A OneLake integrálása az Azure HDInsighttal
Az Azure HDInsight a big data-elemzések felügyelt felhőalapú szolgáltatása, amely segít a szervezeteknek nagy mennyiségű adat feldolgozásában. Ez az oktatóanyag bemutatja, hogyan csatlakozhat a OneLake-hez egy Jupyter-jegyzetfüzettel egy Azure HDInsight-fürtből.
Az Azure HDInsight használata
Csatlakozás a OneLake-hez egy HDInsight-fürtből származó Jupyter-jegyzetfüzettel:
HDInsight (HDI) Apache Spark-fürt létrehozása. Kövesse az alábbi utasításokat: Fürtök beállítása a HDInsightban.
A fürtinformációk megadásakor jegyezze meg a fürt bejelentkezési felhasználónevét és jelszavát, mivel később szüksége lesz rájuk a fürt eléréséhez.
Felhasználó által hozzárendelt felügyelt identitás (UAMI) létrehozása: Létrehozás az Azure HDInsighthoz – UAMI , és válassza ki identitásként a Storage képernyőn.
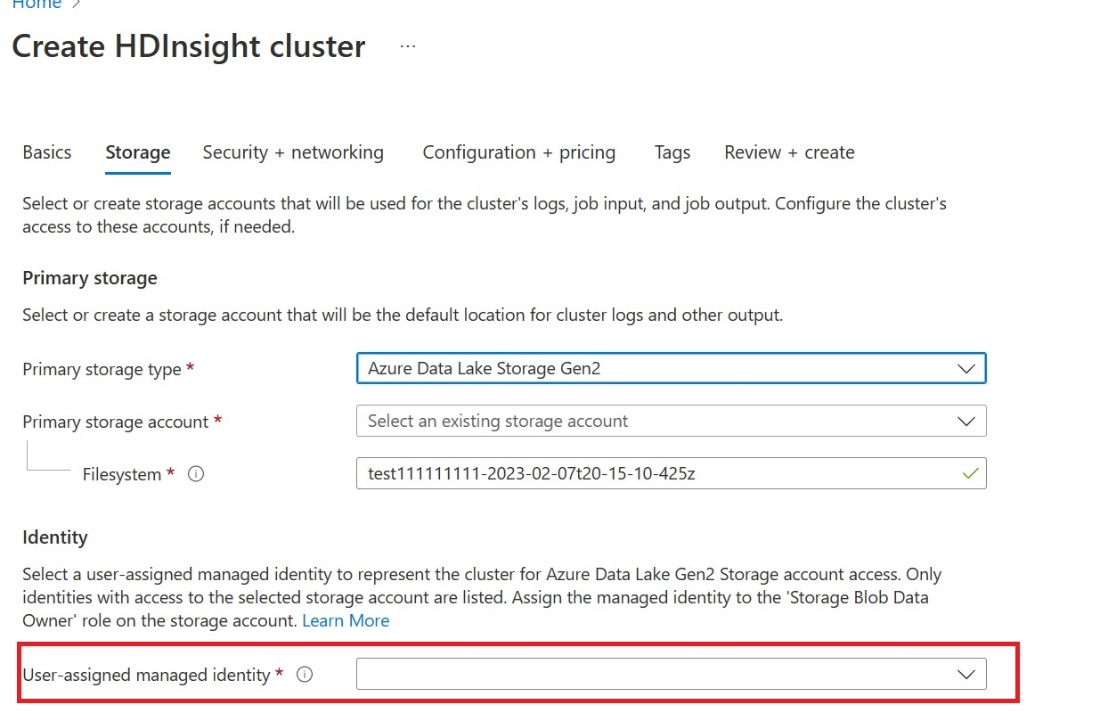
Adjon hozzáférést a UAMI-nak az elemeket tartalmazó Fabric-munkaterülethez. Ha segítségre van szüksége annak eldöntéséhez, hogy melyik szerepkör a legjobb, olvassa el a Munkaterületi szerepkörök című témakört.
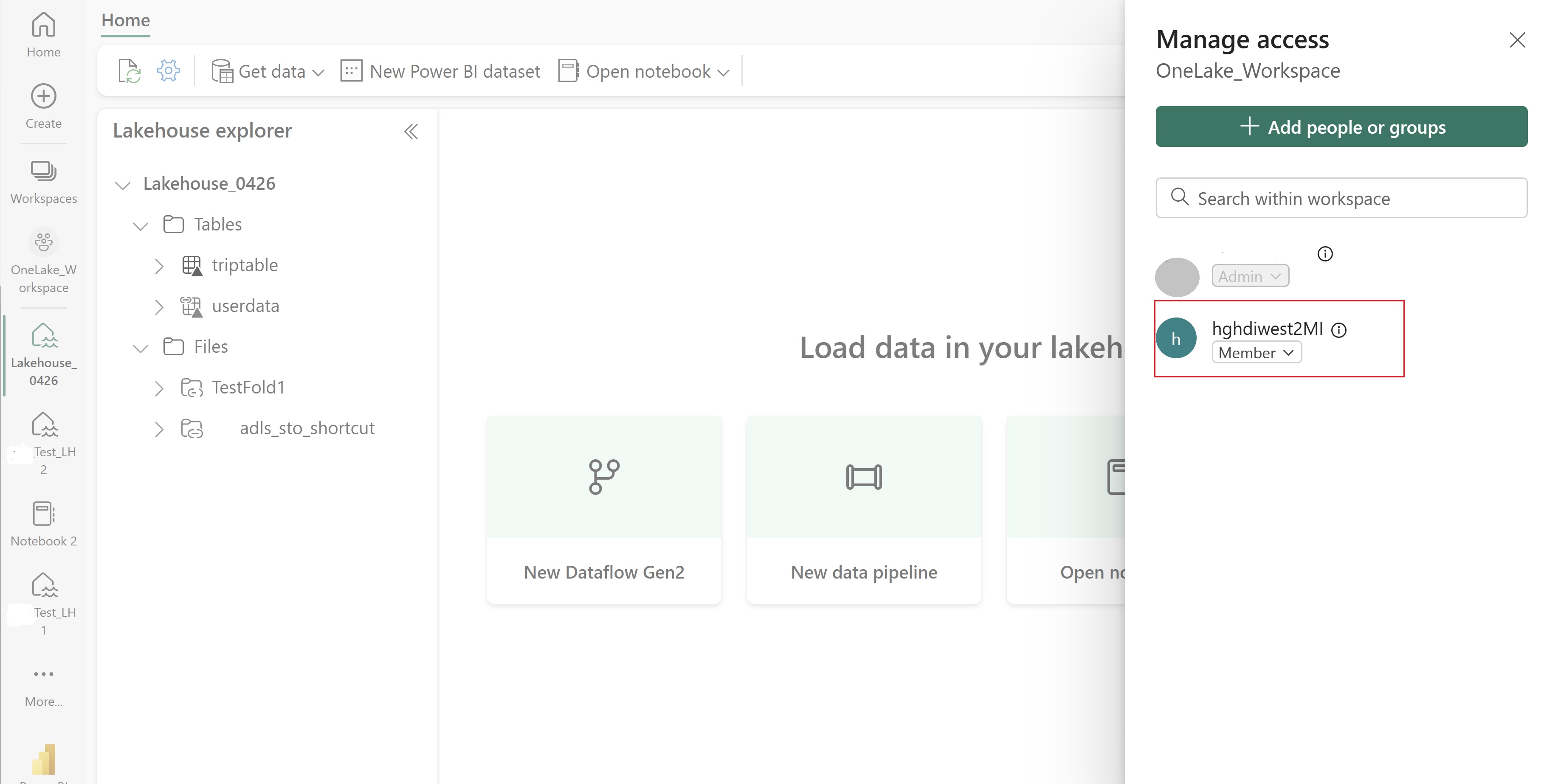
Lépjen a tóházra, és keresse meg a munkaterület és a tóház nevét. Ezeket megtalálhatja a tóház URL-címében vagy egy fájl Tulajdonságok paneljén.
Az Azure Portalon keresse meg a fürtöt, és válassza ki a jegyzetfüzetet.
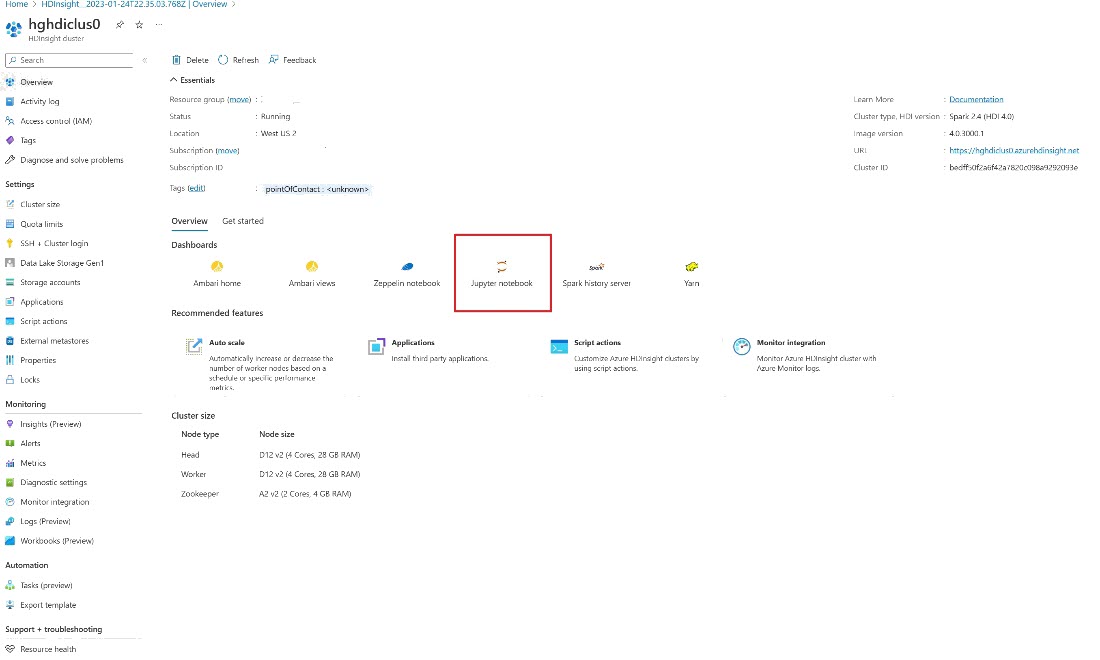
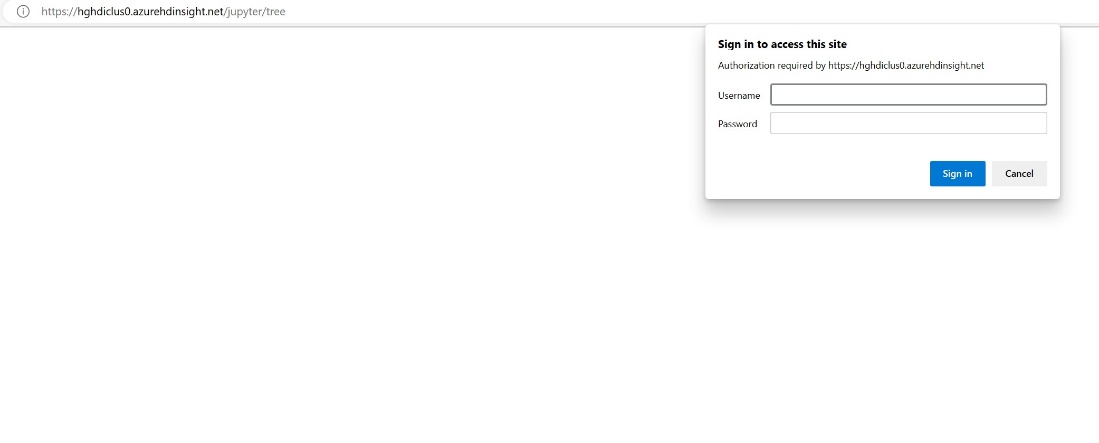
Adja meg a fürt létrehozásakor megadott hitelesítő adatokat.
Hozzon létre egy új Apache Spark-jegyzetfüzetet.
Másolja a munkaterület és a tóház nevét a jegyzetfüzetbe, és hozza létre a OneLake URL-címét a lakehouse-hoz. Most már bármilyen fájlt elolvashat ebből a fájlelérési útból.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Próbáljon meg adatokat írni a tóházba.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Ellenőrizze, hogy az adatok sikeresen meg vannak-e írva a lakehouse ellenőrzésével vagy az újonnan betöltött fájl olvasásával.




Mostantól a OneLake-ben is olvashat és írhat adatokat a Jupyter-jegyzetfüzetével egy HDI Spark-fürtben.