Útmutató a DirectQuery-modellhez a Power BI Desktopban
Ez a cikk a Power BI DirectQuery-modelleket fejlesztő adatmodellezőket célozza meg, amelyeket a Power BI Desktop vagy a Power BI szolgáltatás használatával fejlesztettek ki. A DirectQuery használati eseteit, korlátozásait és útmutatását ismerteti. Az útmutató célja, hogy meghatározza, hogy a DirectQuery a modellnek megfelelő mód-e, és hogy a Jelentések teljesítménye a DirectQuery-modelleken alapuljon. Ez a cikk a Power BI szolgáltatás vagy Power BI jelentéskészítő kiszolgáló üzemeltetett DirectQuery-modellekre vonatkozik.
Ez a cikk nem a DirectQuery-modell tervezésének teljes ismertetését ismerteti. Bevezetésként tekintse meg a Power BI Desktop DirectQuery-modelljeit. Részletesebb ismertetésért tekintse meg közvetlenül az SQL Server 2016 Analysis Services tanulmányában található DirectQueryt. Ne feledje, hogy a tanulmány leírja a DirectQuery használatát az SQL Server Analysis Servicesben. A tartalom nagy része azonban továbbra is alkalmazható a Power BI DirectQuery-modellekre.
Feljegyzés
A Dataverse DirectQuery tárolási módjának használatakor a Power BI modellezési útmutatójában talál további szempontokat.
Ez a cikk nem fedi le közvetlenül az összetett modelleket. Az összetett modellek legalább egy DirectQuery-forrásból és esetleg többből állnak. Az ebben a cikkben ismertetett útmutató továbbra is releváns – legalábbis részben – az összetett modell kialakításához. Az importálási táblák DirectQuery-táblákkal való kombinálásának következményei azonban nem tartoznak a cikk hatókörébe. További információ: Összetett modellek használata a Power BI Desktopban.
Fontos tisztában lenni azzal, hogy a DirectQuery-modellek eltérő számítási feladatot rónak a Power BI-környezetre (Power BI szolgáltatás vagy Power BI jelentéskészítő kiszolgáló), valamint a mögöttes adatforrásokra is. Ha úgy ítéli meg, hogy a DirectQuery a megfelelő tervezési megközelítés, javasoljuk, hogy a megfelelő személyeket vonja be a projektbe. Gyakran látjuk, hogy a DirectQuery-modell sikeres üzembe helyezése egy informatikai szakemberekből álló csapat eredménye, amely szorosan együttműködik. A csapat általában modellfejlesztőkből és forrásadatbázis-rendszergazdákból áll. Emellett adattervezőket, adattárház- és ETL-fejlesztőket is bevonhat. Az optimalizálásokat gyakran közvetlenül az adatforrásra kell alkalmazni a jó teljesítmény elérése érdekében.
Az adatforrás teljesítményének optimalizálása
A relációs adatbázis forrása többféleképpen is optimalizálható az alábbi felsorolásban leírtak szerint.
Feljegyzés
Megértjük, hogy nem minden modellező rendelkezik a relációs adatbázis optimalizálásához szükséges engedélyekkel vagy készségekkel. Bár a DirectQuery-modell adatainak előkészítése az előnyben részesített réteg, bizonyos optimalizálásokat a modelltervben is el lehet érni a forrásadatbázis módosítása nélkül. A legjobb optimalizálási eredmények azonban gyakran úgy érhetők el, hogy optimalizálást alkalmaz a forrásadatbázisra.
Győződjön meg arról, hogy az adatintegritás teljes: Különösen fontos, hogy a dimenzió típusú táblák egyedi értékeket tartalmazó oszlopot (dimenziókulcsot) tartalmazzanak, amely megfelel a tény típusú táblázat(ok)nak. Az is fontos, hogy a tény típusú dimenzióoszlopok érvényes dimenziókulcs-értékeket tartalmazzanak. Lehetővé teszik a hatékonyabb modellkapcsolatok konfigurálását, amelyek a kapcsolatok mindkét oldalán egyező értékeket várnak. Ha a forrásadatok nem fedik az integritást, javasoljuk, hogy az adatok hatékony javításához egy "ismeretlen" dimenziórekordot kell hozzáadni. Hozzáadhat például egy sort a Product táblához egy ismeretlen termék megjelenítéséhez, majd hozzárendelhet egy tartományon kívüli kulcsot, például -1. Ha a Sales tábla soraiban hiányzik a termékkulcs értéke, cserélje le őket -1 értékre. Biztosítja, hogy minden Értékesítési termékkulcs-értéknek legyen egy megfelelő sora a Termék táblában.
Indexek hozzáadása: Megfelelő indexek definiálása táblákon vagy nézeteken a várt jelentésvizualizáció szűréséhez és csoportosításához szükséges adatok hatékony lekérésének támogatásához. AZ SQL Server, az Azure SQL Database vagy az Azure Synapse Analytics (korábbi nevén SQL Data Warehouse) forrásaihoz tekintse meg az SQL Server indexarchitektúráját és tervezési útmutatóját az indextervezési útmutatóban. Sql Server- vagy Azure SQL Database-beli illékony források esetén tekintse meg a Columnstore használatának első lépéseit a valós idejű üzemeltetési elemzésekhez.
Elosztott táblák tervezése: A nagymértékben párhuzamos feldolgozási (MPP) architektúrát használó Azure Synapse Analytics-(korábbi nevén SQL Data Warehouse-) források esetében érdemes lehet nagy tény típusú táblákat kivonatos elosztottként konfigurálni, és dimenzió típusú táblákat az összes számítási csomópontra replikálni. További információ: Útmutató elosztott táblák tervezéséhez az Azure Synapse Analyticsben (korábban SQL Data Warehouse).
Győződjön meg arról, hogy a szükséges adatátalakítások megvalósultak: AZ SQL Server relációs adatbázis-forrásaihoz (és más relációs adatbázis-forrásokhoz) számított oszlopok is hozzáadhatók a táblákhoz. Ezek az oszlopok egy kifejezésen alapulnak, például a Mennyiség és az Egységár szorzatán. A számított oszlopok megőrizhetők (materializáltak), és a normál oszlopokhoz hasonlóan néha indexelhetők. További információ: Számított oszlopok indexei.
Fontolja meg az indexelt nézeteket is, amelyek előre összesíthetik a ténytáblák adatait magasabb szemcseméret mellett. Ha például a Sales tábla rendeléssor szintjén tárolja az adatokat, létrehozhat egy nézetet az adatok összegzéséhez. A nézet egy Standard kiadás LECT utasításon alapulhat, amely dátum (hónap szintjén), ügyfél, termék szerint csoportosítja az Értékesítési tábla adatait, és összegzi az olyan mértékértékeket, mint az értékesítés, a mennyiség stb. A nézet ezután indexelhető. SQL Server- vagy Azure SQL Database-források esetén lásd : Indexelt nézetek létrehozása.
Dátumtábla materializálása: Egy gyakori modellezési követelmény magában foglalja egy dátumtábla hozzáadását az időalapú szűrés támogatásához. A szervezet ismert időalapú szűrőinek támogatásához hozzon létre egy táblát a forrásadatbázisban, és győződjön meg arról, hogy a ténytábla dátumait tartalmazó dátumtartomány van betöltve. Azt is győződjön meg róla, hogy a hasznos időszakok oszlopait tartalmazza, például évet, negyedévet, hónapot, hetet stb.
Modellterv optimalizálása
A DirectQuery-modellek számos módon optimalizálhatók az alábbi felsorolásban leírtak szerint.
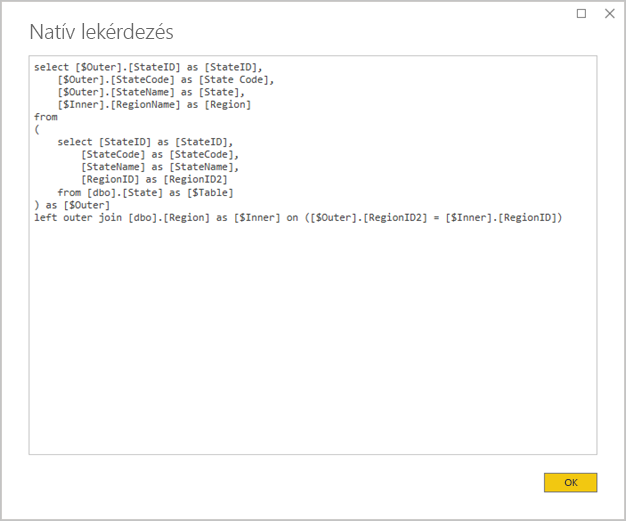
Kerülje az összetett Power Query-lekérdezéseket: Hatékony modellterv érhető el, ha nem szükséges, hogy a Power Query-lekérdezések bármilyen átalakítást alkalmazzanak. Ez azt jelenti, hogy minden lekérdezés egyetlen relációs adatbázis forrástáblája vagy nézete lesz leképzve. Az alkalmazott Power Query-lépések tényleges SQL-lekérdezési utasításának előnézetét a Natív lekérdezés megtekintése lehetőség kiválasztásával tekintheti meg.
A számított oszlopok és adattípus-módosítások használatának vizsgálata: A DirectQuery-modellek támogatják a számítások hozzáadását és a Power Query lépéseit az adattípusok konvertálásához. A jobb teljesítményt azonban gyakran a relációs adatbázis forrásában történő átalakítás eredményeinek materializálásával érheti el, ha lehetséges.
Ne használja a Power Query relatív dátumszűrését: A relatív dátumszűrés definiálható a Power Query-lekérdezésekben. Például az elmúlt évben létrehozott értékesítési rendelésekhez való lekéréshez (a mai dátumhoz képest). Ez a szűrőtípus nem hatékony natív lekérdezésre fordítható le az alábbiak szerint:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))A jobb kialakítási módszer a relatív időoszlopok belefoglalása a dátumtáblába. Ezek az oszlopok az aktuális dátumhoz viszonyított eltolási értékeket tárolják. Egy RelativeYear oszlopban például a nulla az aktuális évet, a -1 az előző évet, stb. Lehetőség szerint a RelativeYear oszlop a dátumtáblában lesz materializálva. Bár kevésbé hatékony, modellalapú oszlopként is hozzáadható a TODAY és a DATE DAX függvényt használó kifejezés alapján.
A mértékek egyszerűek: Legalább kezdetben ajánlott a mértékeket egyszerű összesítésekre korlátozni. Az összesítő függvények közé tartozik a SZUM, a DARAB, a MIN, a MAX és az ÁTLAG. Ezután, ha a mértékek megfelelően reagálnak, összetettebb mértékekkel kísérletezhet, de figyelhet az egyes mértékek teljesítményére. Bár a CALCULATE DAX függvény olyan kifinomult mértékkifejezések előállítására használható, amelyek módosítják a szűrőkörnyezetet, költséges natív lekérdezéseket hozhatnak létre, amelyek nem működnek megfelelően.
Kerülje a számított oszlopok kapcsolatait: A modellkapcsolatok csak egy tábla egyetlen oszlopát kapcsolhatják össze egy másik tábla egyetlen oszlopához. Néha azonban több oszlop használatával is össze kell kapcsolni a táblákat. Az Értékesítés és a Földrajzi tábla például két oszlopból áll: CountryRegion és City. A táblák közötti kapcsolat létrehozásához egyetlen oszlopra van szükség, és a Geography táblában az oszlopnak egyedi értékeket kell tartalmaznia. Ezt az eredményt akkor érheti el, ha az országot/régiót és várost kötőjelelválasztóval összefűzi.
Az egyesített oszlop létrehozható egy egyéni Power Query-oszlopmal, vagy a modellben számított oszlopként. Ezt azonban kerülni kell, mivel a számítási kifejezés a forrás lekérdezésekbe lesz beágyazva. Nem csak nem hatékony, hanem gyakran megakadályozza az indexek használatát. Ehelyett adjon hozzá materializált oszlopokat a relációs adatbázis forrásához, és fontolja meg az indexelésüket. A dimenzió típusú táblákhoz kiegészítő kulcsoszlopokat is hozzáadhat, ami a relációs adattárház-kialakítások gyakori gyakorlata.
Ez az útmutató kivételt képez, és a COMBINEVALUES DAX függvény használatára vonatkozik. Ennek a függvénynek a célja a többoszlopos modellkapcsolatok támogatása. A kapcsolat által használt kifejezés létrehozása helyett egy többoszlopos SQL-illesztés predikátumot hoz létre.
Kerülje az "Egyedi azonosító" oszlopok kapcsolatait: A Power BI natív módon nem támogatja az egyedi azonosító (GUID) adattípust. Az ilyen típusú oszlopok közötti kapcsolat definiálásakor a Power BI létrehoz egy forrás lekérdezést egy illesztéssel, amely egy öntöttet tartalmaz. Ez a lekérdezési idő szerinti adatkonvertálás általában gyenge teljesítményt eredményez. Az eset optimalizálásáig az egyetlen megkerülő megoldás egy alternatív adattípus oszlopainak létrehozása az alapul szolgáló adatbázisban.
A kapcsolatok egyoldalas oszlopának elrejtése: A kapcsolat egyoldalas oszlopának rejtve kell lennie. (Ez általában a dimenzió típusú táblák elsődleges kulcsoszlopa.) Rejtett állapotban nem érhető el a Mezők panelen, ezért nem használható vizualizáció konfigurálására. A többoldalas oszlop látható marad, ha hasznos a jelentések csoportosítása vagy szűrése az oszlopértékek alapján. Vegyük például azt a modellt, amelyben kapcsolat áll fenn a Sales és a Product táblák között. A kapcsolatoszlopok termékváltozatot (készletmegőrzési egység) tartalmaznak. Ha termékváltozatot kell hozzáadni a vizualizációkhoz, az csak a Sales táblában látható. Ha ez az oszlop egy vizualizáció szűrésére vagy csoportosítására szolgál, a Power BI létrehoz egy olyan lekérdezést, amely nem szükséges az Értékesítési és terméktáblákhoz való csatlakozáshoz.
Kapcsolatok beállítása az integritás kikényszerítéséhez: A DirectQuery-kapcsolatok Hivatkozási integritás feltételezése tulajdonsága meghatározza, hogy a Power BI külső illesztés helyett belső illesztés használatával hoz-e létre forrás lekérdezéseket. Ez általában javítja a lekérdezési teljesítményt, bár ez a relációs adatbázis forrásának jellemzőitől függ. További információ: Hivatkozási integritási beállítások feltételezése a Power BI Desktopban.
Kerülje a kétirányú kapcsolatszűrés használatát: A kétirányú kapcsolat szűrése olyan lekérdezési utasításokhoz vezethet, amelyek nem teljesítenek megfelelően. Ezt a kapcsolati funkciót csak akkor használja, ha szükséges, és ez általában a több-a-többhöz kapcsolat áthidaló táblán keresztüli implementálásakor fordul elő. További információ: Kapcsolatok több-több számossággal a Power BI Desktopban.
Párhuzamos lekérdezések korlátozása: Beállíthatja, hogy a DirectQuery legfeljebb hány kapcsolatot nyit meg az egyes mögöttes adatforrásokhoz. Ez szabályozza az adatforrásnak egyidejűleg küldött lekérdezések számát.
- A beállítás csak akkor engedélyezett, ha a modellben legalább egy DirectQuery-forrás található. Az érték az összes DirectQuery-forrásra és a modellhez hozzáadott új DirectQuery-forrásokra vonatkozik.
- Az adatforrásonkénti Csatlakozás ions maximális értékének növelése biztosítja, hogy több lekérdezés (a megadott maximális számig) elküldhető legyen az alapul szolgáló adatforrásnak, ami akkor hasznos, ha számos vizualizáció található egy oldalon, vagy ha sok felhasználó egyszerre fér hozzá egy jelentéshez. A kapcsolatok maximális számának elérése után a rendszer további lekérdezéseket is várólistára állít, amíg el nem érhető a kapcsolat. A korlát növelése nagyobb terhelést eredményez a mögöttes adatforráson, így a beállítás nem garantált a teljes teljesítmény javítása érdekében.
- A modell Power BI-ban való közzétételekor a mögöttes adatforrásnak küldött egyidejű lekérdezések maximális száma a környezettől is függ. A különböző környezetek (például a Power BI, a Power BI Premium vagy a Power BI jelentéskészítő kiszolgáló) eltérő átviteli sebességre vonatkozó korlátozásokat alkalmazhatnak. A Power BI Premium kapacitáserőforrás-korlátairól további információt a Power BI Premium-kapacitások üzembe helyezéséről és kezeléséről szóló cikkben talál.
Jelentéstervek optimalizálása
A DirectQuery szemantikai modellen (korábbi nevén adatkészleten) alapuló jelentések sokféleképpen optimalizálhatók, ahogyan az alábbi listajeles lista is ismerteti.
- Lekérdezéscsökkentési technikák engedélyezése: A Power BI Desktop beállításai és Gépház tartalmaz egy lekérdezéscsökkentési lapot. Ez a lap három hasznos lehetőséget kínál. Alapértelmezés szerint letiltható a keresztkiemelés és a keresztszűrés, de az interakciók szerkesztésével felülírható. A szeletelők és szűrők Alkalmazás gombja is megjeleníthető. A szeletelő vagy a szűrő beállításai nem lesznek alkalmazva, amíg a jelentésfelhasználó nem kattint a gombra. Ha engedélyezi ezeket a beállításokat, javasoljuk, hogy ezt a jelentés első létrehozásakor tegye meg.
- Először alkalmazza a szűrőket: A jelentések tervezésekor javasoljuk, hogy a mezők vizualizációs mezőkre való leképezése előtt – jelentés, oldal vagy vizualizáció szintjén – alkalmazza a megfelelő szűrőket. Például ahelyett, hogy az Országrégió és az Értékesítés mértéken húz, majd egy adott év szerint szűr, először az Év mezőre alkalmazza a szűrőt. Ennek az az oka, hogy a vizualizációk létrehozásának minden lépése egy lekérdezést küld, és bár az első lekérdezés befejeződése előtt lehetséges újabb módosításokat végezni, továbbra is szükségtelen terhelést helyez el a mögöttes adatforráson. A szűrők korai alkalmazásával ezek a köztes lekérdezések általában kevésbé költségesek és gyorsabbak. A szűrők korai alkalmazásának elmulasztása azt is eredményezheti, hogy túllépi az 1 millió sorra vonatkozó korlátot a DirectQueryről szóló cikkben leírtak szerint.
- Egy lapon lévő vizualizációk számának korlátozása: Ha egy jelentésoldal meg van nyitva (és amikor oldalszűrőket alkalmaz), a rendszer frissíti a lapon lévő összes vizualizációt. A Power BI-környezet által előírt, párhuzamosan küldhető lekérdezések száma azonban korlátozott, és az adatforrásmodell-beállításonkénti maximális Csatlakozás ionok a fent leírtak szerint vannak meghatározva. Így az oldalvizualizációk számának növekedésével nagyobb az esély arra, hogy a vizualizációk sorozatos módon frissülnek. Növeli a teljes oldal frissítéséhez szükséges időt, és növeli annak az esélyét is, hogy a vizualizációk inkonzisztens eredményeket jeleníthetnek meg (változékony adatforrások esetén). Ezért javasoljuk, hogy korlátozza a vizualizációk számát bármelyik oldalon, és ehelyett egyszerűbb lapokkal rendelkezzen. Ha több kártyavizualizációt cserél le egyetlen többsoros kártyavizualizációra, hasonló lapelrendezést érhet el.
- A vizualizációk közötti interakció kikapcsolása: A keresztkiemelési és keresztszűrési interakciókhoz lekérdezéseket kell küldeni a mögöttes forrásnak. Hacsak nincs szükség ezekre az interakciókra, ajánlott kikapcsolni őket, ha a felhasználók kiválasztására való válaszadáshoz szükséges idő indokolatlanul hosszú lenne. Ezek az interakciók kikapcsolhatók a teljes jelentésre vonatkozóan (a lekérdezéscsökkentési beállítások esetében fent leírtak szerint), vagy eseti alapon. További információ: Hogyan szűrik egymást a vizualizációk egy Power BI-jelentésben.
Az optimalizálási technikák fenti listája mellett az alábbi jelentéskészítési képességek is hozzájárulhatnak a teljesítményproblémákhoz:
Mértékszűrők: A mértékeket (vagy oszlopösszesítéseket) tartalmazó vizualizációk szűrőket alkalmazhatnak ezekre a mértékekre. Az alábbi vizualizáció például a Sales by Category (Értékesítés kategória szerint) értéket jeleníti meg, de csak a 15 millió usd-nél több értékesítést tartalmazó kategóriák esetében.
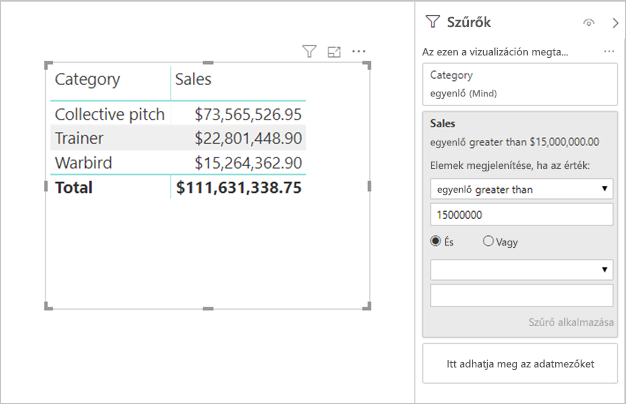
A rendszer két lekérdezést küldhet a mögöttes forrásnak:
- Az első lekérdezés lekéri a feltételnek eleget tetső kategóriákat ( > 15 millió usd értékesítés)
- A második lekérdezés ezután lekéri a vizualizációhoz szükséges adatokat, és hozzáadja a feltételnek megfelelő kategóriákat a WHERE záradékhoz
Általában jól teljesít, ha több száz vagy több ezer kategória van, mint ebben a példában. A teljesítmény azonban csökkenhet, ha a kategóriák száma sokkal nagyobb (és valóban, a lekérdezés meghiúsul, ha több mint 1 millió kategória felel meg a feltételnek a fent említett 1 millió sorkorlát miatt).
TopN-szűrők: Speciális szűrők definiálhatók úgy, hogy csak a mérték által rangsorolt felső (vagy alsó) N értékekre szűrjenek. Például a fenti vizualizációban csak az első öt kategória megjelenítése. A mértékszűrőkhöz hasonlóan a rendszer két lekérdezést is küld a mögöttes adatforrásnak. Az első lekérdezés azonban az alapul szolgáló forrás összes kategóriáját visszaadja, majd a rendszer a visszaadott eredmények alapján határozza meg a felső N-t. Az érintett oszlop számosságától függően teljesítményproblémákhoz (vagy az 1 millió sorból álló korlát miatti lekérdezési hibákhoz) vezethet.
Medián: Általában minden összesítés (Sum, Count Distinct stb.) le lesz küldve a mögöttes forrásba. Ez azonban a Medián esetében nem igaz, mivel ezt az aggregátumot a mögöttes forrás nem támogatja. Ilyen esetekben a rendszer részletes adatokat kér le a mögöttes forrásból, és a Power BI kiértékeli a visszaadott eredmények mediánjait. Nem baj, ha a mediánt viszonylag kis számú eredmény alapján kell kiszámítani, de a számosság nagysága esetén teljesítményproblémák (vagy az 1 millió sorból álló korlát miatti lekérdezési hibák) fordulnak elő. Előfordulhat például, hogy a medián ország/régió lakossága ésszerű, de előfordulhat, hogy a medián értékesítési ár nem.
Többválasztós szeletelők: A szeletelőkben és szűrőkben történő többszörös kijelölés engedélyezése teljesítményproblémákat okozhat. Ennek az az oka, hogy amikor a felhasználó további szeletelőelemeket választ ki (például az őket érdeklő 10 termékből álló összeállítást), minden új kijelölés egy új lekérdezést küld a mögöttes forrásnak. Bár a felhasználó a lekérdezés befejezése előtt kiválaszthatja a következő elemet, az extra terhelést eredményez a mögöttes forrásra. Ez a helyzet elkerülhető az Alkalmaz gomb megjelenítésével, a lekérdezéscsökkentési technikákban leírtak szerint.
Vizualizációösszegek: Alapértelmezés szerint a táblák és mátrixok összegeket és részösszegeket jelenítenek meg. Sok esetben további lekérdezéseket kell küldeni a mögöttes forrásnak az összegek értékének lekéréséhez. Minden esetben a Count Distinct vagy a Medián aggregátumok használata esetén, valamint minden esetben a DirectQuery SAP HANA-n vagy AZ SAP Business Warehouse-n keresztül történő használatakor érvényes. Ha nem szükséges, az ilyen összegeket ki kell kapcsolni (a Formátum panel használatával).
Konvertálás összetett modellre
Az Importálási és DirectQuery-modellek előnyei egyetlen modellbe kombinálhatók a modelltáblák tárolási módjának konfigurálásával. A tábla tárolási módja lehet Importálás vagy DirectQuery, vagy mindkettő, más néven Kettős. Ha egy modell különböző tárolási módokkal rendelkező táblákat tartalmaz, összetett modellnek nevezzük. További információ: Összetett modellek használata a Power BI Desktopban.
Számos funkcionális és teljesítménybeli fejlesztés érhető el a DirectQuery-modellek összetett modellté alakításával. Az összetett modellek több DirectQuery-forrást is integrálhatnak, és aggregációkat is tartalmazhatnak. Az aggregációs táblák a DirectQuery-táblákhoz hozzáadhatók a tábla összesített ábrázolásának importálásához. A vizualizációk magasabb szintű aggregátumok lekérdezése esetén drámai teljesítménybeli fejlesztéseket érhetnek el. További információ: Aggregációk a Power BI Desktopban.
Felhasználók oktatása
Fontos, hogy a felhasználókat megtanítsa a DirectQuery szemantikai modelleken alapuló jelentések hatékony kezelésére. A jelentéskészítőknek a jelentéstervek optimalizálása szakaszban leírt tartalomra kell tanítaniuk.
Javasoljuk, hogy tájékoztassa a jelentés felhasználóit a DirectQuery szemantikai modelleken alapuló jelentéseiről. Hasznos lehet számukra az általános adatarchitektúra megismerése, beleértve a cikkben ismertetett vonatkozó korlátozásokat is. Tudassa velük, hogy a frissítési válaszok és az interaktív szűrés időnként lassú lehet. Amikor a jelentés felhasználói megértik, hogy miért történik teljesítménycsökkenés, kevésbé valószínű, hogy elveszítik a jelentésekbe és adatokba vetett bizalmat.
Ha változó adatforrásokról készít jelentéseket, mindenképpen tájékoztassa a jelentés felhasználóit a Frissítés gomb használatáról. Tudassa velük azt is, hogy előfordulhat, hogy következetlen eredmények láthatók, és hogy a jelentés frissítése megoldhatja a jelentésoldalon található esetleges következetlenségeket.
Kapcsolódó tartalom
A DirectQuery szolgáltatással kapcsolatos további információkért tekintse meg a következő erőforrásokat:
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: