Oktatóanyag: Gépi hibaészlelési modell létrehozása, kiértékelése és pontszáma
Ez az oktatóanyag a Synapse Adattudomány munkafolyamatának végpontok közötti példáját mutatja be a Microsoft Fabricben. A forgatókönyv gépi tanulást használ a hibadiagnózis szisztematikusabb megközelítéséhez, a problémák proaktív azonosításához és a tényleges gépi meghibásodás előtti műveletekhez. A cél annak előrejelzése, hogy a gép a folyamat hőmérséklete, a forgási sebesség stb. alapján tapasztal-e meghibásodást.
Ez az oktatóanyag az alábbi lépéseket ismerteti:
- Egyéni kódtárak telepítése
- Adatok betöltése és feldolgozása
- Az adatok megismerése feltáró adatelemzéssel
- A scikit-learn, a LightGBM és az MLflow használatával gépi tanulási modelleket taníthat be, a Fabric autologging funkciójával pedig nyomon követheti a kísérleteket
- A betanított modellek pontszáma a Háló
PREDICTfunkcióval, a legjobb modell mentése és a modell betöltése előrejelzésekhez - A betöltött modell teljesítményének megjelenítése Power BI-vizualizációkkal
Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
A kezdőlap bal oldalán található élménykapcsolóval válthat a Synapse Adattudomány felületre.

- Szükség esetén hozzon létre egy Microsoft Fabric-tóházat a Microsoft Fabricben a Tóház létrehozása című cikkben leírtak szerint.
Követés jegyzetfüzetben
A jegyzetfüzetben az alábbi lehetőségek közül választhat:
- Nyissa meg és futtassa a beépített jegyzetfüzetet a Adattudomány felületen
- Jegyzetfüzet feltöltése a GitHubról a Adattudomány felületre
A beépített jegyzetfüzet megnyitása
A mintagép-hibajegyzetfüzet ezt az oktatóanyagot kíséri.
Az oktatóanyag beépített mintajegyzetfüzetének megnyitása a Synapse Adattudomány felületén:
Nyissa meg a Synapse Adattudomány kezdőlapját.
Válassza a Minta használata lehetőséget.
Válassza ki a megfelelő mintát:
- Ha a minta Python-oktatóanyaghoz készült, az alapértelmezett Végpontok közötti munkafolyamatok (Python) lapon.
- A végpontok közötti munkafolyamatok (R) lapról, ha a minta R-oktatóanyaghoz készült.
- A Gyors oktatóanyagok lapon, ha a minta egy gyors oktatóanyaghoz készült.
A kód futtatása előtt csatoljon egy lakehouse-t a jegyzetfüzethez .
A jegyzetfüzet importálása a GitHubról
Az AISample – Prediktív karbantartási jegyzetfüzet ezt az oktatóanyagot kíséri.
Az oktatóanyaghoz mellékelt jegyzetfüzet megnyitásához kövesse a Rendszer előkészítése adatelemzési oktatóanyagokhoz című témakör utasításait, és importálja a jegyzetfüzetet a munkaterületre.
Ha inkább erről a lapról másolja és illessze be a kódot, létrehozhat egy új jegyzetfüzetet.
A kód futtatása előtt mindenképpen csatoljon egy lakehouse-t a jegyzetfüzethez .
1. lépés: Egyéni kódtárak telepítése
A gépi tanulási modell fejlesztéséhez vagy az alkalmi adatelemzéshez előfordulhat, hogy gyorsan telepítenie kell egy egyéni kódtárat az Apache Spark-munkamenethez. A kódtárak telepítéséhez két lehetőség közül választhat.
- A jegyzetfüzet beágyazott telepítési képességeivel (
%pipvagy%conda) csak az aktuális jegyzetfüzetben telepíthet tárat. - Másik lehetőségként létrehozhat egy Fabric-környezetet, telepíthet nyilvános forrásokból származó kódtárakat, vagy feltölthet hozzá egyéni kódtárakat, majd a munkaterület rendszergazdája alapértelmezettként csatolhatja a környezetet a munkaterülethez. Ezután a környezet összes kódtára elérhetővé válik a munkaterület bármely jegyzetfüzetében és Spark-feladatdefiníciójában. A környezetekkel kapcsolatos további információkért tekintse meg a Környezetek létrehozását, konfigurálását és használatát a Microsoft Fabricben.
Ebben az oktatóanyagban %pip install a tárat telepítheti imblearn a jegyzetfüzetbe.
Feljegyzés
A PySpark-kernel futás után %pip install újraindul. Telepítse a szükséges kódtárakat, mielőtt bármilyen más cellát futtatna.
# Use pip to install imblearn
%pip install imblearn
2. lépés: Az adatok betöltése
Az adatkészlet egy gyártógép paramétereinek naplózását szimulálja az idő függvényében, ami gyakori az ipari beállításokban. Ez 10 000 adatpontból áll, amelyek sorként, oszlopként való funkciókkal tárolódnak. Többek között az alábbi funkciók érhetők el:
1 és 10000 közötti egyedi azonosító (UID)
Termékazonosító, amely egy L betűből (alacsony), M (közepes) vagy H betűből (magas esetén) áll, amely jelzi a termékminőségi variánst és egy variánsspecifikus sorozatszámot. Az alacsony, közepes és kiváló minőségű változatok az összes termék 60%-át, 30%-át, illetve 10%-át teszik ki.
Levegő hőmérséklete Kelvin fokban (K)
Folyamat hőmérséklete Kelvin-fokban
Forgási sebesség, percenkénti forgásban (RPM)
Nyomaték, Newton-Meters (Nm)
Szerszámkopás percek alatt. A H, M és L minőségi változatok 5, 3 és 2 perc szerszámkopásokat adnak hozzá a folyamatban használt szerszámhoz
A gép meghibásodási címkéje, amely jelzi, hogy a gép meghibásodott-e az adott adatponton. Az adott adatpont az alábbi öt független hibamód bármelyikével rendelkezhet:
- Eszköz elhasználódási hibája (TWF): a szerszám cseréje vagy meghibásodása véletlenszerűen kiválasztott szerszámkopáskor történik, 200 és 240 perc között
- Hőeloszlási hiba (HDF): a hőeloszlás folyamathibát okoz, ha a levegő hőmérséklete és a folyamat hőmérséklete között 8,6 K-nál kisebb a különbség, és a szerszám forgási sebessége kisebb, mint 1380 RPM
- Áramkimaradás (PWF): a nyomaték és a forgási sebesség szorzata (rad/s-ban) megegyezik a folyamathoz szükséges teljesítménnyel. A folyamat meghiúsul, ha ez a teljesítmény 3500 W alá esik, vagy meghaladja a 9000 W-ot
- Túllépési hiba (OSF): ha a szerszám kopása és nyomatéka meghaladja a 11 000 minimális Nm-t az L termékvariáns esetében (M esetén 12 000, H esetén 13 000), a folyamat túlterjedés miatt meghiúsul
- Véletlenszerű hibák (RNF): minden folyamat 0,1%-os meghibásodási eséllyel rendelkezik, a folyamat paramétereitől függetlenül
Feljegyzés
Ha a fenti hibamódok közül legalább az egyik igaz, a folyamat meghiúsul, és a "gép meghibásodása" felirat értéke 1. A gépi tanulási módszer nem tudja meghatározni, hogy melyik hibamód okozta a folyamathibát.
Töltse le az adathalmazt, és töltse fel a lakehouse-ba
Csatlakozás az Azure Open Datasets-tárolóba, és töltse be a prediktív karbantartási adatkészletet. Ez a kód letölti az adathalmaz nyilvánosan elérhető verzióját, majd egy Fabric lakehouse-ban tárolja:
Fontos
A futtatás előtt vegyen fel egy lakehouse-t a jegyzetfüzetbe. Ellenkező esetben hibaüzenet jelenik meg. A tóház hozzáadásáról további információt Csatlakozás tóházak és jegyzetfüzetek című témakörben talál.
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Miután letöltötte az adathalmazt a lakehouse-ba, Spark DataFrame-ként töltheti be:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
Ez a táblázat az adatok előnézetét mutatja be:
| UDI | Termékazonosító | Típus | Levegő hőmérséklete [K] | Folyamat hőmérséklete [K] | Forgási sebesség [rpm] | Nyomaték [Nm] | Szerszámkopás [min] | Cél | Hiba típusa |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | H | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Nincs hiba |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Nincs hiba |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Nincs hiba |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Nincs hiba |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Nincs hiba |
Spark DataFrame írása egy tóházi deltatáblába
Formázza az adatokat (például cserélje le a szóközöket aláhúzásokra), hogy megkönnyítse a Spark-műveleteket a következő lépésekben:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
Ez a táblázat a formázott oszlopnevekkel rendelkező adatok előnézetét mutatja be:
| UDI | Product_ID | Típus | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[perc] | Cél | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | H | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Nincs hiba |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Nincs hiba |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Nincs hiba |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Nincs hiba |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Nincs hiba |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
3. lépés: Adatok előfeldolgozása és feltáró adatelemzés végrehajtása
Konvertálja a Spark DataFrame-et pandas DataFrame-gé, hogy pandas-kompatibilis népszerű ábrázolási kódtárakat használjon.
Tipp.
Nagy adatkészlet esetén előfordulhat, hogy az adathalmaz egy részét be kell töltenie.
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
Az adathalmaz adott oszlopait szükség szerint lebegőpontos vagy egész szám típusúvá alakíthatja, a sztringeket ('L', , 'M') 'H'pedig numerikus értékekké (0, 1, ): 2
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
Adatok felfedezése vizualizációkon keresztül
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
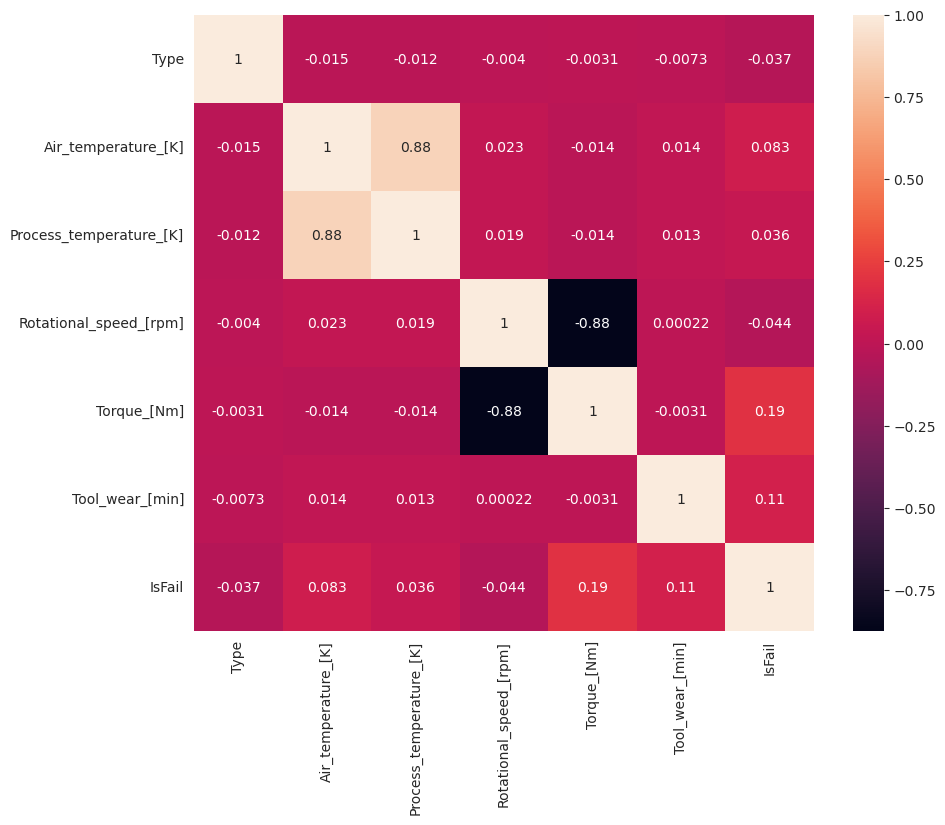
A hiba (IsFail) a vártnak megfelelően korrelál a kiválasztott funkciókkal (oszlopokkal). A korrelációs mátrix azt mutatja, hogy Air_temperature, Process_temperature, Rotational_speed, Torqueés Tool_wear a legmagasabb korrelációval rendelkezik a IsFail változóval.
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
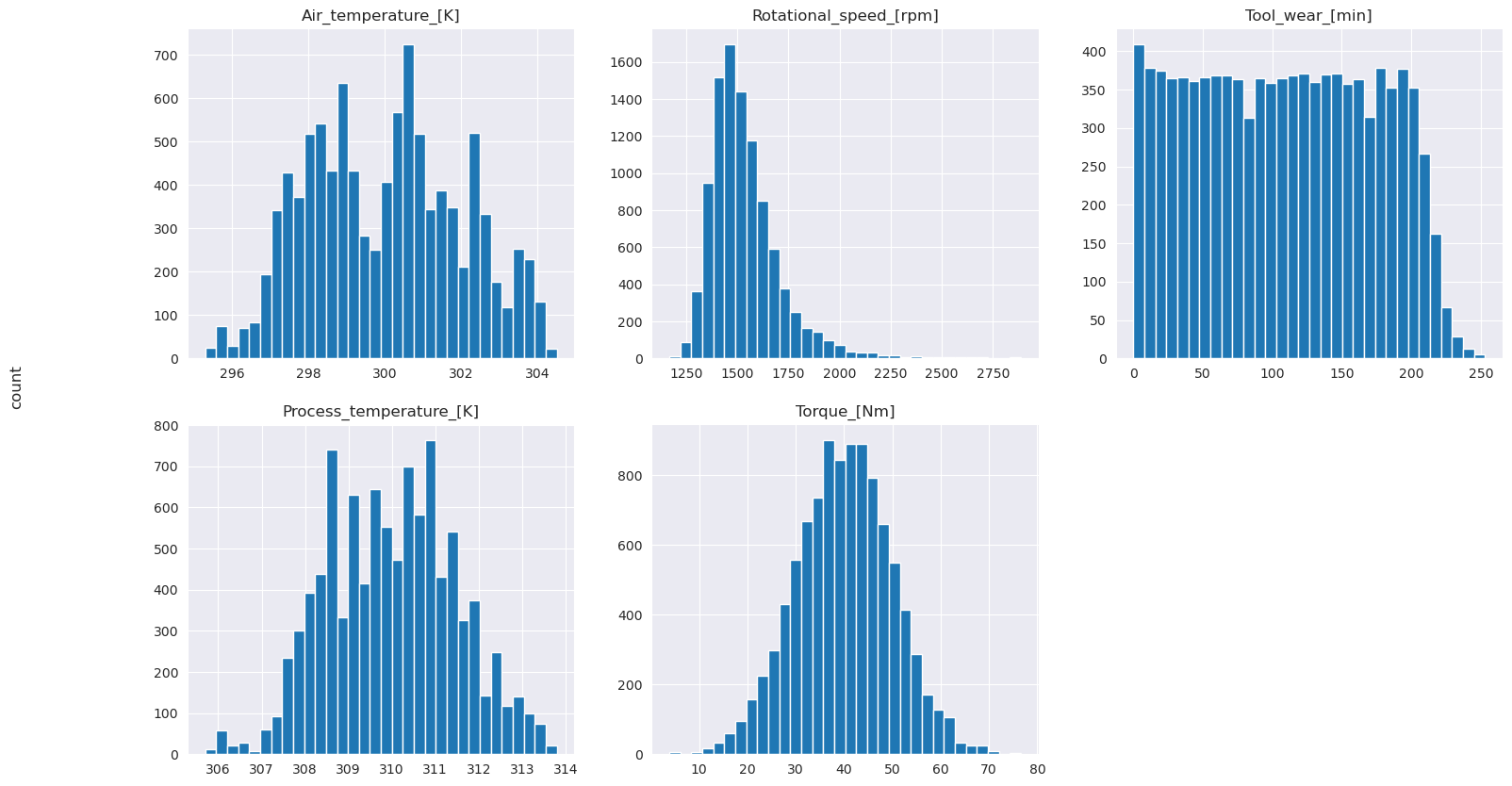
Ahogy a ábrázolt grafikonok mutatják, a Air_temperature, Process_temperature, Rotational_speed, Torqueés Tool_wear változók nem ritkák. Úgy tűnik, hogy jó folytonosságot biztosít a funkciótérben. Ezek a diagramok megerősítik, hogy egy gépi tanulási modell betanítása ezen az adatkészleten valószínűleg megbízható eredményeket eredményez, amelyek általánosíthatnak egy új adatkészletre.
A célváltozó vizsgálata az osztály kiegyensúlyozatlanságára
Számlálja meg a sikertelen és a nem használt gépek mintáinak számát, és vizsgálja meg az egyes osztályok adategyenlegét (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
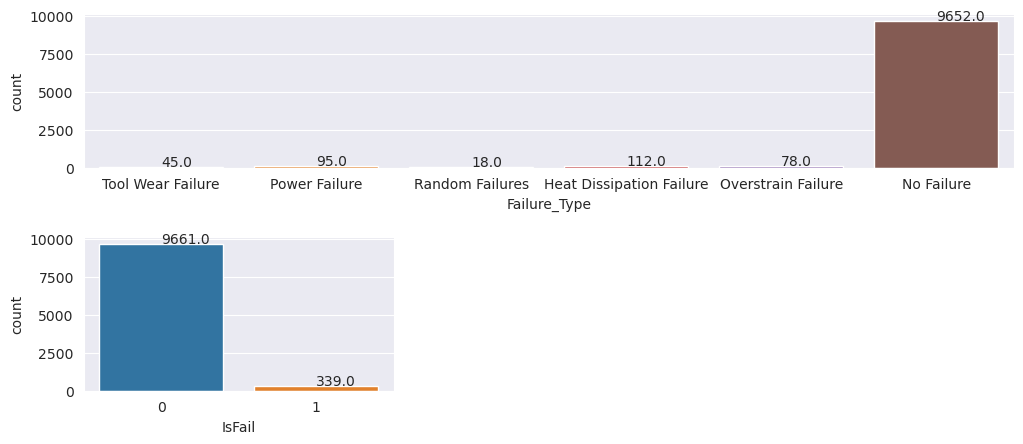
A diagramok azt jelzik, hogy a hibamentes osztály (a IsFail=0 második ábrán látható) alkotja a minták többségét. Kiegyensúlyozottabb betanítási adatkészlet létrehozásához használjon túlhasználati technikát:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Túlterhelés a betanítási adathalmaz osztályainak kiegyensúlyozásához
Az előző elemzés kimutatta, hogy az adathalmaz rendkívül kiegyensúlyozatlan. Ez a kiegyensúlyozatlanság problémává válik, mert a kisebbségi osztálynak túl kevés példája van ahhoz, hogy a modell hatékonyan megtanulja a döntési határt.
Az SMOTE meg tudja oldani a problémát. Az SMOTE egy széles körben használt túlmintavételi technika, amely szintetikus példákat hoz létre. Példákat hoz létre a kisebbségi osztályra az adatpontok közötti euklideszi távolság alapján. Ez a módszer eltér a véletlenszerű túlbélyegzéstől, mivel olyan új példákat hoz létre, amelyek nem csak duplikálják a kisebbségi osztályt. A módszer hatékonyabb módszer lesz a kiegyensúlyozatlan adathalmazok kezelésére.
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
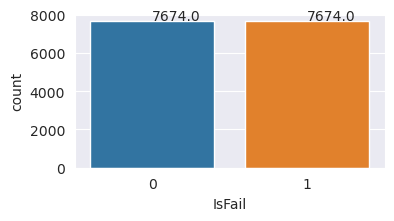
Sikeresen kiegyensúlyozza az adathalmazt. Most már áttérhet a modell betanítására.
4. lépés: A modellek betanítása és kiértékelése
Az MLflow regisztrálja a modelleket, leképezi és összehasonlítja a különböző modelleket, és kiválasztja a legjobb modellt előrejelzési célokra. A modell betanításához az alábbi három modellt használhatja:
- Véletlenszerű erdőosztályozó
- Logisztikai regressziós osztályozó
- XGBoost osztályozó
Véletlenszerű erdőosztályozó betanítása
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
A kimenetből mind a betanítási, mind a tesztadatkészletek F1-pontszámot, pontosságot és visszahívást eredményeznek, körülbelül 0,9-et a véletlenszerű erdőosztályozó használatakor.
Logisztikai regresszióosztályozó betanítása
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
XGBoost-osztályozó betanítása
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
5. lépés: A legjobb modell kiválasztása és a kimenetek előrejelzése
Az előző szakaszban három különböző osztályozót képezett be: véletlenszerű erdőt, logisztikai regressziót és XGBoostot. Most már lehetősége van arra, hogy programozott módon hozzáférjen az eredményekhez, vagy használja a felhasználói felületet (UI).
A felhasználói felület elérési útjának beállításához lépjen a munkaterületre, és szűrje a modelleket.
Válassza ki az egyes modelleket a modell teljesítményének részleteiért.
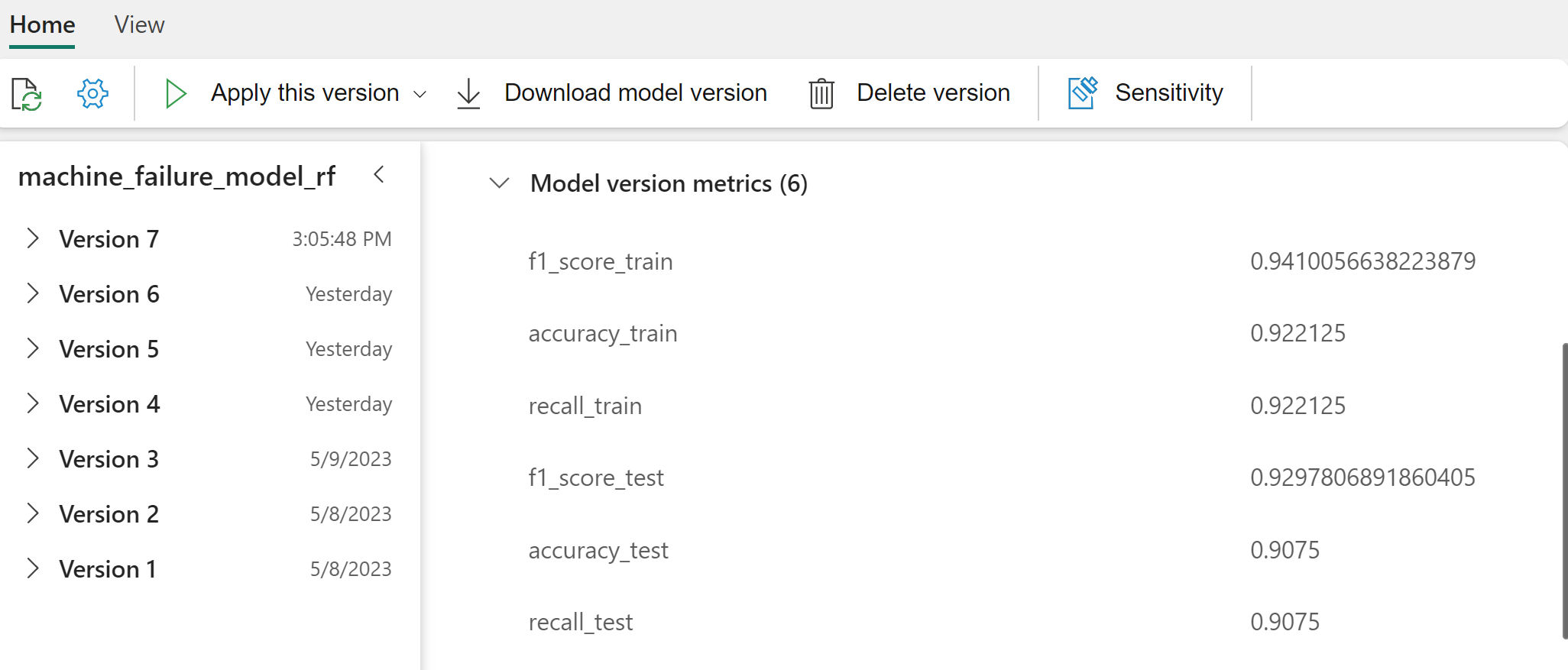
Ez a példa bemutatja, hogyan lehet programozott módon hozzáférni a modellekhez az MLflow-on keresztül:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
Bár az XGBoost a legjobb eredményt adja a betanítási csoportban, rosszul teljesít a tesztadatkészleten. Ez a gyenge teljesítmény túlillesztésre utal. A logisztikai regressziós osztályozó rosszul teljesít mind a betanítási, mind a tesztelési adatkészleteken. Összességében a véletlenszerű erdő jó egyensúlyt teremt a betanítási teljesítmény és a túlillesztés elkerülése között.
A következő szakaszban válassza ki a regisztrált véletlenszerű erdőmodellt, és végezzen előrejelzést a PREDICT funkcióval:
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
MLFlowTransformer A modell következtetésre való betöltéséhez létrehozott objektummal a Transformer API-val pontszámot adhat a modellnek a tesztadatkészleten:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
Ez a táblázat a kimenetet mutatja:
| Típus | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[perc] | Előrejelzések |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639,0 | 30,4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36,8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38,8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24,0 | 221.0 | 0 |
| 2 | 297.8 | 307.5 | 1631,0 | 31,3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51,0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25,6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29,9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45,8 | 80,0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26,0 | 37,0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431,0 | 51.3 | 57,0 | 0 |
| 0 | 299.6 | 310.2 | 1468,0 | 48,0 | 9.0 | 0 |
Mentse az adatokat a tóházba. Az adatok ezután elérhetővé válnak a későbbi felhasználásokhoz – például egy Power BI-irányítópulthoz.
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
6. lépés: Üzleti intelligencia megtekintése vizualizációkkal a Power BI-ban
Az eredmények megjelenítése offline formátumban, Power BI-irányítópulttal.
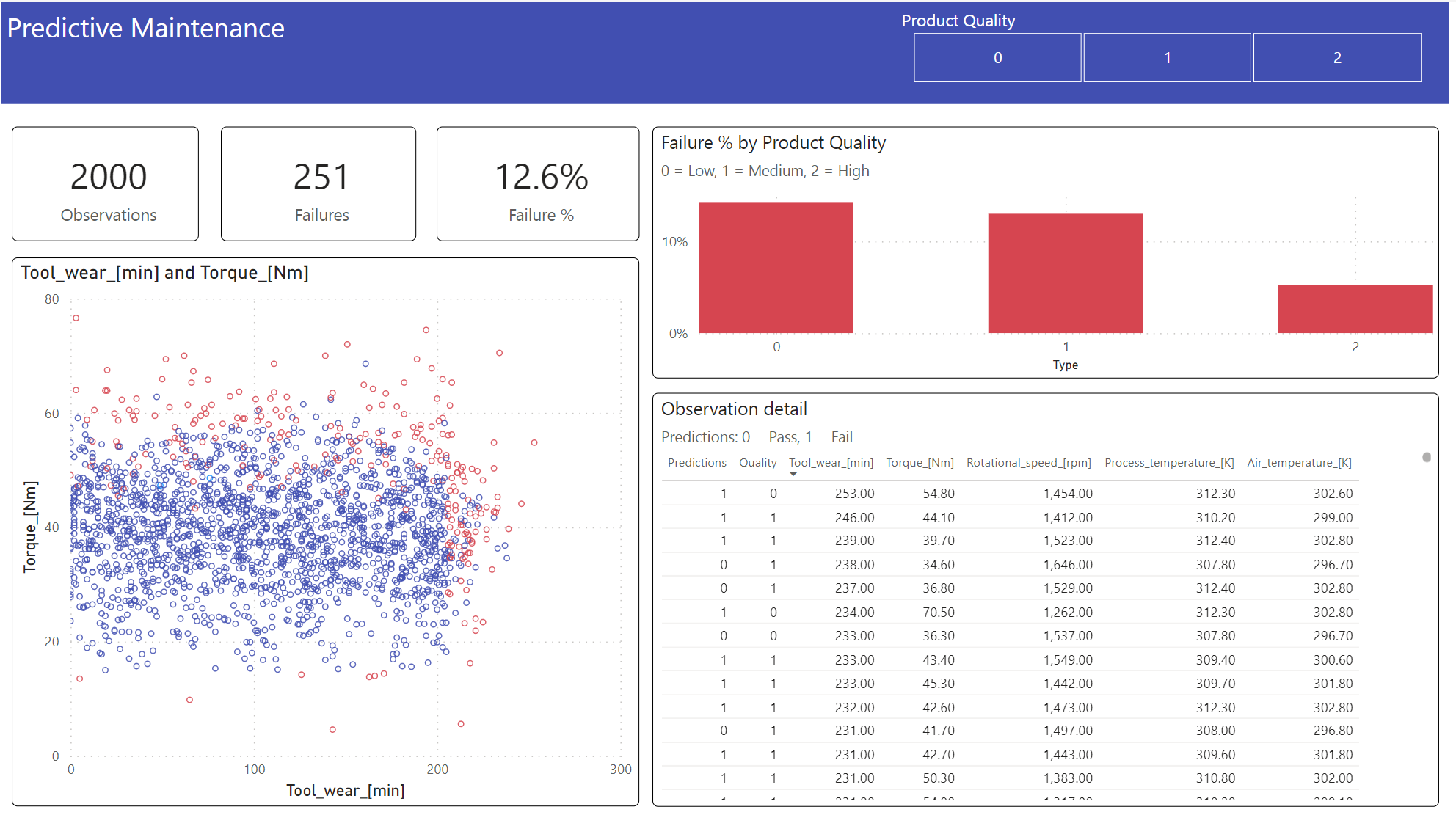
Az irányítópult ezt mutatja, Tool_wear és Torque észrevehető határt hoz létre a sikertelen és a nem ismert esetek között, a 2. lépés korábbi korrelációs elemzésétől elvárt módon.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: