Apache Spark-tanácsadó a jegyzetfüzetekkel kapcsolatos valós idejű tanácsadáshoz
Az Apache Spark-tanácsadó elemzi az Apache Spark által futtatott parancsokat és kódot, és valós idejű tanácsokat jelenít meg a notebook-futtatásokhoz. Az Apache Spark advisor beépített mintákkal segíti a felhasználókat a gyakori hibák elkerülésében. Javaslatokat tesz a kódoptimalizálásra, elvégzi a hibaelemzést, és megkeresi a hibák kiváltó okát.
Beépített tanácsok
Az Impulzussal integrált Spark Advisor beépített mintákat biztosít az Apache Spark-alkalmazások problémáinak észleléséhez és megoldásához. Ez a cikk az eszköz néhány mintáját ismerteti.
A Legutóbbi futtatások panelt a szükséges tanácsok típusa alapján nyithatja meg.
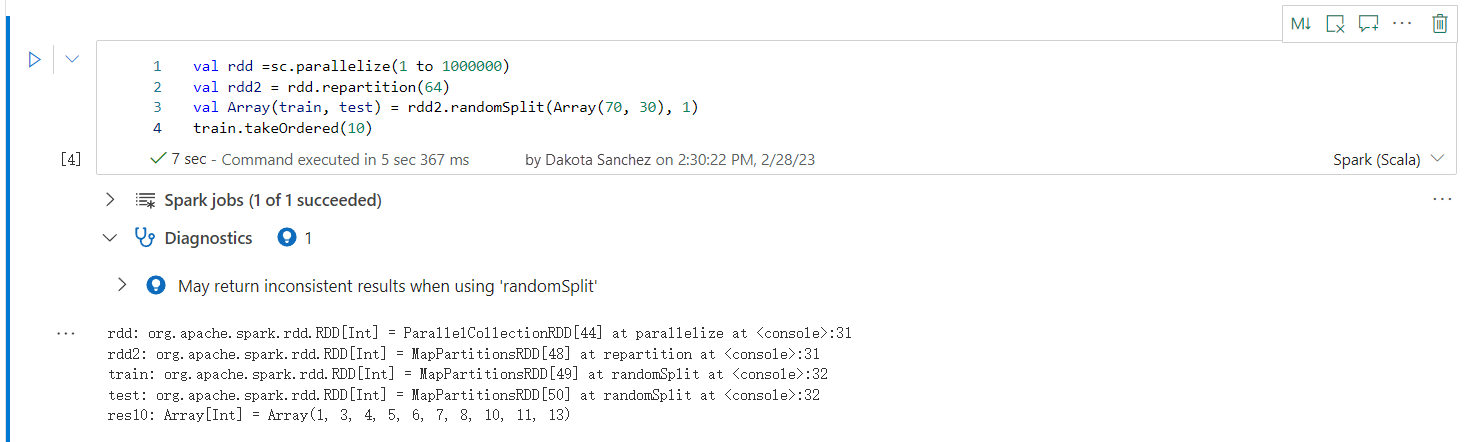
Inkonzisztens eredményeket adhat vissza a "randomSplit" használatakor
Inkonzisztens vagy pontatlan eredmények jelenhetnek meg a randomSplit metódus használatakor. A randomSplit() metódus használata előtt használja az Apache Spark (RDD) gyorsítótárazását.
A randomSplit() metódus egyenértékű az adatkereten többszöri minta() végrehajtásával. Ahol az egyes minták újrafedik, particionálják és rendezik az adatkeretet a partíciókon belül. A partíciók közötti adateloszlás és a rendezési sorrend fontos a randomSplit() és a sample() esetében is. Ha az adatok újrabetöltésekor megváltozik, előfordulhat, hogy ismétlődő vagy hiányzó értékek vannak a felosztások között. És ugyanaz a minta, amely ugyanazt a vetőmagot használja, eltérő eredményeket eredményezhet.
Előfordulhat, hogy ezek az inkonzisztenciák nem minden futtatás során fordulnak elő, hanem a teljes kizárásukhoz, az adatkeret gyorsítótárazásához, egy oszlop(ok) újraparticionálásához, vagy aggregátumfüggvények( például groupBy) alkalmazásához.
A tábla/nézet neve már használatban van
Egy nézet már létezik ugyanazzal a névvel, mint a létrehozott tábla, vagy már létezik olyan tábla, amelynek a neve megegyezik a létrehozott nézet nevével. Ha ezt a nevet lekérdezésekben vagy alkalmazásokban használják, a rendszer csak a nézetet adja vissza, függetlenül attól, hogy melyiket hozta létre először. Az ütközések elkerülése érdekében nevezze át a táblázatot vagy a nézetet.
Nem sikerült felismerni egy tippet
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Nem található megadott relációs név(ek)
Nem található a tippben megadott kapcsolat(ok). Ellenőrizze, hogy a reláció(k) helyesen vannak-e beírva, és elérhetők-e a tipp hatókörén belül.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Egy tipp a lekérdezésben megakadályozza egy másik tipp alkalmazását
A kijelölt lekérdezés tartalmaz egy tippet, amely megakadályozza egy másik tipp alkalmazását.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
A "spark.advise.divisionExprConvertRule.enable" engedélyezése a kerekítési hibák propagálásának csökkentése érdekében
Ez a lekérdezés dupla típusú kifejezést tartalmaz. Javasoljuk, hogy engedélyezze a "spark.advise.divisionExprConvertRule.enable" konfigurációt, amely segíthet csökkenteni az osztáskifejezéseket, és csökkenteni a kerekítési hibák propagálását.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
A "spark.advise.nonEqJoinConvertRule.enable" engedélyezése a lekérdezési teljesítmény javítása érdekében
Ez a lekérdezés az "Or" feltétel miatt időigényes illesztést tartalmaz a lekérdezésben. Javasoljuk, hogy engedélyezze a "spark.advise.nonEqJoinConvertRule.enable" konfigurációt, amely segíthet az "Or" feltétel által aktivált illesztés SMJ-vé vagy BHJ-vé konvertálásában a lekérdezés felgyorsításához.
Felhasználó felület
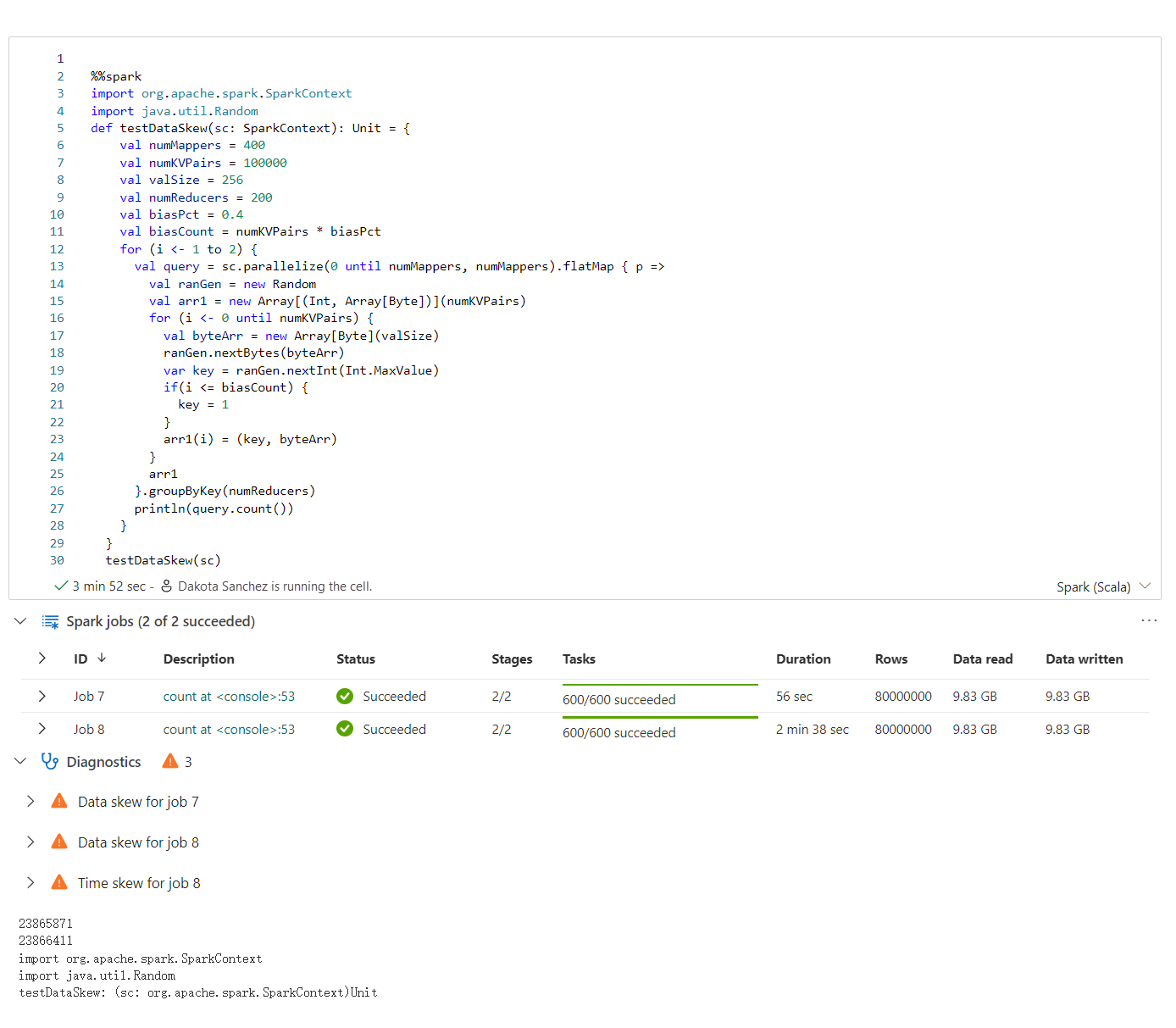
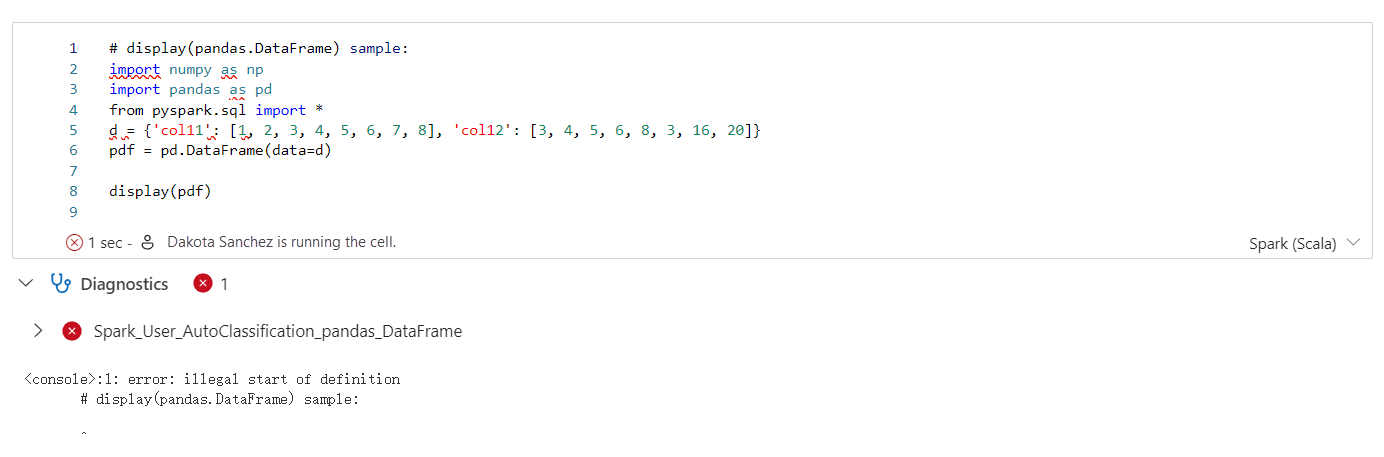
Az Apache Spark-tanácsadó valós időben jeleníti meg a jegyzetfüzet cellakimenetében megjelenő tanácsokat, beleértve az információkat, a figyelmeztetéseket és a hibákat.
Info
Figyelmeztetés
Hiba
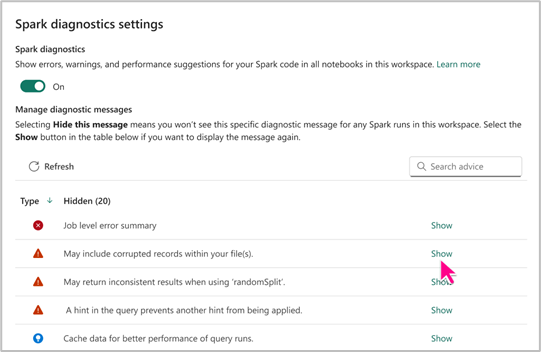
Spark Advisor-beállítás
A Spark-tanácsadó beállítás lehetővé teszi, hogy az igényeinek megfelelően megjelenítse vagy elrejtse a Spark-tanácsok adott típusait. Emellett rugalmasan engedélyezheti vagy letilthatja a Spark Advisort a jegyzetfüzeteihez egy munkaterületen belül, a beállítások alapján.
A Spark Advisor beállításait a Hálójegyzetfüzet szintjén érheti el, hogy kihasználhassa annak előnyeit, és hatékony jegyzetfüzet-létrehozási élményt biztosítson.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: