Recept: Azure AI-szolgáltatások – Többváltozós anomáliadetektálás
Ez a recept bemutatja, hogyan használhatja a SynapseML és az Azure AI-szolgáltatásokat az Apache Sparkban a többváltozós anomáliadetektáláshoz. A többváltozós anomáliadetektálás lehetővé teszi a rendellenességek észlelését számos változó vagy idősor között, figyelembe véve a különböző változók közötti összes korrelációt és függőséget. Ebben a forgatókönyvben a SynapseML használatával tanítunk be egy modellt a többváltozós anomáliadetektáláshoz az Azure AI-szolgáltatásokkal, majd a modell segítségével többváltozós anomáliákat következtetünk egy olyan adathalmazban, amely három IoT-érzékelő szintetikus méréseit tartalmazza.
Fontos
2023. szeptember 20-tól nem hozhat létre új anomáliadetektor erőforrásokat. A anomáliadetektor szolgáltatás 2026. október 1-jén megszűnik.
Az Azure AI-anomáliadetektor kapcsolatos további információkért tekintse meg ezt a dokumentációs oldalt.
Előfeltételek
- Azure-előfizetés – Ingyenes létrehozás
- Csatolja a jegyzetfüzetet egy tóházhoz. A bal oldalon válassza a Hozzáadás lehetőséget egy meglévő tóház hozzáadásához vagy egy tóház létrehozásához.
Beállítás
Kövesse az utasításokat, és hozzon létre egy erőforrást Anomaly Detector az Azure Portalon, vagy másik lehetőségként az Azure CLI-vel is létrehozhatja ezt az erőforrást.
A beállítás Anomaly Detectorután megismerheti a különböző űrlapok adatainak kezelésére vonatkozó módszereket. Az Azure AI szolgáltatáskatalógusa számos lehetőséget kínál: Látás, Beszéd, Nyelv, Webes keresés, Döntés, Fordítás és Dokumentumintelligencia.
Anomáliadetektor-erőforrás létrehozása
- Az Azure Portalon válassza a Létrehozás lehetőséget az erőforráscsoportban, majd írja be a anomáliadetektor. Válassza ki a anomáliadetektor erőforrást.
- Adjon nevet az erőforrásnak, és ideális esetben ugyanazt a régiót használja, mint a többi erőforráscsoport. Használja az alapértelmezett beállításokat a többihez, majd válassza a Véleményezés + Létrehozás , majd a Létrehozás lehetőséget.
- A anomáliadetektor erőforrás létrehozása után nyissa meg, és válassza ki a
Keys and Endpointsbal oldali navigációs panelt. Másolja a anomáliadetektor erőforrás kulcsát aANOMALY_API_KEYkörnyezeti változóba, vagy tárolja aanomalyKeyváltozóban.
Tárfiók-erőforrás létrehozása
A köztes adatok mentéséhez létre kell hoznia egy Azure Blob Storage-fiókot. Ebben a tárfiókban hozzon létre egy tárolót a köztes adatok tárolásához. Jegyezze fel a tároló nevét, és másolja a kapcsolati sztring a tárolóba. Később szüksége lesz rá a változó és a containerName környezeti változó feltöltéséhez BLOB_CONNECTION_STRING .
Adja meg a szolgáltatáskulcsokat
Kezdjük a szolgáltatáskulcsok környezeti változóinak beállításával. A következő cella az ANOMALY_API_KEY Azure Key Vaultban tárolt értékek alapján állítja be a környezeti és BLOB_CONNECTION_STRING a környezeti változókat. Ha ezt az oktatóanyagot a saját környezetében futtatja, a folytatás előtt mindenképpen állítsa be ezeket a környezeti változókat.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Most beolvashatja a környezeti és BLOB_CONNECTION_STRING a ANOMALY_API_KEY környezeti változókat, és beállíthatja a változókat és location a containerName változókat.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Először a tárfiókhoz csatlakozunk, hogy az anomáliadetektor menthesse a köztes eredményeket:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Importáljuk az összes szükséges modult.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Most olvassuk be a mintaadatokat egy Spark DataFrame-be.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Most már létrehozhatunk egy estimator objektumot, amelyet a modell betanításakor használunk. A betanítási adatok kezdési és befejezési idejét határozzuk meg. Meg is adhatja a használni kívánt bemeneti oszlopokat, valamint az időbélyegeket tartalmazó oszlop nevét. Végül megadjuk az anomáliadetektálási tolóablakban használandó adatpontok számát, és a kapcsolati sztring az Azure Blob Storage-fiókra állítjuk.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Most, hogy létrehoztuk a estimatorelemet, illessük be az adatokhoz:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Amikor az előző cellában hívtunk .show(5) , az megmutatta az adatkeret első öt sorát. Az eredmények mind null azért voltak, mert nem voltak a következtetési ablakban.
Ha csak a kikövetkeztetett adatok eredményeit szeretné megjeleníteni, jelölje ki a szükséges oszlopokat. Ezután növekvő sorrendben rendezhetjük az adatkeret sorait, és szűrhetjük az eredményt, hogy csak a következtetési ablak tartományában lévő sorokat jelenítsük meg. Esetünkben inferenceEndTime ugyanaz, mint az adatkeret utolsó sora, ezért ezt figyelmen kívül hagyhatja.
Végül az eredmények jobb ábrázolásához konvertálja a Spark-adatkeretet Pandas-adatkeretté.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Formázza az contributors egyes érzékelők hozzájárulási pontszámát tároló oszlopot az észlelt anomáliákhoz. A következő cella formázja ezeket az adatokat, és az egyes érzékelők hozzájárulási pontszámát saját oszlopra osztja.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Nagyszerű! Most már rendelkezünk az 1, 2 és 3 érzékelők hozzájárulási pontszámával a series_0, series_1és series_2 az oszlopokban.
Futtassa a következő cellát az eredmények ábrázolásához. A minSeverity paraméter a ábrázolni kívánt anomáliák minimális súlyosságát határozza meg.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
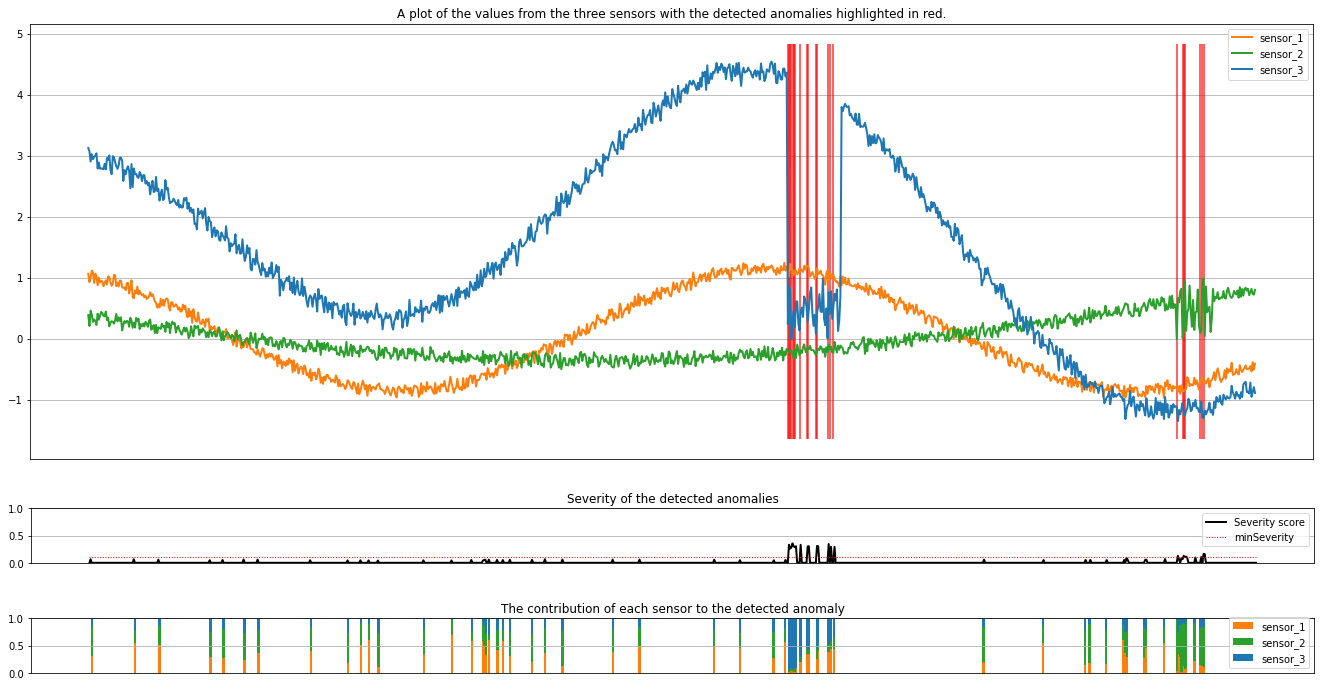
A diagramok narancssárga, zöld és kék színnel jelenítik meg az érzékelők nyers adatait (a következtetési ablakban). Az első ábrán látható piros függőleges vonalak az észlelt anomáliákat mutatják, amelyek súlyossága nagyobb vagy egyenlő minSeverity.
A második ábrán az összes észlelt rendellenesség súlyossági pontszáma látható, a pontozott piros vonalban pedig a minSeverity küszöbérték látható.
Végül az utolsó ábra az egyes érzékelők adatainak az észlelt anomáliákhoz való hozzájárulását mutatja. Segít diagnosztizálni és megérteni az egyes anomáliák legvalószínűbb okát.