Nagy sűrűségű mintavételezés Power BI-pontdiagramokon
A Power BI mintavételezési algoritmusa javítja, hogy a pontdiagramok hogyan jelölik a nagy sűrűségű adatokat.
Létrehozhat például egy pontdiagramot a szervezet értékesítési tevékenységéből, és minden áruházban évente több tízezer adatpont található. Az ilyen információk pontdiagramja az adatok jelentéssel bíró ábrázolása alapján szemlélteti az értékesítések időbeli előfordulását. A nagy sűrűségű adatmintavétel részleteit ebben a cikkben ismertetjük.

Feljegyzés
A cikkben ismertetett nagy sűrűségű mintavételezési algoritmus a Power BI Desktop és a Power BI szolgáltatás pontdiagramjaiban is elérhető.
A nagy sűrűségű pontdiagramok működése
Korábban a Power BI determinisztikus módon kiválasztotta a mintaadatpontok gyűjteményét a mögöttes adatok teljes körében, hogy pontdiagramot hozzon létre. A Power BI konkrétan a pontdiagram-sorozat első és utolsó adatsorát választja ki, majd egyenlően osztja el a többi sort úgy, hogy a pontdiagramon összesen 3500 adatpont legyen ábrázolva. Ha például a minta 35 000 sort tartalmaz, az első és az utolsó sor lesz kijelölve a ábrázoláshoz, akkor minden tizedik sor is ábrázolva lesz (35 000 / 10 = minden tizedik sor = 3500 adatpont). Korábban az adatsorokban nem ábrázolható null értékek vagy pontok, például szöveges értékek nem voltak láthatók, így a vizualizáció létrehozásakor nem voltak figyelembe véve. Ilyen mintavételezéssel a pontdiagram érzékelt sűrűsége a reprezentatív adatpontokon is alapult, így a feltételezett vizualizáció sűrűsége a mintavételezett pontok egyik körülménye volt, nem pedig az alapul szolgáló adatok teljes gyűjteménye.
Ha engedélyezi a nagy sűrűségű mintavételezést, a Power BI olyan algoritmust implementál, amely kiküszöböli az átfedésben lévő pontokat, és biztosítja, hogy a vizualizáció pontjai elérhetők legyenek a vizualizáció használatakor. Az algoritmus azt is biztosítja, hogy az adathalmaz összes pontja megjelenjen a vizualizációban, és ahelyett, hogy csupán reprezentatív mintát ábrázol, kontextust biztosít a kijelölt pontok jelentéséhez.
Definíció szerint a nagy sűrűségű adatok mintavételezése olyan vizualizációk létrehozásához történik, amelyek reagálnak az interaktivitásra. A vizualizáció túl sok adatpontja lelassíthatja és csökkentheti a trendek láthatóságát. Az adatok mintavételezésének módja határozza meg a mintavételezési algoritmus létrehozását, hogy a lehető legjobb vizualizációs élményt nyújtsa, és biztosítsa az összes adat megjelenítését. A Power BI-ban az algoritmus továbbfejlesztése biztosítja a válaszképesség, a reprezentáció és a fontos pontok egyértelmű megőrzésének legjobb kombinációját a teljes adatkészletben.
Feljegyzés
A nagy sűrűségű mintavételezési algoritmust használó pontdiagramok a legjobban négyzetes vizualizációkon ábrázolhatók, mint az összes pontdiagram esetén.
A pontdiagram mintavételezési algoritmusának működése
A pontdiagramok nagy sűrűségű mintavételezési algoritmusa olyan módszereket alkalmaz, amelyek hatékonyabban rögzítik és ábrázolják az alapul szolgáló adatokat, és kiküszöbölik az átfedésben lévő pontokat. Az algoritmus minden adatponthoz egy kis sugárral kezdődik, amely a vizualizáció adott pontjának vizualizációs körmérete. Ezután növeli az összes adatpont sugarát. Ha két vagy több adatpont átfedésben van, a megnövekedett sugárméret egyetlen köre jelöli az átfedésben lévő adatpontokat. Az algoritmus addig növeli az adatpontok sugarát, amíg a sugárérték nem eredményez ésszerű számú adatpontot (3500) a pontdiagramon.
Az algoritmus metódusai biztosítják, hogy a kiugró értékek megjelenjenek az eredményként kapott vizualizációban. Az algoritmus az átfedés meghatározásakor is tiszteletben tartja a skálázást, így az exponenciális skálák a mögöttes vizualizációs pontokhoz való hűséggel jelennek meg.
Az algoritmus megőrzi a pontdiagram általános alakját is.
Feljegyzés
A pontdiagramok nagy sűrűségű mintavételezési algoritmusának használatakor az adatok pontos eloszlása a cél, nem pedig a vizualizáció sűrűsége. Előfordulhat például, hogy egy pontdiagram sok olyan körrel rendelkezik, amelyek átfedésben vannak egy adott területen (sűrűség), és azt képzeli, hogy sok adatpontot kell ott csoportosítani. Mivel a nagy sűrűségű mintavételezési algoritmus egy kör használatával számos adatpontot jelölhet, az ilyen vélelmezett vizualizációs sűrűség vagy a "fürtözés" nem jelenik meg. Ha részletesebben szeretne képet kapni egy adott területről, szeletelőkkel nagyíthatja a képet.
Emellett a nem ábrázolható adatpontok( például null értékek vagy szöveges értékek) figyelmen kívül lesznek hagyva, így egy másik ábrázolható érték van kijelölve. Ez tovább biztosítja a pontdiagram valódi alakjának megőrzését.
A pontdiagramok szabványos algoritmusának használata
Vannak olyan körülmények, amikor a nagy sűrűségű mintavételezés nem alkalmazható pontdiagramra, és az eredeti algoritmust használják. Ezek a körülmények a következők:
Ha a jobb gombbal az Értékek csoportban egy értékre kattint, és a menüből adatokat nem tartalmazó elemek megjelenítésére állítja, a pontdiagram visszaáll az eredeti algoritmusra.
A Lejátszási tengely mező minden értéke azt eredményezi, hogy a pontdiagram visszaáll az eredeti algoritmusra.
Ha az X és az Y tengely is hiányzik egy pontdiagramon, a diagram visszaáll az eredeti algoritmusra.
Ha az Elemzés panelen egy Arány sort használ, a diagram visszaáll az eredeti algoritmusra.
Nagy sűrűségű mintavételezés bekapcsolása pontdiagramhoz
A nagy sűrűségű mintavételezés bekapcsolásához jelöljön ki egy pontdiagramot, nyissa meg a Vizualizáció formázása panelt, bontsa ki az Általános kártyát, és a kártya alján húzza a Nagy sűrűségű mintavételezési csúszkát Be állásba.
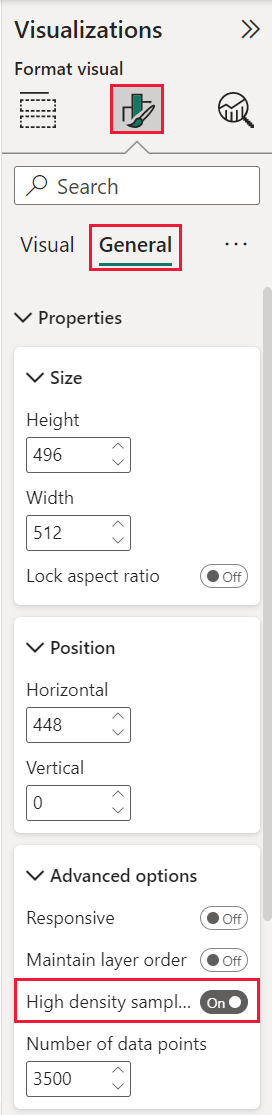
Feljegyzés
A kapcsoló bekapcsolása után a Power BI lehetőség szerint megpróbálja használni a nagy sűrűségű mintavételezési algoritmust. Ha az algoritmus nem használható, például amikor értéket helyez el a Lejátszási tengelyen, a kapcsoló bekapcsolva marad, annak ellenére, hogy a diagram visszaállt a standard algoritmusra. Ha ezután eltávolít egy értéket a Lejátszási tengelyről, vagy ha a feltételek megváltoznak a nagy sűrűségű mintavételezési algoritmus használatához, a diagram automatikusan nagy sűrűségű mintavételezést használ a diagramhoz, mert a funkció aktív.
Feljegyzés
Az adatpontokat az index csoportosítja vagy kijelöli. A jelmagyarázat nem befolyásolja az algoritmus mintavételezését. Ez csak a vizualizáció sorrendjét befolyásolja.
Szempontok és korlátozások
A nagy sűrűségű mintavételezési algoritmus fontos fejlesztés a Power BI-ban. A nagy sűrűségű mintavételezési algoritmus azonban csak élő kapcsolatokkal működik Power BI szolgáltatás-alapú modellekhez, importált modellekhez vagy DirectQuery-hez.