is megjelennek.

Az SQL utasítás kimenete alapértelmezés szerint ugyanazt a kimeneti widgetet használja a display() funkcióval.
Gazdag adatkeret táblázatos megjelenítés
Ingyenes kijelölés támogatása táblázat nézetben
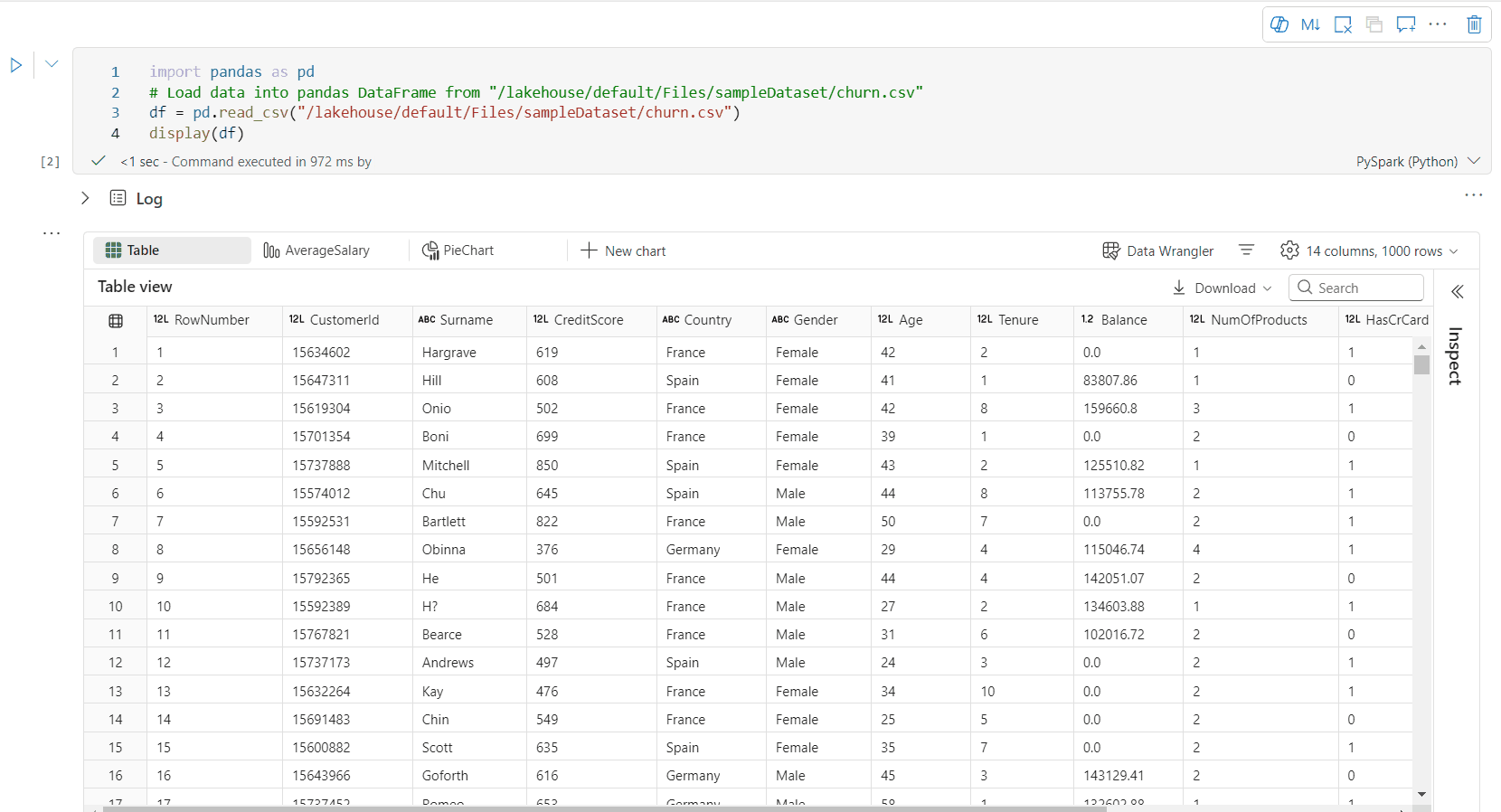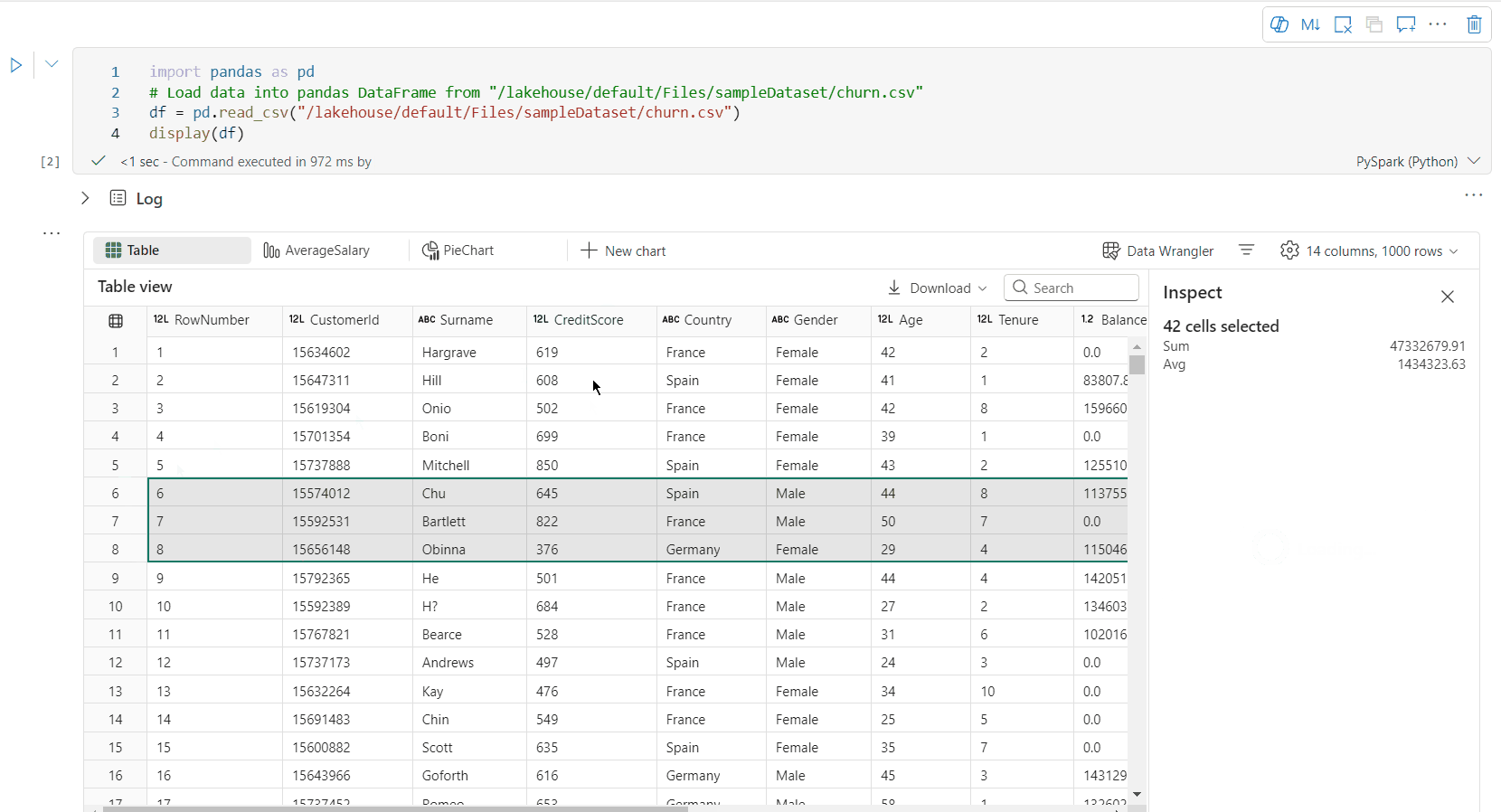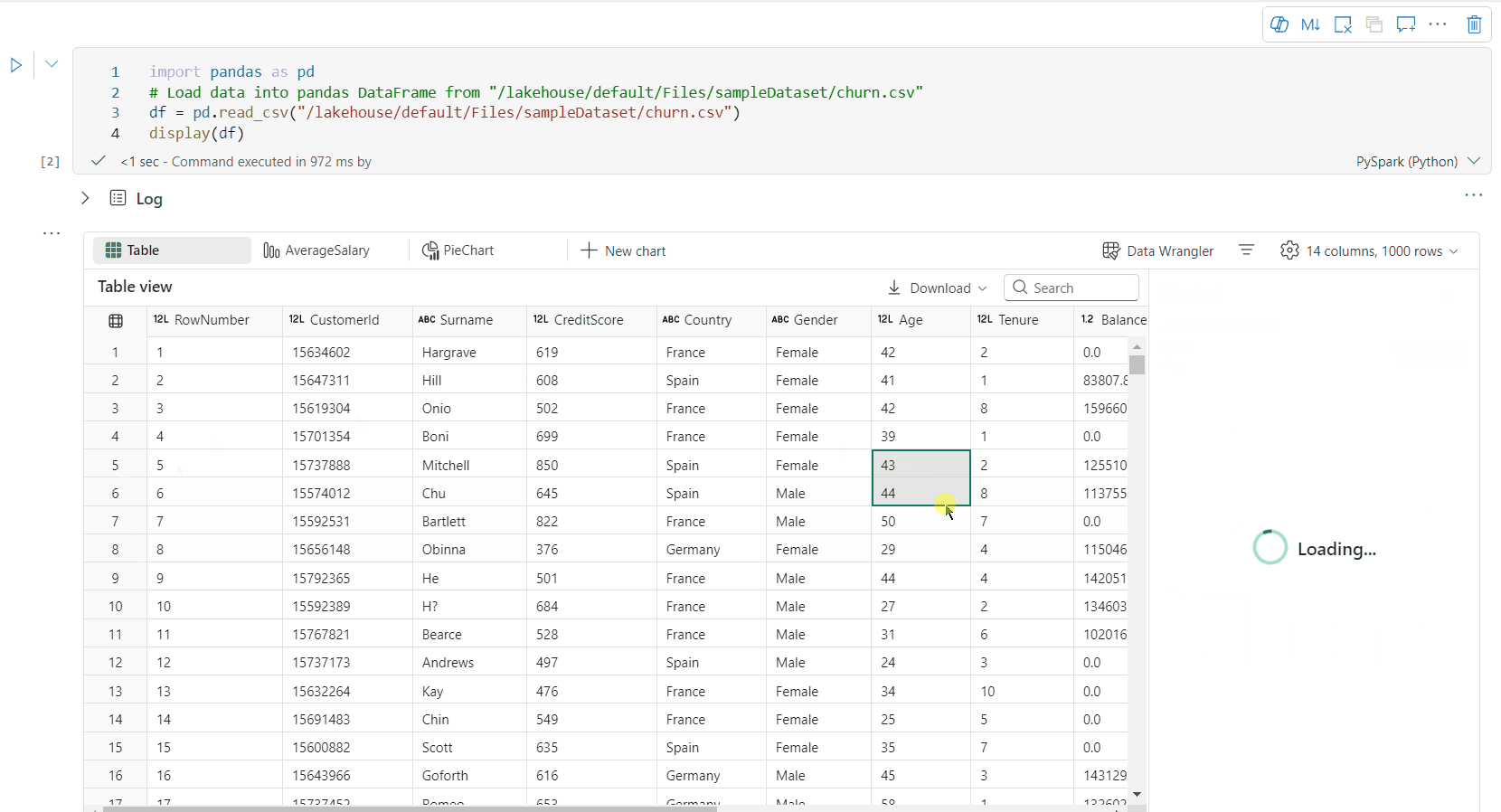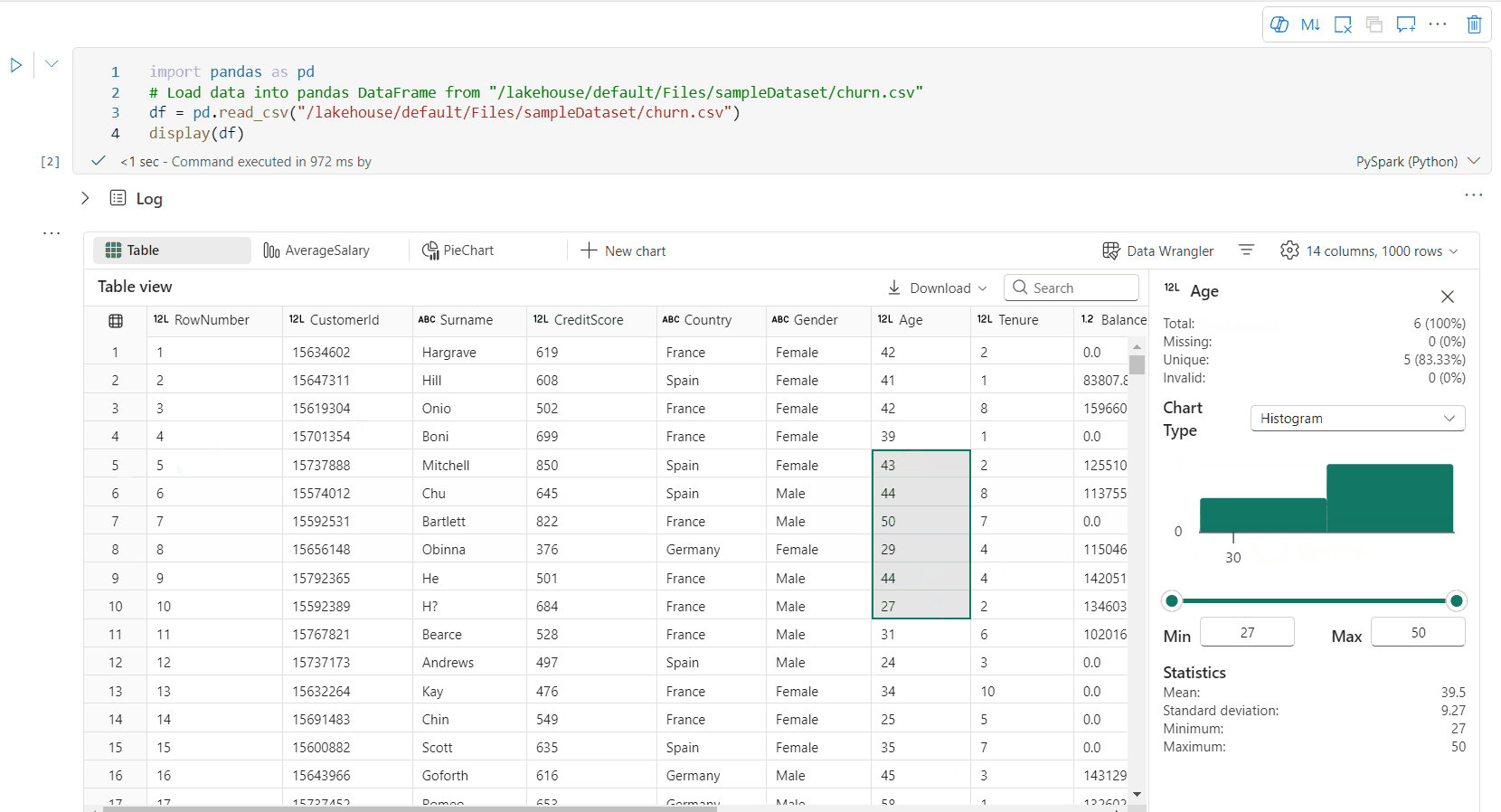
Alapértelmezés szerint a Táblázat nézet jelenik meg, amikor egy Fabric-jegyzetfüzetben a display() parancsot használja. A gazdag adatkeret-előnézet intuitív, ingyenes kiválasztási funkciót kínál, amely rugalmas, interaktív kijelölési lehetőségek lehetővé tételével javítja az adatelemzési élményt. Ez a funkció lehetővé teszi a felhasználók számára, hogy könnyedén navigáljanak és felfedezzék az adatkereteket.
oszlop kijelölése
- egyoszlopos: Az oszlopfejlécre kattintva jelölje ki a teljes oszlopot.
- Több oszlop: Egyetlen oszlop kijelölése után nyomja le és tartsa lenyomva a Shift billentyűt, majd kattintson egy másik oszlopfejlécre több oszlop kijelöléséhez.
sorkijelölés
- Egyetlen sor: Klikkelj egy sor fejlécére az egész sor kijelöléséhez.
- Több sor: Egyetlen sor kijelölése után nyomja le és tartsa lenyomva a Shift billentyűt, majd kattintson egy másik sorfejlécre több sor kijelöléséhez.
Cellatartalom előnézete: Az egyes cellák tartalmának előnézetével gyorsan és részletesen áttekintheti az adatokat anélkül, hogy további kódot kellene írnia.
oszlopösszegző: Az adatok jellemzőinek gyors megértéséhez kérje le az egyes oszlopok összegzését, beleértve az adateloszlást és a fő statisztikákat.
Szabad terület kijelölése: A táblázat bármely folytonos szegmensének kiválasztásával áttekintheti a kijelölt cellák teljes számát és a kijelölt terület numerikus értékeit.
Kijelölt tartalom másolása: Minden kijelölési esetben gyorsan átmásolhatja a kijelölt tartalmat a Ctrl + C billentyűparanccsal. A kijelölt adatok CSV formátumban vannak másolva, így más alkalmazásokban is könnyen feldolgozhatók.

Adatprofilozási támogatás az Ellenőrző ablakon keresztül

A dataframe-et a Inspect gombra kattintva profilozhatja. Ez biztosítja az összesített adateloszlást, és megjeleníti az egyes oszlopok statisztikáit.
Az "Ellenőrzés" oldalsó panel minden kártyája a dataframe egy oszlopának megfelelően van megtervezve, részleteket tekinthet meg, ha rákattint a kártyára vagy kiválaszt egy oszlopot a táblázatban.
A cell részleteit megtekintheti a táblázat cellájára kattintva. Ez a funkció akkor hasznos, ha az adatkeret hosszú sztring típusú tartalmat tartalmaz.
Bővített Rich DataFrame-diagramnézet
A display() parancs továbbfejlesztett diagramnézete intuitívabb és dinamikusabb módot kínál az adatok vizualizációjához.
Főbb fejlesztések:
Többdiagramos támogatás: Egyetlen megjelenítési() kimeneti widgeten belül legfeljebb öt diagramot adhat hozzá az Új diagram lehetőség kiválasztásával, így egyszerűen összehasonlíthatja a különböző oszlopokat.
Intelligens diagramjavaslatok: A javasolt diagramok listájának lekérése a DataFrame alapján. Válasszon egy ajánlott vizualizációt, vagy hozzon létre egy egyéni diagramot az alapoktól.

Rugalmas testreszabás: Személyre szabhatja a vizualizációkat a kiválasztott diagramtípushoz igazodó, állítható beállításokkal.
Kategória Alapszintű beállítások Leírás Diagramtípus A megjelenítési funkció széles körű diagramtípust támogat, beleértve az oszlopdiagramokat, pontdiagramokat, vonaldiagramokat, kimutatástáblázat és továbbiakat. Cím Cím A diagram címe. Cím Alcím A diagram alcíme további leírásokkal. Adatok X-tengely Adja meg a diagram kulcsát. Adatok Y tengely Adja meg a diagram értékeit. Jelmagyarázat Jelmagyarázat mutatása Kapcsolja be/ki a jelmagyarázatot. Jelmagyarázat Pozíció Testreszabhatja a jelmagyarázat elhelyezkedését. Más Sorozatcsoport Használja ezt a konfigurációt a csoportok meghatározásához az aggregációhoz. Más Aggregálás Ezzel a módszerrel összesítheti az adatokat a vizualizációban. Más Halmozott Konfigurálja az eredmény megjelenítési stílusát. Más Hiányzó és NULL értékek A hiányzó vagy NULL diagramértékek megjelenítésének konfigurálása. Megjegyzés
Emellett megadhatja a megjelenített sorok számát is, az alapértelmezett 1000-es beállítással. A jegyzetfüzet megjelenítési kimeneti vezérlője legfeljebb 10 000 adatkeret sorának megtekintését és profilkészítését támogatja. Válassza az Aggregáció az összes eredmény felett lehetőséget, majd válassza az Alkalmaz lehetőséget a diagram generálásának alkalmazásához az egész adatkeretből. A Spark-feladat akkor aktiválódik, amikor a diagrambeállítás megváltozik. A számítás elvégzése és a diagram megjelenítése több percet is igénybe vehet.
Kategória Speciális beállítások Leírás Szín Téma Határozza meg a diagram téma színsémáját. X-tengely Címke Adjon meg egy címkét az X tengelyhez. X-tengely Skála Adja meg az X tengely méretarányának függvényét. X-tengely Tartomány Adja meg az X-tengely értéktartományát. Y tengely Címke Adjon meg egy címkét az Y tengelyhez. Y tengely Skála Adja meg az Y tengely méretezési függvényét. Y tengely Tartomány Adja meg az Y-tengely értéktartományát. Kijelző Címkék megjelenítése A diagramon megjeleníti/elrejti az eredménycímkéket. A konfigurációk módosításai azonnal érvénybe lépnek, és az összes konfiguráció automatikusan mentésre kerül a jegyzetfüzet tartalmában.
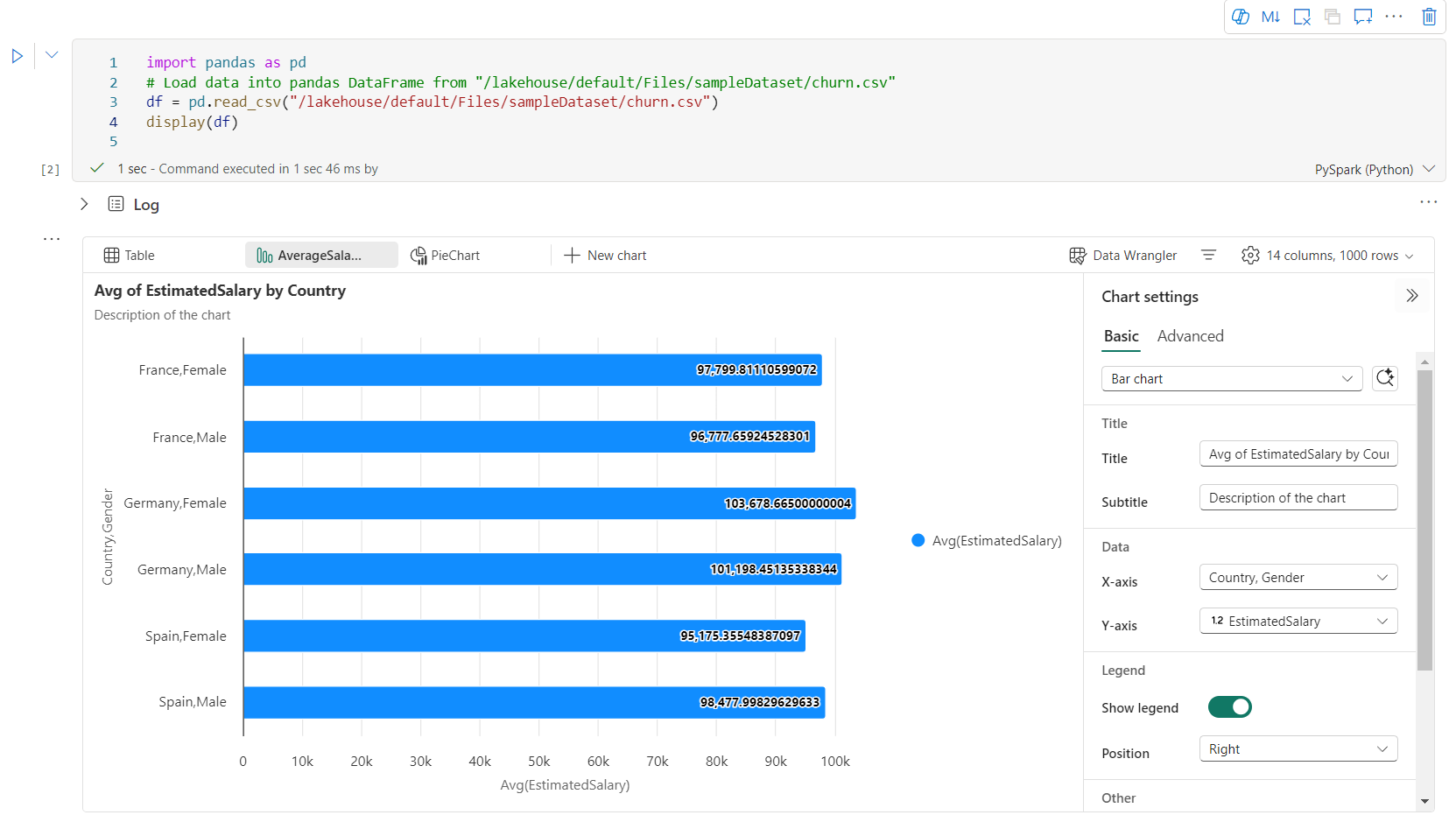
A diagramok egyszerűen átnevezhetők, duplikálhatók, törölhetők vagy áthelyezhetők a diagramok lap menüjében. A tabulátorok húzásával átrendezheti őket. A jegyzetfüzet megnyitásakor az első lap jelenik meg alapértelmezettként.
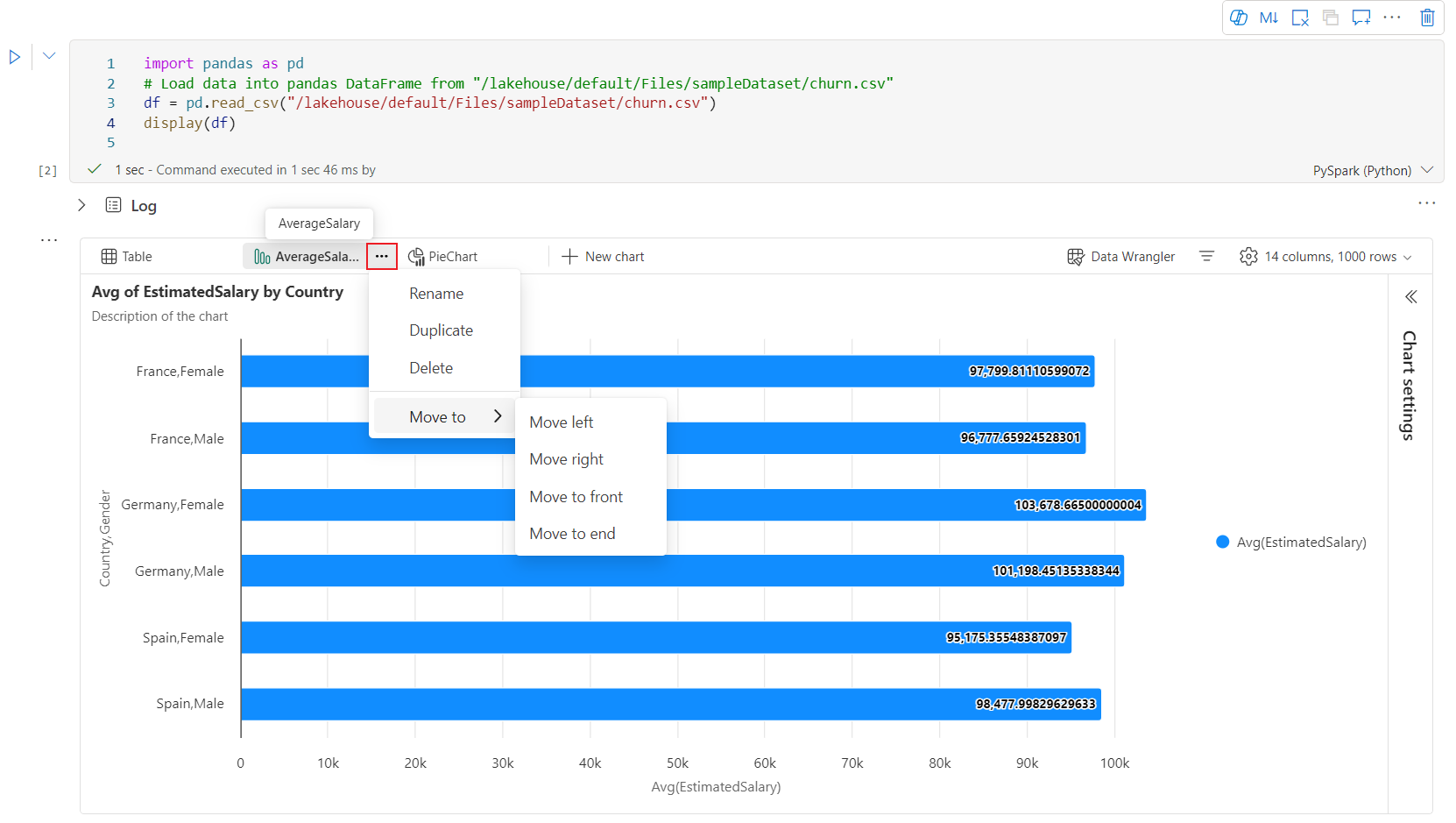
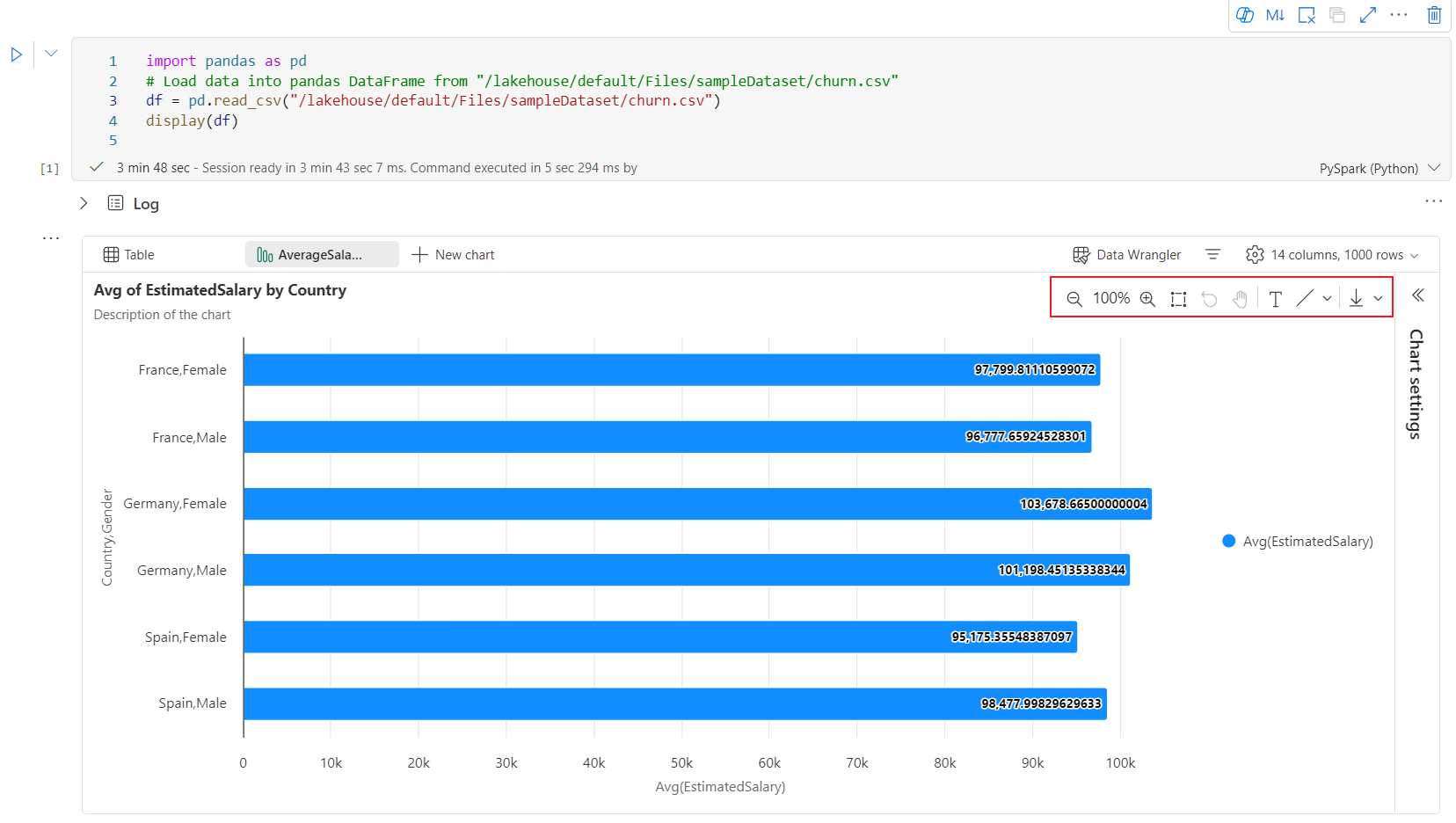
Az új diagram felületén interaktív eszköztár érhető el, amikor a felhasználó rámutat egy diagramra. Olyan műveletek támogatása, mint a nagyítás, a kicsinyítés, a kijelöléses nagyítás, az alaphelyzetbe állítás, a pásztázás, a jegyzet szerkesztése stb.
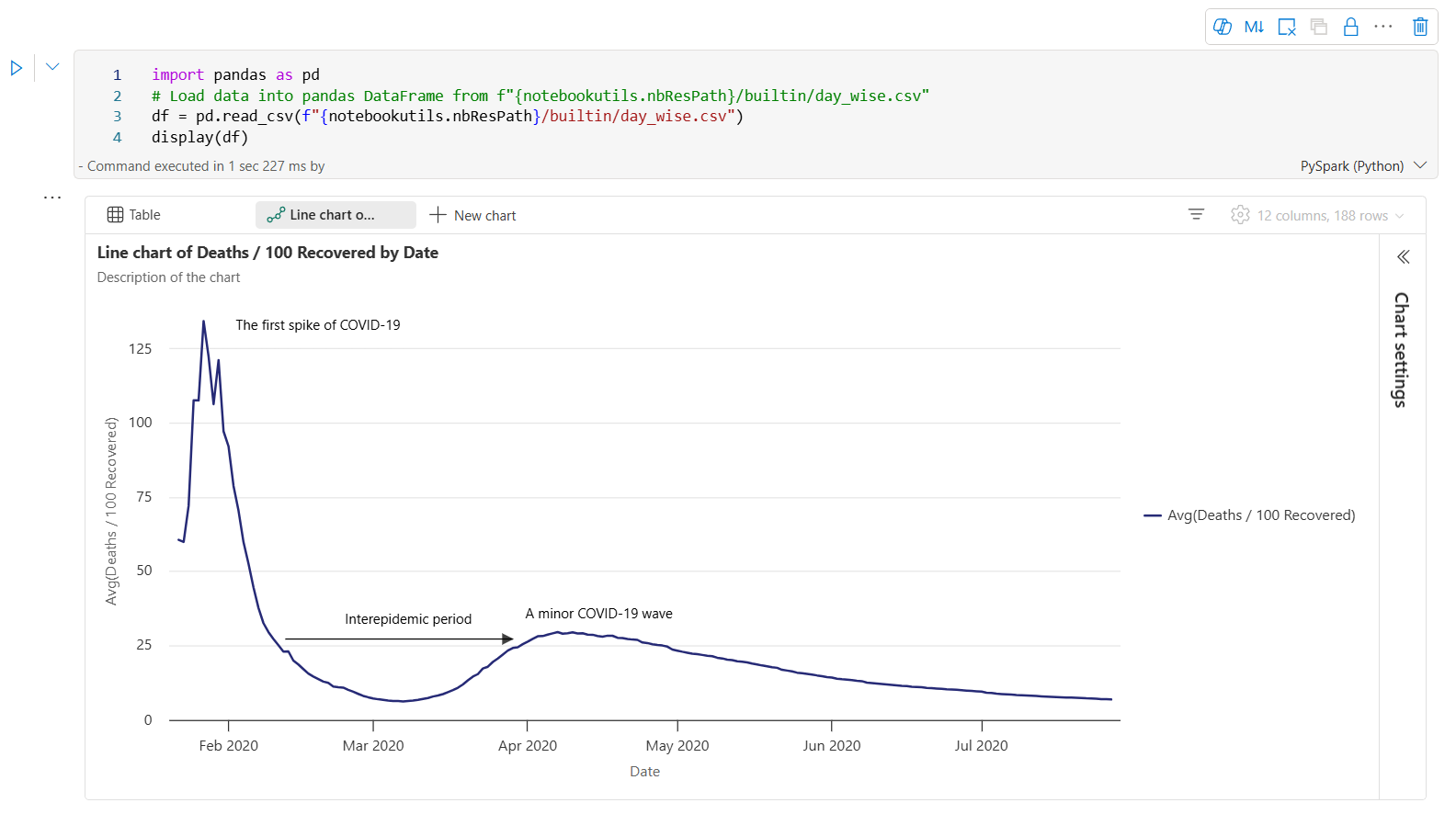
Íme egy példa a diagram jelölésére.




kijelzés() összefoglaló nézet
Az Apache Spark DataFrame adott statisztikai összesítésének ellenőrzéséhez használja a következőt: display(df, summary = true). Az összefoglaló tartalmazza az oszlop nevét, az oszloptípust, az egyedi értékeket és a hiányzó értékeket minden oszlop esetében. Azt is megteheti, hogy kiválaszt egy adott oszlopot, hogy megnézze annak minimum értékét, maximum értékét, átlagértékét és szórását.

displayHTML() beállítás
A Fabric jegyzetfüzetek támogatják a HTML grafikákat a displayHTML függvény használatával.
Az alábbi kép egy példa a vizualizációk D3.jshasználatával történő létrehozására.

A vizualizáció létrehozásához futtassa a következő kódot.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Power BI-jelentés beágyazása jegyzetfüzetbe
A Powerbiclient Python-csomag mostantól natív módon támogatott a Fabric-jegyzetfüzetekben. Nem szükséges semmilyen további beállítást elvégezni (például hitelesítési folyamatot) a Fabric notebook Spark runtime 3.4 esetében. Csak importáld powerbiclient, majd folytasd a felfedezést. Ha többet szeretne megtudni a powerbiclient csomag használatáról, tekintse meg a powerbiclient dokumentációját.
A Powerbiclient a következő fő funkciókat támogatja.
Render egy meglévő Power BI jelentést
A Power BI riportok könnyen beágyazhatók és kezelhetők a jegyzetfüzeteidben néhány sor kóddal.
A következő kép egy példát mutat be arra, hogyan jelenik meg egy meglévő Power BI jelentés.

Futtassa a következő kódot egy meglévő Power BI jelentés megjelenítéséhez.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Jelentés vizuális elemeinek létrehozása egy Spark DataFrame-ből
A jegyzetfüzetedben használhatsz Spark DataFrame-et, hogy gyorsan készíts betekintést nyújtó vizualizációkat. A beágyazott jelentésben a Mentés lehetőséget is kiválaszthatja, hogy jelentéselemzési elemet hozzon létre egy célmunkaterületen.
A következő kép egy példa a QuickVisualize() egy Spark DataFrame-ből.

Futtassa az alábbi kódot, hogy egy jelentést készítsen egy Spark DataFrame-ből.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Készítsen jelentésvizuálokat egy pandas DataFrame-ből.
Jelentéseket is készíthet a pandas DataFrame alapján a jegyzetfüzetben.
A következő kép a pandas DataFrame egy QuickVisualize() példáját mutatja be.

Futtassa az alábbi kódot, hogy egy jelentést készítsen egy Spark DataFrame-ből.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Népszerű könyvtárak
A Python aadatvizualizáció esetében több grafikus könyvtárat kínál, amelyek számos különböző funkcióval vannak ellátva. Alapértelmezés szerint minden Fabric-ben található Apache Spark pool tartalmaz egy összeválogatott és népszerű nyílt forráskódú könyvtárkészletet.
Matplotlib
A szabványos ábrázoló könyvtárakat, mint például a Matplotlib, renderelheti az egyes könyvtárak beépített renderelő funkcióival.
A következő kép a Matplotlib segítségével létrehozott oszlopdiagram készítésének példája.


Futtassa a következő mintakódot az oszlopdiagram megrajzolásához.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
HTML vagy interaktív könyvtárak, mint a bokeh, megjelenítésére használhatja a displayHTML(df).
Az alábbi kép egy példa arra, hogyan ábrázolhatunk szimbólumokat térképen a bokeh használatával.

Az alábbi példa kód futtatásával rajzolja meg ezt a képet.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Ábrázolás
HTML fájlokat vagy interaktív könyvtárakat, mint például a Plotly, megjeleníthetsz a displayHTML() használatával.
Az alábbi példa kód futtatásával rajzolja meg ezt a képet.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
A pandas DataFrames HTML-kimenetét alapértelmezett kimenetként tekintheti meg. A Fabric jegyzetfüzetek automatikusan megjelenítik a formázott HTML tartalmat.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df