Oktatóanyag: Javaslati rendszer létrehozása, kiértékelése és pontszáma
Ez az oktatóanyag a Synapse Adattudomány munkafolyamatának végpontok közötti példáját mutatja be a Microsoft Fabricben. A forgatókönyv létrehoz egy modellt az online könyvjavaslatokhoz.
Ez az oktatóanyag az alábbi lépéseket ismerteti:
- Adatok feltöltése egy tóházba
- Feltáró elemzés végrehajtása az adatokon
- Modell betanítása és naplózása az MLflow használatával
- A modell betöltése és előrejelzések készítése
Számos javaslati algoritmus érhető el. Ez az oktatóanyag az Alternating Least Squares (ALS) mátrix factorization algoritmust használja. Az ALS egy modellalapú együttműködési szűrési algoritmus.

Az ALS az R minősítési mátrixot két alsóbbrendű mátrix szorzataként próbálja megbecsülni, Ön és V. Itt, R = U * Vt. Ezeket a közelítéseket általában faktormátricáknak nevezzük.
Az ALS-algoritmus iteratív. Minden iteráció az egyik tényező-mátrix állandót tartalmazza, míg a másikat a legkisebb négyzetek metódusával oldja meg. Ezután megtartja az újonnan megoldott faktormátrix-állandót, miközben a másik faktormátrixot is megoldja.

Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
A kezdőlap bal oldalán található élménykapcsolóval válthat a Synapse Adattudomány felületre.

- Szükség esetén hozzon létre egy Microsoft Fabric-tóházat a Microsoft Fabricben a Tóház létrehozása című cikkben leírtak szerint.
Követés jegyzetfüzetben
A jegyzetfüzetben az alábbi lehetőségek közül választhat:
- Nyissa meg és futtassa a beépített jegyzetfüzetet a Synapse Adattudomány felületen
- Jegyzetfüzet feltöltése a GitHubról a Synapse Adattudomány felületére
A beépített jegyzetfüzet megnyitása
Az oktatóanyaghoz a könyvjavaslat-mintajegyzetfüzet is hozzá van kísérve.
Az oktatóanyag beépített mintajegyzetfüzetének megnyitása a Synapse Adattudomány felületén:
Nyissa meg a Synapse Adattudomány kezdőlapját.
Válassza a Minta használata lehetőséget.
Válassza ki a megfelelő mintát:
- Ha a minta Python-oktatóanyaghoz készült, az alapértelmezett Végpontok közötti munkafolyamatok (Python) lapon.
- A végpontok közötti munkafolyamatok (R) lapról, ha a minta R-oktatóanyaghoz készült.
- A Gyors oktatóanyagok lapon, ha a minta egy gyors oktatóanyaghoz készült.
A kód futtatása előtt csatoljon egy lakehouse-t a jegyzetfüzethez .
A jegyzetfüzet importálása a GitHubról
Az AIsample – Book Recommendation.ipynb jegyzetfüzet ezt az oktatóanyagot kíséri.
Az oktatóanyaghoz mellékelt jegyzetfüzet megnyitásához kövesse a Rendszer előkészítése adatelemzési oktatóanyagokhoz című témakör utasításait, és importálja a jegyzetfüzetet a munkaterületre.
Ha inkább erről a lapról másolja és illessze be a kódot, létrehozhat egy új jegyzetfüzetet.
A kód futtatása előtt mindenképpen csatoljon egy lakehouse-t a jegyzetfüzethez .
1. lépés: Az adatok betöltése
A könyvajánlási adatkészlet ebben a forgatókönyvben három különálló adatkészletből áll:
Books.csv: Egy nemzetközi standard könyvszám (ISBN) azonosítja az egyes könyveket, és a már eltávolított dátumok érvénytelenek. Az adatkészlet tartalmazza a címet, a szerzőt és a közzétevőt is. Több szerzőt tartalmazó könyv esetén a Books.csv fájl csak az első szerzőt listázza. Az URL-címek az Amazon webhely erőforrásaira mutatnak a borítóképekhez három méretben.
ISBN Könyvcím Könyv-szerző Közzététel éve Publisher Image-URL-S Image-URL-M Image-URL-l 0195153448 Klasszikus mitológia Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Kanada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Az egyes könyvek értékelése explicit (a felhasználók által megadott, 1-10-ig skálán) vagy implicit (felhasználói bevitel nélkül figyelhető meg, és 0 jelzi).
Felhasználó-azonosító ISBN Könyvbesorolás 276725 034545104X 0 276726 0155061224 5 Users.csv: A felhasználói azonosítók anonimizáltak és egész számokra vannak leképezve. A demográfiai adatok – például a hely és az életkor – rendelkezésre állnak. Ha ezek az adatok nem érhetők el, ezek az értékek a következők
null: .Felhasználó-azonosító Hely Kor 0 "nyc new york usa" 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Adja meg ezeket a paramétereket, hogy ezt a jegyzetfüzetet különböző adatkészletekkel is meg tudja adni:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Adatok letöltése és tárolása egy tóházban
Ez a kód letölti az adathalmazt, majd a lakehouse-ban tárolja.
Fontos
A futtatás előtt mindenképpen vegyen fel egy lakehouse-t a jegyzetfüzetbe. Ellenkező esetben hibaüzenet jelenik meg.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Az MLflow-kísérlet nyomon követésének beállítása
Ezzel a kóddal állíthatja be az MLflow-kísérlet nyomon követését. Ez a példa letiltja az automatikus kitöltést. További információkért lásd a Microsoft Fabric autologging című cikkét.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Adatok olvasása a lakehouse-ból
Miután a megfelelő adatokat elhelyezte a lakehouse-ban, olvassa el a három adathalmazt a jegyzetfüzet különálló Spark DataFrame-jeibe. A kód fájlútvonalai a korábban definiált paramétereket használják.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
2. lépés: Feltáró adatelemzés végrehajtása
Nyers adatok megjelenítése
Fedezze fel a DataFrame-eket a display paranccsal. Ezzel a paranccsal megtekintheti a magas szintű DataFrame-statisztikákat, és megismerheti, hogyan viszonyulnak egymáshoz a különböző adathalmazoszlopok. Az adathalmazok megismerése előtt használja ezt a kódot a szükséges kódtárak importálásához:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Ezzel a kóddal megtekintheti a könyvadatokat tartalmazó DataFrame-et:
display(df_items, summary=True)
Adjon hozzá egy oszlopot _item_id későbbi használatra. Az _item_id értéknek egész számnak kell lennie a javaslatmodellekhez. Ez a kód az indexek átalakítására ITEM_ID_COL szolgálStringIndexer:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Jelenítse meg a DataFrame-et, és ellenőrizze, hogy az _item_id érték a várt módon monoton módon és egymást követően nő-e:
display(df_items.sort(F.col("_item_id").desc()))
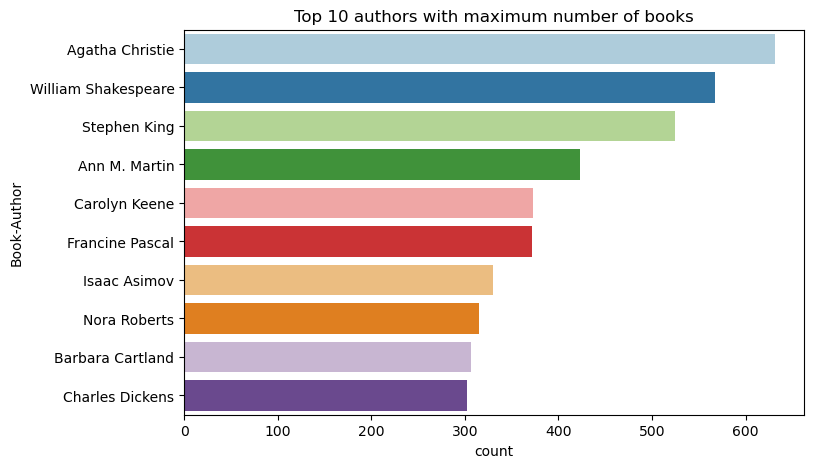
Ezzel a kóddal csökkenő sorrendben ábrázolhatja az első 10 szerzőt a megírt könyvek száma alapján. Agatha Christie a vezető szerző több mint 600 könyvet, majd William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Ezután jelenítse meg a felhasználói adatokat tartalmazó DataFrame-et:
display(df_users, summary=True)
Ha egy sornak hiányzik User-ID egy értéke, akkor azt a sort ejtse el. A testreszabott adatkészlet hiányzó értékei nem okoznak problémát.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Adjon hozzá egy oszlopot _user_id későbbi használatra. Javaslatmodellek esetében az _user_id értéknek egész számnak kell lennie. Az alábbi kódminta az indexek átalakítására USER_ID_COL szolgálStringIndexer.
A könyvadatkészletnek már van egész oszlopa User-ID . A különböző adathalmazokkal való kompatibilitást szolgáló oszlop hozzáadása _user_id azonban robusztusabbá teszi ezt a példát. Ezzel a kóddal adja hozzá az oszlopot _user_id :
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Ezzel a kóddal tekintheti meg a minősítési adatokat:
display(df_ratings, summary=True)
Szerezze be a különböző minősítéseket, és mentse őket későbbi használatra a következő nevű ratingslistában:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
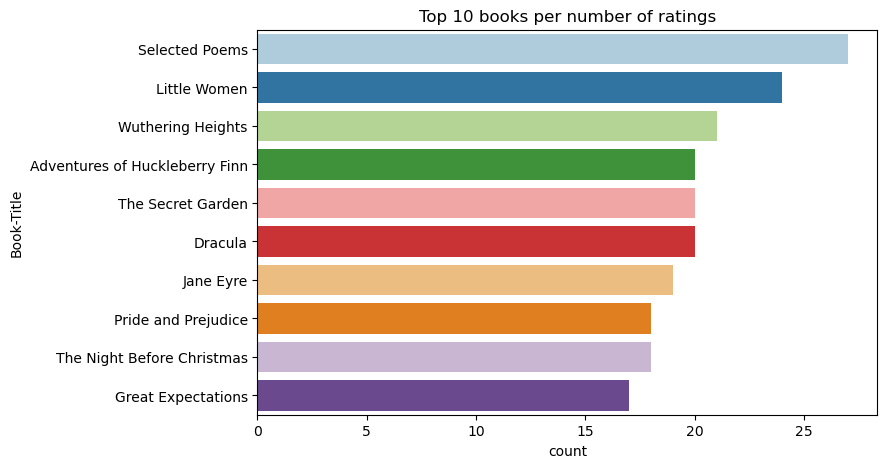
Ezzel a kóddal megjelenítheti a legjobb 10 könyvet a legmagasabb értékeléssel:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
A minősítések szerint a Kiválasztott versek a legnépszerűbb könyv. Kalandok Huckleberry Finn, The Secret Garden, és Drakula ugyanazzal a minősítéssel.
Adategyesítés
A három DataFrame-et egyetlen DataFrame-be egyesítheti egy átfogóbb elemzéshez:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Ezzel a kóddal megjelenítheti a különböző felhasználók, könyvek és interakciók számát:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
A legnépszerűbb elemek kiszámítása és ábrázolása
Ezzel a kóddal kiszámíthatja és megjelenítheti a 10 legnépszerűbb könyvet:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Tipp.
Használja a <topn> népszerű vagy a legnépszerűbb ajánlott szakaszok értékét.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Adathalmazok betanítása és tesztelése
Az ALS-mátrix a betanítás előtt némi adatelőkészítést igényel. Ezzel a kódmintával készítse elő az adatokat. A kód a következő műveleteket hajtja végre:
- A minősítési oszlop megfelelő típusba történő beírása
- A betanítási adatok mintája felhasználói értékelésekkel
- Adatok felosztása betanítási és tesztelési adatkészletekre
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
A ritkaság a ritkán küldött visszajelzési adatokra utal, amelyek nem tudják azonosítani a felhasználók érdeklődési körének hasonlóságát. Az adatok és az aktuális probléma jobb megértéséhez használja ezt a kódot az adathalmaz ritkaságának kiszámításához:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
3. lépés: A modell fejlesztése és betanítása
Betanítsa az ALS-modellt, hogy személyre szabott javaslatokat adjon a felhasználóknak.
A modell definiálása
A Spark ML egy kényelmes API-t biztosít az ALS-modell létrehozásához. A modell azonban nem kezeli megbízhatóan az olyan problémákat, mint az adatritkítás és a hidegindítás (a felhasználók vagy elemek újak esetén). A modell teljesítményének javítása érdekében kombinálja a keresztérvényesítést és az automatikus hiperparaméter-finomhangolást.
Ezzel a kóddal importálhatja a modell betanításához és kiértékeléséhez szükséges kódtárakat:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Modell hiperparamétereinek finomhangolása
A következő kódminta egy paraméterrácsot hoz létre, amely segít a hiperparaméterek keresésében. A kód létrehoz egy regressziós kiértékelőt is, amely a root-mean-square hibát (RM Standard kiadás) használja kiértékelési metrikaként:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
A következő kódminta különböző modellhangolási módszereket indít el az előre konfigurált paraméterek alapján. A modellhangolásról további információt az Ml Tuning: modellválasztás és hiperparaméter-finomhangolás című témakörben talál az Apache Spark webhelyén.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
A modell értékelése
A modulokat a tesztadatok alapján kell kiértékelnie. Egy jól betanított modellnek magas metrikákkal kell rendelkeznie az adathalmazon.
Egy túlméretezett modellnek növelnie kell a betanítási adatok méretét, vagy csökkentenie kell néhány redundáns funkciót. Előfordulhat, hogy a modellarchitektúra megváltozik, vagy a paraméterek finomhangolást igényelnek.
Feljegyzés
A negatív R-négyzetes metrikaérték azt jelzi, hogy a betanított modell rosszabbul teljesít, mint egy vízszintes egyenes. Ez a megállapítás arra utal, hogy a betanított modell nem magyarázza meg az adatokat.
Kiértékelési függvény definiálásához használja a következő kódot:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
A kísérlet nyomon követése az MLflow használatával
Az MLflow használatával nyomon követheti az összes kísérletet, és naplózhatja a paramétereket, metrikákat és modelleket. A modell betanításának és kiértékelésének megkezdéséhez használja a következő kódot:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Válassza ki a munkaterületről elnevezett aisample-recommendation kísérletet a betanítási futtatás naplózott adatainak megtekintéséhez. Ha módosította a kísérlet nevét, válassza ki az új nevet tartalmazó kísérletet. A naplózott adatok a következő képre hasonlítanak:

4. lépés: A végső modell betöltése pontozáshoz és előrejelzések készítéséhez
A modell betanítása után, majd a legjobb modell kiválasztása után töltse be a modellt a pontozáshoz (más néven következtetéshez). Ez a kód betölti a modellt, és előrejelzéseket használ az első 10 könyv ajánlásához minden felhasználó számára:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
A kimenet a következő táblázathoz hasonló:
| _item_id | _user_id | rating | Könyvcím |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Élete ... |
| 786 | 7 | 6.2255826 | A piano man's D... |
| 45330 | 7 | 4.980466 | Elmeállapot |
| 38960 | 7 | 4.980466 | Minden, amit valaha is akart |
| 125415 | 7 | 4.505084 | Harry Potter és ... |
| 44939 | 7 | 4.3579073 | Taltos: Élete ... |
| 175247 | 7 | 4.3579073 | A Bonesetter 's ... |
| 170183 | 7 | 4.228735 | Az egyszerű élet... |
| 88503 | 7 | 4.221206 | A Blu szigete... |
| 32894 | 7 | 3.9031885 | Téli napforduló |
Az előrejelzések mentése a lakehouse-ba
Ezzel a kóddal írja vissza a javaslatokat a lakehouse-ba:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)