Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() Power BI Desktop Power BI szolgáltatás
Power BI Desktop Power BI szolgáltatás ![]()
A főbb befolyásolók vizualizációja segít megérteni azokat a tényezőket, amelyek egy önt érdeklő metrikát hajtanak. Elemzi az adatokat, rangsorolja azokat a tényezőket, amelyek fontosak, és fő befolyásolóként jeleníti meg őket. Tegyük fel például, hogy szeretné megtudni, hogy mi befolyásolja az alkalmazottak forgalmát, amelyet más néven változásnak neveznek. Az egyik tényező lehet a munkaszerződés hossza, egy másik tényező pedig az ingázás ideje.
Ez a cikk részletes oktatóanyagot nyújt a főbb befolyásolók vizualizációinak a Power BI-ban való használatáról. Ismerteti a vizualizáció beállítását, az eredmények értelmezését és a gyakori problémák elhárítását. Ha meg szeretné tudni, hogy milyen tényezők befolyásolják az adatok adott kimenetelét – például az ügyfelek visszajelzését, az értékesítést vagy más metrikákat –, ez az útmutató segít a Power BI AI-alapú elemzési eszközeinek használatával végrehajtható elemzések beszerzésében.
Mikor érdemes használni a főbb befolyásolókat?
A főbb befolyásolók vizualizációja nagyszerű választás, ha a következőt szeretné:
- Ellenőrizze, hogy mely tényezők befolyásolják az elemzett metrikát.
- A tényezők relatív fontosságának kontrasztos ábrázolása. Például a rövid távú szerződések a hosszú távú szerződéseknél jobban befolyásolják a forgalomváltozást?
A főbb befolyásolók vizualizációjának jellemzői
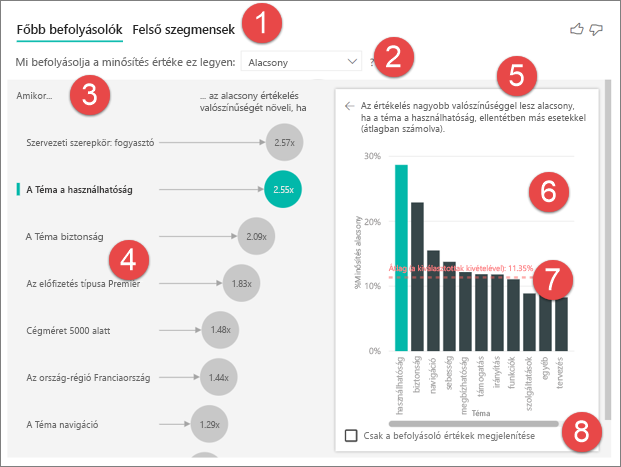
Lapok: Válasszon egy lapot, és váltson a nézetek között. A főbb befolyásolók a kiválasztott metrikaérték legfontosabb közreműködőit jelenítik meg. A felső szegmensek azokat a felső szegmenseket jelenítik meg, amelyek hozzájárulnak a kiválasztott metrikaértékhez. A szegmensek értékek kombinációjából áll. Az egyik szegmens lehet például az a fogyasztók, akik hosszú távú ügyfelek, és a nyugati régióban élnek.
Legördülő lista: A vizsgált metrika értéke. Ebben a példában nézze meg a metrika értékelést. A kijelölt érték alacsony.
Restatement: Segít értelmezni a vizualizációt a bal oldali panelen.
Bal oldali ablaktábla: A bal oldali panel egyetlen vizualizációt tartalmaz. Ebben az esetben a bal oldali panelen a legfontosabb befolyásolók listája látható.
Restatement: Segít értelmezni a vizualizációt a jobb oldali panelen.
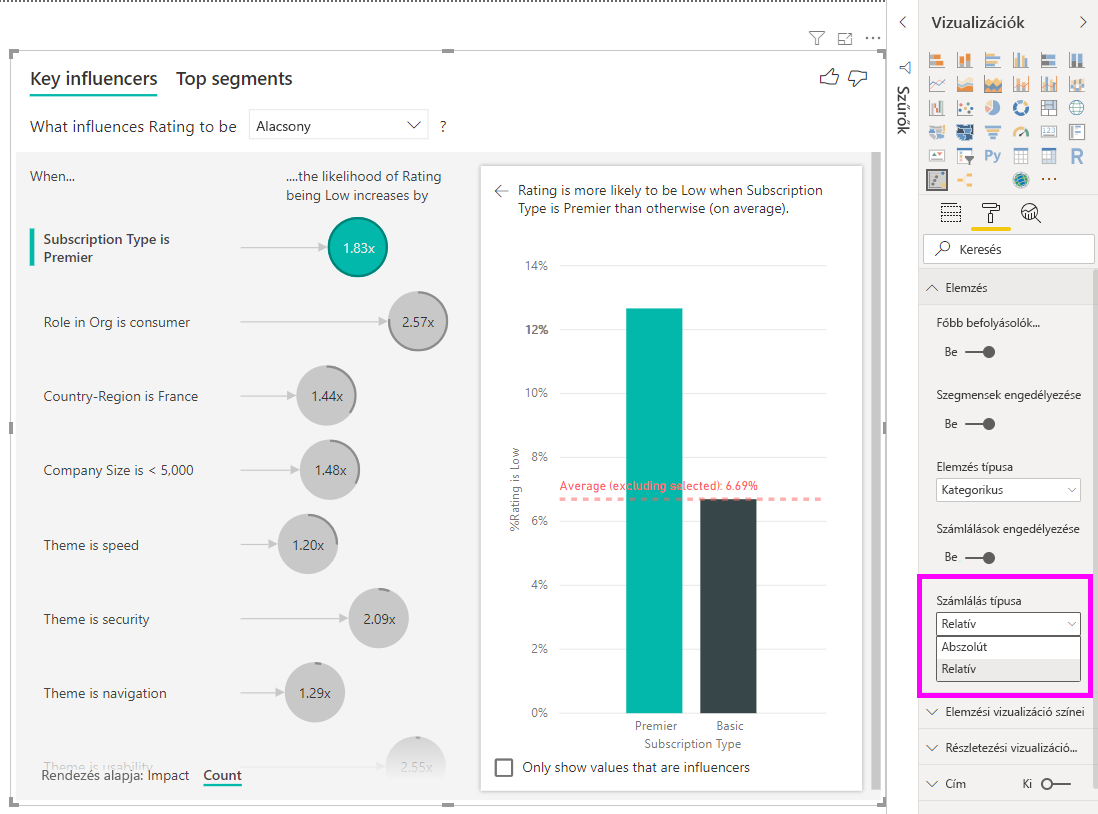
Jobb oldali ablaktábla: A jobb oldali panel egy vizualizációt tartalmaz. Ebben az esetben az oszlopdiagram a bal oldali panelen kiválasztott fő befolyásoló téma összes értékét megjeleníti. A bal oldali panel használhatóságának konkrét értéke zöld színnel jelenik meg. A Téma többi értéke fekete színben jelenik meg.
Átlagvonal: Az átlagot a téma összes lehetséges értékére számítjuk ki, kivéve a használhatóságot (amely a kiválasztott befolyásoló). A számítás tehát a fekete színben lévő összes értékre vonatkozik. Ez megmutatja, hogy a többi téma hány százaléka volt alacsony értékeléssel. Ebben az esetben a 11,35% alacsony értékelést kapott (a pontozott vonal mutatja).
Jelölőnégyzet: Szűri a vizualizációt a jobb oldali panelen, hogy csak az adott mező befolyásoló értékei jelenjenek meg.
Kategorikus metrikák elemzése
- A Termékmenedzser szeretné megtudni, hogy mely tényezők vezetik az ügyfeleket arra, hogy negatív véleményeket hagyjanak a felhőszolgáltatásról. A Power BI Desktopban való folytatáshoz nyissa meg a Customer Feedback PBIX fájlt.
Feljegyzés
Az Ügyfélvisszajelzés adatkészlet alapja [Moro et al., 2014] S. Moro, P. Cortez és P. Rita. "Adatvezérelt megközelítés a banki telemarketing sikerének előrejelzéséhez." Döntéstámogatási rendszerek, Elsevier, 62:22-31, 2014. június.
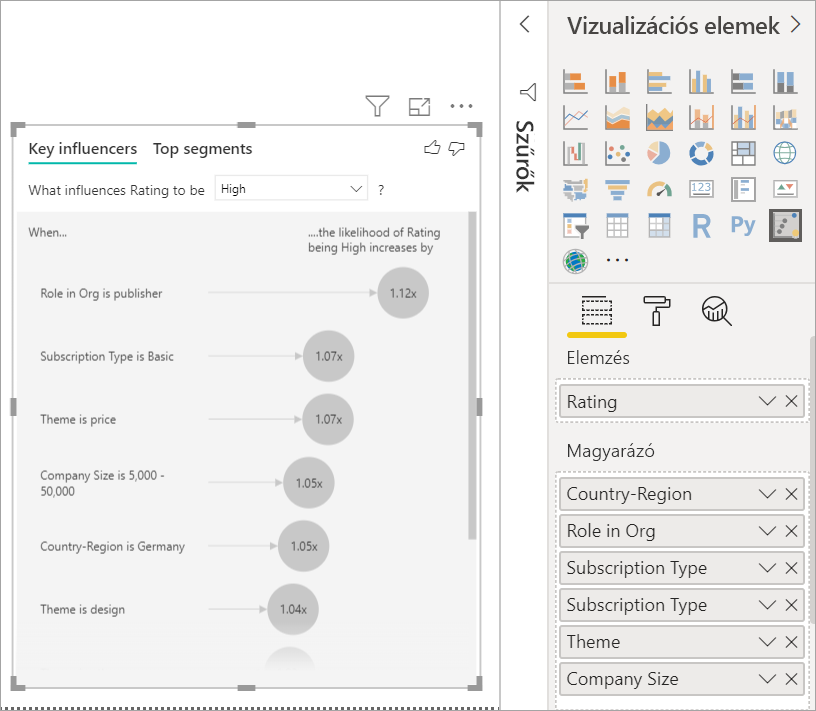
A Vizualizációk panelen a Vizuális létrehozása alatt válassza a Főbb befolyásolók ikont.
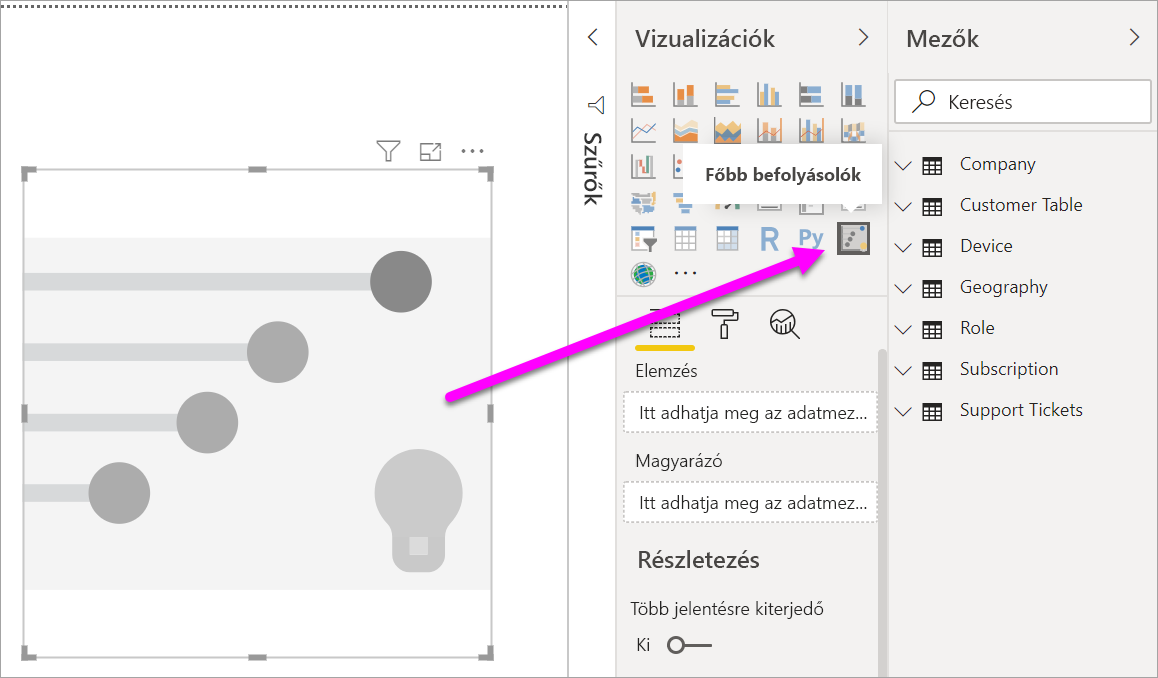
Helyezze át a vizsgálandó metrikát az Elemzés mezőbe. Ha meg szeretné tekinteni, hogy mi hajtja alacsonyra a szolgáltatás ügyfélminősítését, válassza a Customer Table Rating (Ügyféltábla-minősítés>) lehetőséget.
Helyezze át azokat a mezőket, amelyek véleménye szerint befolyásolhatják az Értékelés mezőt a Magyarázat mező szerint mezőbe. Tetszőleges számú mezőt áthelyezhet. Ebben az esetben kezdje a következőkkel:
- Ország-régió
- Szerepkör a szervezetben
- Előfizetés típusa
- Vállalat mérete
- Téma
Hagyja üresen a Bővítés mezőt. Ez a mező csak mérték vagy összegzett mező elemzésekor használatos.
Ha a negatív értékelésekre szeretne összpontosítani, válassza az Alacsony lehetőséget a Minősítést befolyásoló tényezők legördülő listában.
Az elemzés az elemzett mező táblaszintjén fut. Ebben az esetben ez az Értékelés metrika. Ez a metrika ügyfélszinten van definiálva. Minden ügyfél magas vagy alacsony pontszámot ad. Az összes magyarázó tényezőt az ügyfél szintjén kell meghatározni ahhoz, hogy a vizualizáció felhasználhassa őket.
Az előző példában az összes magyarázó tényező egy-az-egyhez vagy több-az-egyhez kapcsolattal rendelkezik a metrikával. Ebben az esetben minden ügyfél egyetlen témát rendelt hozzá az értékeléshez. Hasonlóképpen, az ügyfelek egy országból vagy régióból származnak, egy tagsági típussal rendelkeznek, és egy szerepkört töltenek be a szervezetükben. A magyarázó tényezők már az ügyfél attribútumai, és nincs szükség átalakításokra. A vizualizáció azonnal felhasználhatja őket.
Az oktatóanyag későbbi részében összetettebb példákat fog látni, amelyek egy-a-többhöz viszonyokkal rendelkeznek. Ezekben az esetekben az oszlopokat először az ügyfél szintjén kell összesíteni, mielőtt futtathatja az elemzést.
A magyarázó tényezőként használt mértékeket és aggregátumokat az Elemzés metrika táblaszintjén is kiértékeljük. Néhány példa a cikk későbbi részében látható.
Kategorikus kulcs befolyásolóinak értelmezése
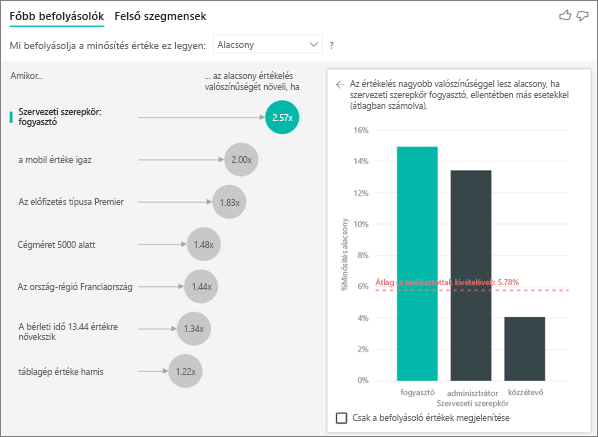
Vessünk egy pillantást az alacsony értékelések főbb befolyásolóira.
Az alacsony minősítés valószínűségét befolyásoló legfontosabb egyetlen tényező
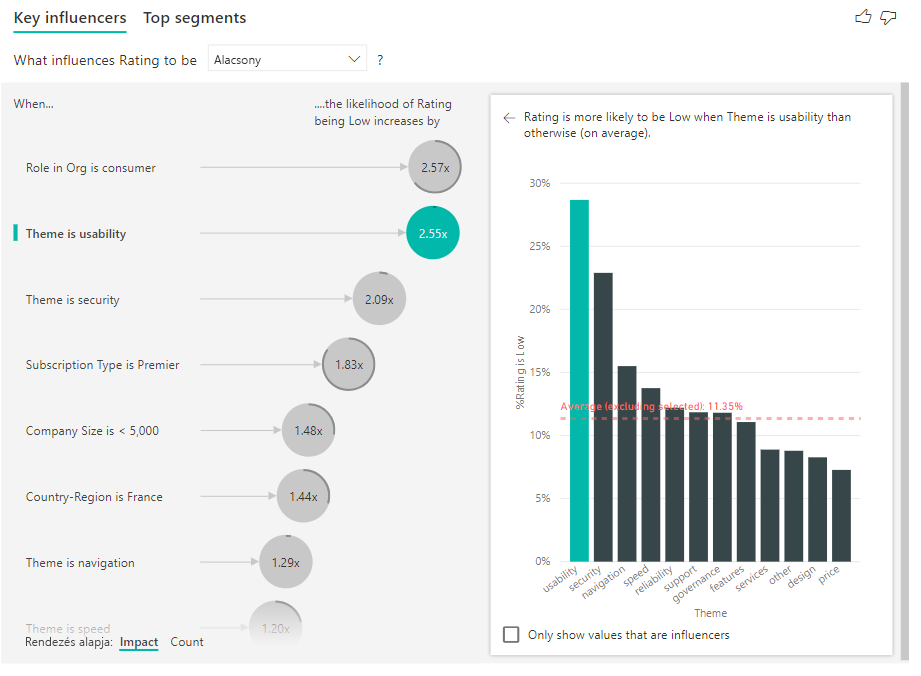
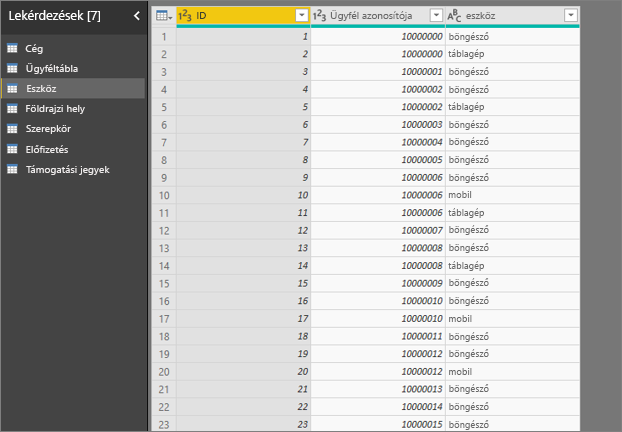
A példában szereplő ügyfél három szerepkör egyikével rendelkezhet: fogyasztó, rendszergazda vagy közzétevő. Fogyasztónak lenni a legfontosabb tényező, amely hozzájárul az alacsony értékeléshez.
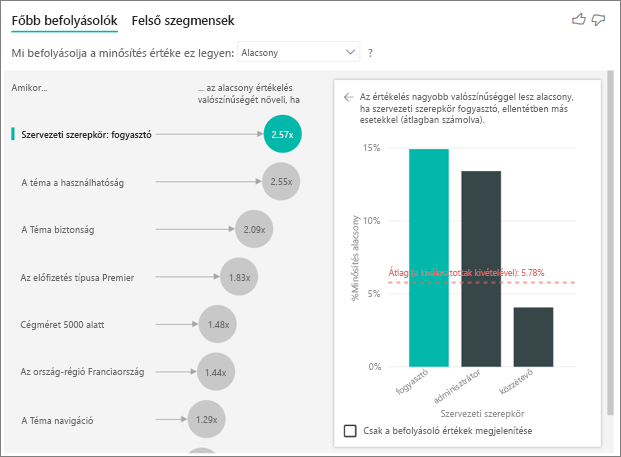
Pontosabban a fogyasztók 2,57-szer nagyobb valószínűséggel adnak negatív pontszámot a szolgáltatásnak. A főbb befolyásolók táblázatban az "Org szerepe: fogyasztó" szerepel elsőként a bal oldali listában. Ha kiválasztja a Szervezeti szerepkör a fogyasztó elemet, a Power BI több részletet jelenít meg a jobb oldali panelen. Az egyes szerepkörök összehasonlító hatása az alacsony minősítés valószínűségére látható.
- A fogyasztók 14,93%-a ad alacsony pontszámot.
- Átlagosan, az összes többi szerepkör az esetek 5,78%-ában ad alacsony pontszámot.
- A fogyasztók 2,57-szer nagyobb valószínűséggel adnak alacsony pontszámot az összes többi szerepkörhöz képest. Ezt a pontszámot úgy határozhatja meg, hogy elosztja a zöld sávot a piros pontozott vonallal.
A második egyetlen tényező, amely befolyásolja az alacsony minősítés valószínűségét
A főbb befolyásolók vizualizációja számos különböző változó tényezőit hasonlítja össze és rangsorolja. A második befolyásolónak semmi köze a szervezeti szerepkörhöz. Válassza ki a második befolyásolót a listában, amely a Téma használhatóság.
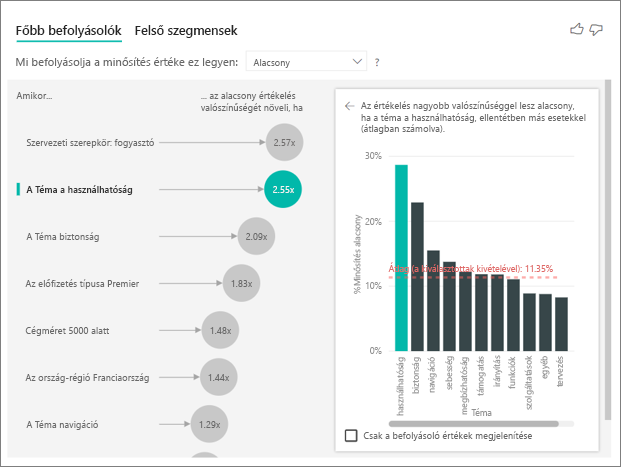
A második legfontosabb tényező az ügyfél véleményének témájához kapcsolódik. Azok az ügyfelek, akik a termék használhatóságával kapcsolatos megjegyzéseket fűztek, 2,55-szer nagyobb valószínűséggel adtak alacsony pontszámot, mint azok az ügyfelek, akik más témákat, például megbízhatóságot, kialakítást vagy sebességet kommentáltak.
A vizualizációk között a piros pontozott vonal által megjelenített átlag 5,78%-ról 11,35%-ra változott. Az átlag dinamikus, mert az összes többi érték átlagán alapul. Az első befolyásoló esetében az átlag kizárta az ügyfélszerepkört. A második befolyásoló esetében kizárta a használhatósági témát.
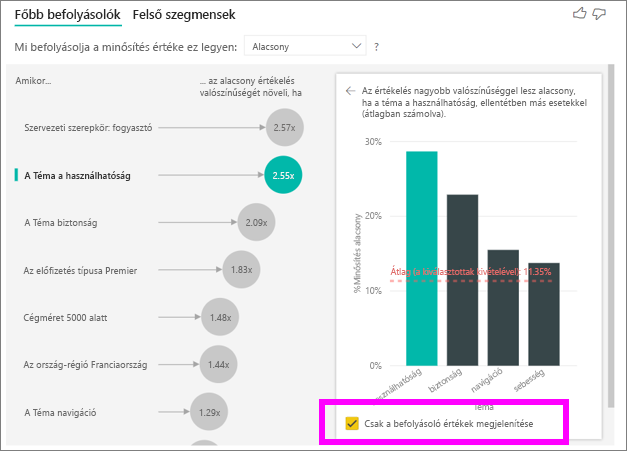
Jelölje be a Csak befolyásoló értékek megjelenítése jelölőnégyzetet, ha csak a befolyásoló értékek használatával szeretné szűrni az adatokat. Ebben az esetben ezek a szerepkörök eredményeznek alacsony pontszámot. 12 téma a Power BI által az alacsony értékeléseket eredményező témákként azonosított négy témára csökken.
Interakció más vizuális elemekkel
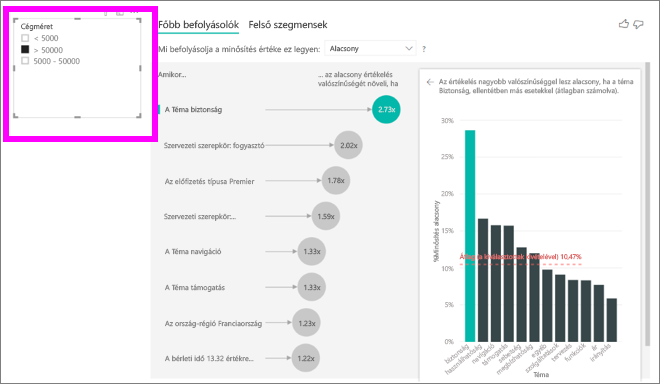
Minden alkalommal, amikor kiválaszt egy szeletelőt, szűrőt vagy más vizualizációt a vásznon, a főbb befolyásolók vizualizációja újrafuttatja az elemzést az új adatrészen. Áthelyezheti például a Cégméretet a jelentésbe, és szeletelőként használhatja. Ezzel megállapíthatja, hogy a vállalati ügyfelek fő befolyásolói eltérnek-e az általános populációtól. A vállalati vállalat mérete meghaladja az 50 000 alkalmazottat.
Az elemzés újrafuttatásához válassza >az 50 000-et , és láthatja, hogy a befolyásolók megváltoztak. A nagyvállalati ügyfelek számára az alacsony minősítések legfőbb befolyásolója a biztonsággal kapcsolatos témával rendelkezik. Érdemes lehet részletesebben megvizsgálnia, hogy vannak-e olyan biztonsági funkciók, amelyekkel a nagy ügyfelek elégedetlenek.
Folyamatos kulcs befolyásolóinak értelmezése
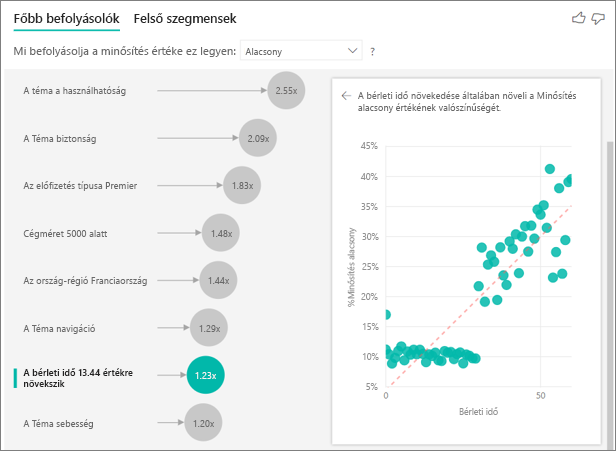
Eddig megtanulta, hogyan használhatja a vizualizációt annak vizsgálatára, hogy a különböző kategorikus mezők hogyan befolyásolják az alacsony értékeléseket. A Magyarázó mezőben folyamatos tényezők is lehetnek, például az életkor, a magasság és az ár. Nézzük meg, mi történik, ha az Ügyfél hűség átkerül az Ügyféltáblából a Magyarázó tényező mezőbe. A bérleti idő azt mutatja be, hogy az ügyfél mennyi ideig használja a szolgáltatást.
A bérleti idő növekedésével az alacsonyabb minősítések valószínűsége is nő. Ez a trend arra utal, hogy a hosszabb távú ügyfelek nagyobb valószínűséggel adnak negatív pontszámot. Ez az észrevétel érdekes, amit később érdemes lenne tovább követni.
A vizualizáció azt mutatja, hogy minden alkalommal, amikor a bérleti idő 13,44 hónappal nő, az alacsony minősítés valószínűsége átlagosan 1,23-szor nő. Ebben az esetben a 13,44 hónap a bérleti idő szórását ábrázolja. Tehát az elemzés azt vizsgálja, hogyan befolyásolja a munkaviszony egy standard eltérés mértékével történő növelése az alacsony minősítés valószínűségét.
A jobb oldali panelen lévő pontdiagram a szolgálati idő minden értékéhez az alacsony minősítések átlagos százalékos arányát ábrázolja. Trendvonallal emeli ki a meredekséget.
Rögzített folyamatos fő befolyásolók
Bizonyos esetekben előfordulhat, hogy a folyamatos tényezők automatikusan kategorikusakká lettek alakítva. Ha a változók közötti kapcsolat nem lineáris, nem írhatjuk le egyszerűen növekvő vagy csökkenő kapcsolatként (mint az előző példában).
Korrelációs teszteket futtatunk annak meghatározására, hogy a befolyásoló hogyan hasonlítható össze a célértékekkel. Ha a cél folyamatos, Pearson-korrelációt futtatunk; ha a cél kategorikus, point biserial korrelációs teszteket futtatunk. Ha azt észleljük, hogy a kapcsolat nem elég lineáris, felügyelt tárolót végzünk, és legfeljebb öt tárolót hozunk létre. Annak megállapításához, hogy mely tárolók a legérthetőbbek, egy felügyelt tárolóhelyezési módszert használunk. A felügyelt binning metódus a magyarázó tényező és az elemzett cél közötti kapcsolatot vizsgálja.
Mértékek és aggregátumok értelmezése fő befolyásolókként
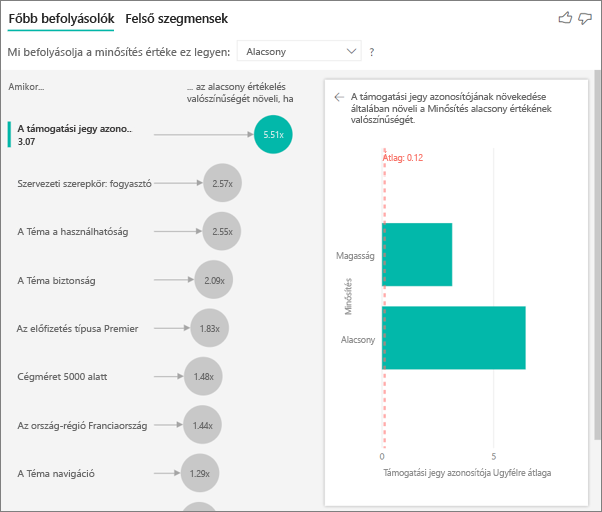
Az elemzésben mértékeket és aggregátumokat használhat magyarázó tényezőként. Például milyen hatással van az ügyfélszolgálati jegyek száma a kapott pontszámra. Vagy milyen hatással van egy nyitott jegy átlagos időtartama a kapott pontszámra.
Ebben az esetben azt szeretné megtudni, hogy az ügyfél által megadott támogatási jegyek száma befolyásolja-e az általuk adott pontszámot. Most be kell állítania a támogatási jegy azonosítóját a Támogatási jegyek táblából. Mivel egy ügyfél több támogatási jegyet is használhat, az azonosítót az ügyfél szintjén összesítheti. Az összesítés azért fontos, mert az elemzés az ügyfél szintjén fut, ezért az összes illesztőprogramot ezen a részletességi szinten kell meghatározni.
Nézzük meg az azonosítók számát. Az egyes ügyfél sorához tartozik egy támogatási jegyek száma. Ebben az esetben a támogatási jegyek számának növekedésével az alacsony minősítés valószínűsége 4,08-szor nő. A képernyőképen a támogatási jegyek átlagos száma látható az ügyfélszinten kiértékelt különböző minősítési értékek alapján.
Az eredmények értelmezése: Felső szegmensek
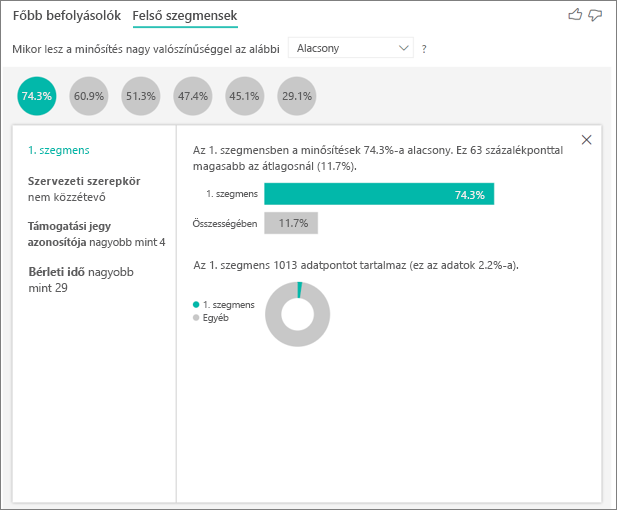
A Főbb befolyásolók lapon egyenként értékelheti az egyes tényezőket. A Felső szegmensek lapon azt is megtekintheti, hogy a tényezők kombinációja hogyan befolyásolja az elemzett metrikát.
A felső szegmensek kezdetben áttekintést ad a Power BI által felderített összes szegmensről. Az alábbi példa hat szegmenst mutat be. A rangsort a szegmensen belüli alacsony minősítések százalékos aránya határozza meg. Az 1. szegmens például 74,3%-os ügyfélminősítéssel rendelkezik, amelyek alacsonyak. Minél magasabb a buborék, annál nagyobb az alacsony értékelések aránya. A buborék mérete azt jelzi, hogy hány ügyfél van a szegmensben.
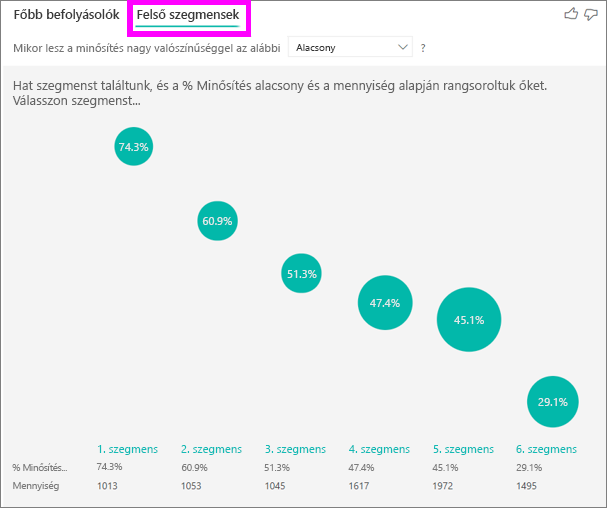
Ha kijelöl egy buborékot, az adott szegmens részleteit jeleníti meg. Ha például az 1. szegmenst választja, az a már meglévő ügyfeleket jelöli. Több mint 29 hónapja ügyfeleik, és négynél több támogatási jegyük van. Végül pedig nem kiadók, így vagy felhasználók vagy rendszergazdák.
Ebben a csoportban az ügyfelek 74,3%-a adott alacsony értékelést. Az átlagos ügyfél az idő 11,7%-át adta alacsony minősítéssel, így ez a szegmens nagyobb arányban rendelkezik alacsony értékelésekkel. Ez 63 százalékponttal magasabb. Az 1. szegmens az adatok körülbelül 2,2%-át is tartalmazza, így a populáció egy kezelhető részét képviseli.
Darabszámok hozzáadása
Előfordulhat, hogy a befolyásolók jelentős hatással bírnak, de kevés adatot képviselnek. Például: A téma a használhatóság, amely a harmadik legnagyobb befolyásoló tényező az alacsony értékelések esetében. Előfordulhat azonban, hogy csak néhány ügyfél panaszkodott a használhatóságra. A számokkal rangsorolhatja, hogy mely befolyásolókra szeretne összpontosítani.
A számokat a Formázás vizuális panel Elemzés kártyáján kapcsolhatja be.
A számok engedélyezése után egy gyűrű jelenik meg az egyes befolyásolók buborékja körül, amely a befolyásoló által tartalmazott adatok hozzávetőleges százalékos arányát jelöli. Minél több buborékot tartalmaz a gyűrű, annál több adatot tartalmaz. Láthatjuk, hogy Theme-nek a használhatóság szempontjából kis arányú adata van.
A vizualizáció bal alsó sarkában található Rendezés váltógombbal is rendezheti a buborékokat az ütközés helyett a darabszám alapján. Az előfizetés típusa a Premier a legnagyobb befolyásoló tényező a szám alapján.
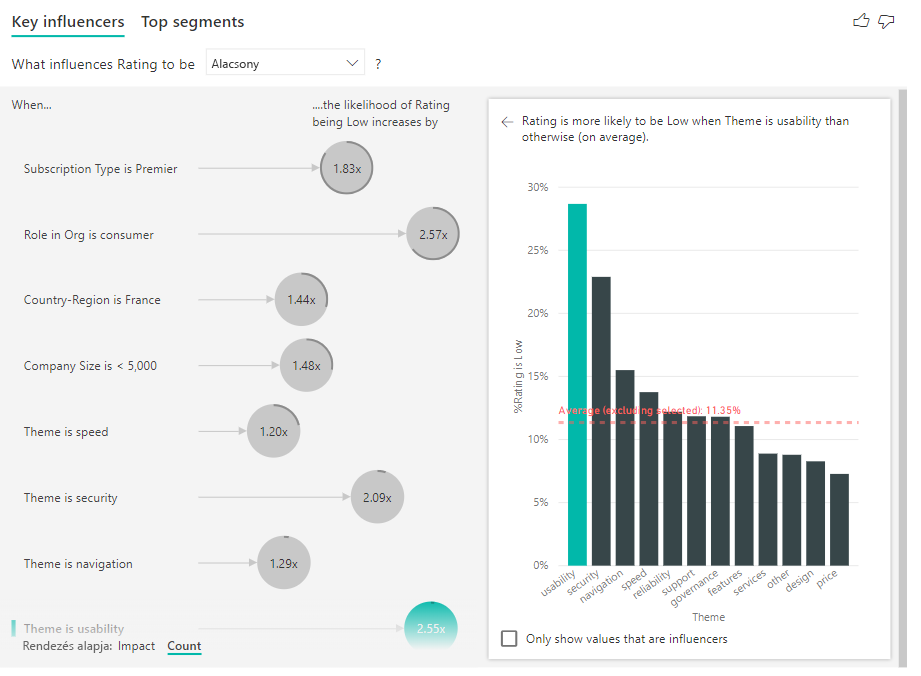
Ha a kör teljesen be van zárva, az azt jelenti, hogy a befolyási tényező az adatok 100%-át tartalmazza. A számtípust a Vizualizáció formázása panel Elemzés kártyáján található Darabszám típus legördülő menüben módosíthatja a legnagyobb befolyásolóhoz viszonyítva. Most a legtöbb adattal rendelkező befolyásolót egy teljes gyűrű jelöli, és az összes többi szám hozzá van viszonyítva.
Numerikus metrika elemzése
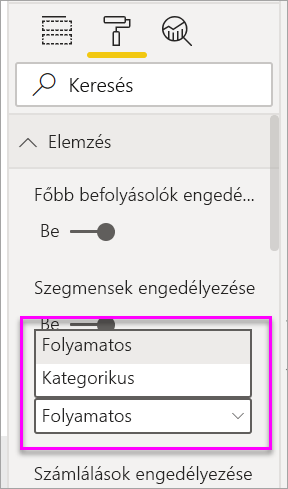
Ha össze nem foglalt numerikus mezőt helyez át az Elemzés mezőbe, lehetősége van választani, hogyan kezelje ezt a forgatókönyvet. A vizualizáció viselkedését módosíthatja a Vizualizáció formázása panelen, és válthat a kategorikus elemzés típusa és a folyamatos elemzés típusa között.
A cikk korábbi részében kategorikus elemzési típust ismertetünk. Ha például az 1 és 10 közötti felmérési pontszámokat tekinti meg, megkérdezheti, "Miért befolyásolják a tényezők, hogy a felmérési pontszámok 1-esek legyenek?"
A folyamatos elemzési típus folytonosra módosítja a kérdést. Az előző példában az új kérdés a következő: "Mi befolyásolja a felmérési pontszámokat a növekedéshez/csökkenéshez?"
Ez a különbség akkor hasznos, ha sok egyedi értéket tartalmaz az elemzett mezőben. A következő példában a lakásárakat vizsgáljuk meg. Nincs értelme azt kérdezni, hogy "Mi befolyásolja a házárat, hogy 156 214 legyen?", mivel ez konkrét, és valószínűleg nincs elég adatunk ahhoz, hogy következtetést vonjunk le valamilyen mintára.
Ehelyett érdemes megkérdezni, hogy "Mi befolyásolja a házárak emelkedését", ami lehetővé teszi számunkra, hogy a házárakat tartományként kezelhetjük, nem pedig különálló értékekként.
Az eredmények értelmezése: Főbb befolyásolók
Feljegyzés
Az ebben a szakaszban szereplő példák a nyilvános tartomány ingatlanárainak adatait használják. Ha követni szeretné, letöltheti a mintaadatkészletet.
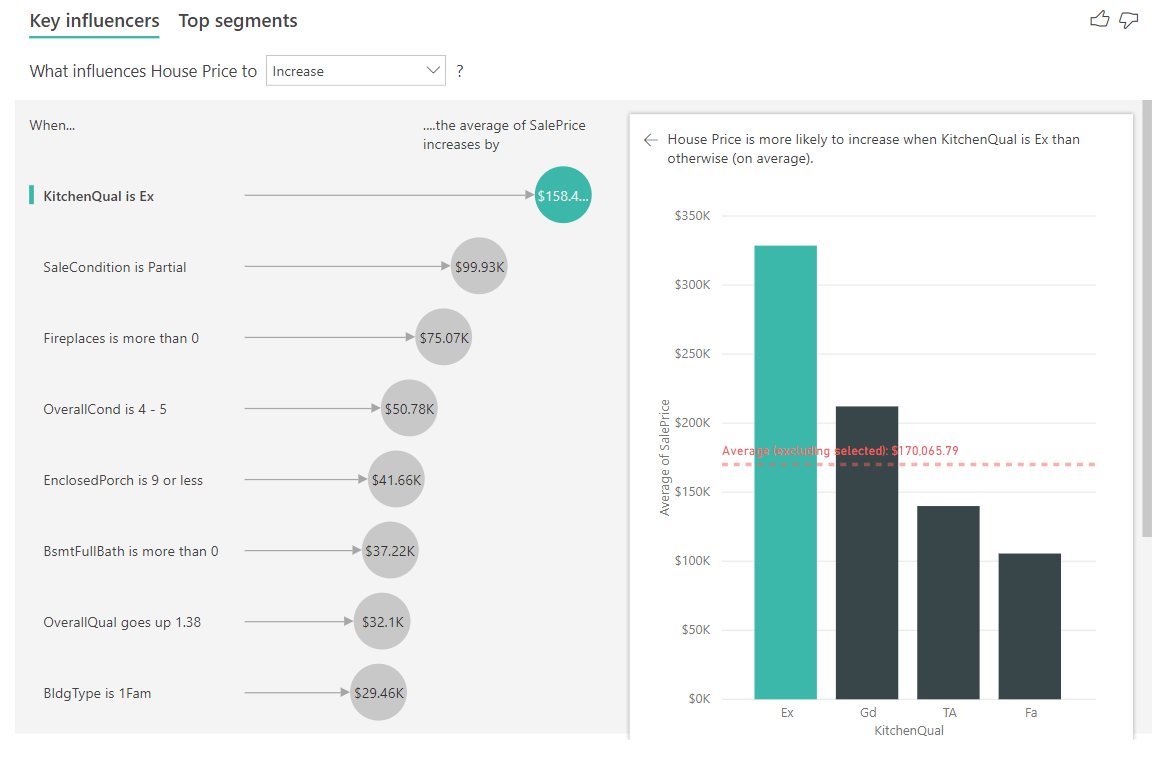
Ebben a forgatókönyvben a "What influences House Price to increase" (Mi befolyásolja a házárakat) című témakört vizsgáljuk meg. Számos magyarázó tényező befolyásolhatja a ház árát, például a Year Built (a ház építésének éve), a KitchenQual (konyha minősége) és a YearRemodAdd (a ház átépítésének éve).
Az alábbi példában a legfontosabb tényezőt vizsgáljuk, ami a kiváló konyhát jelenti. Az eredmények hasonlóak azokhoz, amelyeket a kategorikus metrikák elemzésekor láttunk néhány fontos különbséggel:
- A jobb oldali oszlopdiagram a százalékok helyett az átlagokat vizsgálja. Ezért megmutatja nekünk, hogy egy kiváló konyhával rendelkező ház átlagos ára (zöld sáv) hogyan viszonyul egy konyha nélküli ház átlagos árához (pontozott vonal).
- A buborékban lévő szám továbbra is a piros pontozott vonal és a zöld sáv közötti különbség, de a valószínűség (1,93x) helyett számként (\158,49 K USD) van kifejezve. Tehát átlagosan azok a házak, amelyek kiváló konyhával rendelkeznek, majdnem 160 ezer dollárral drágábbak, mint a házak, amelyek nem rendelkeznek kiváló konyhával.
A következő példában azt vizsgáljuk meg, hogy egy folyamatos tényező (az év házát átalakították) milyen hatással van a lakásárakra. A kategorikus metrikák folyamatos befolyásolóinak elemzésével kapcsolatos különbségek a következők:
- A jobb oldali panel pontdiagramja az egyes felújítás éveinek különböző értékeihez tartozó átlagos ingatlanárakat ábrázolja.
- A buborékban lévő érték azt mutatja, hogy mennyivel nő az átlagos ház ára (ebben az esetben 2,87 ezer USD), amikor a ház felújítási éve a szórásával nő (ebben az esetben 20 év).
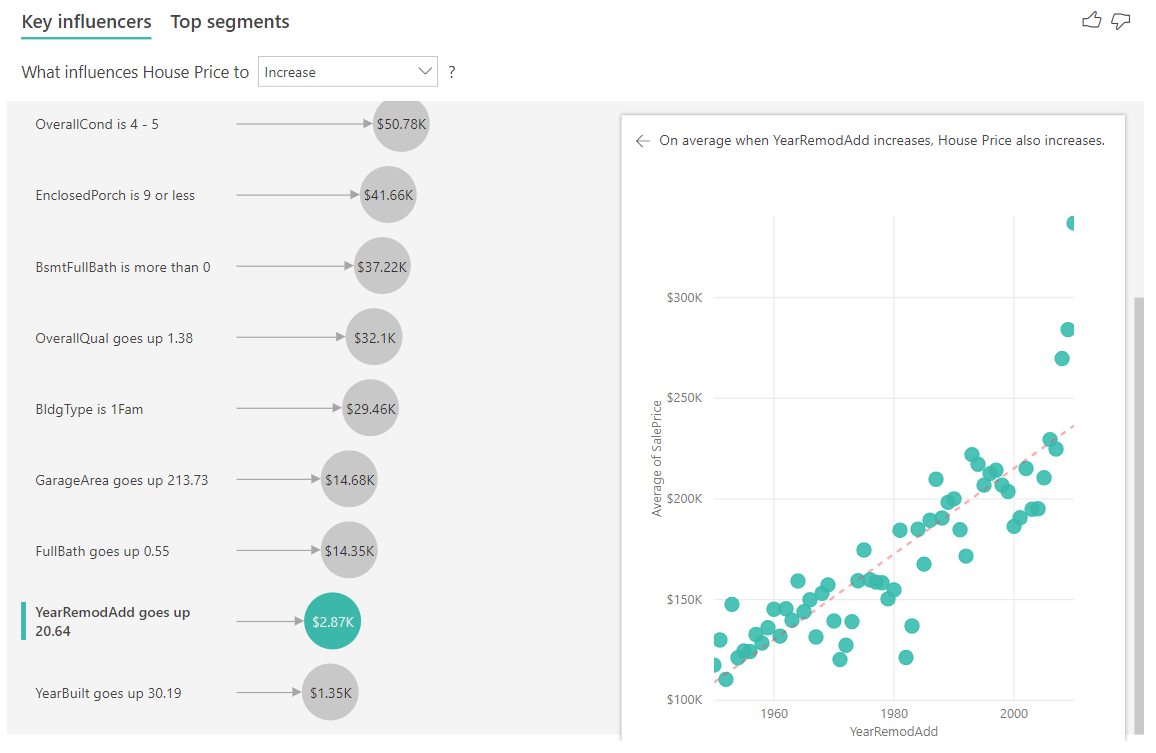
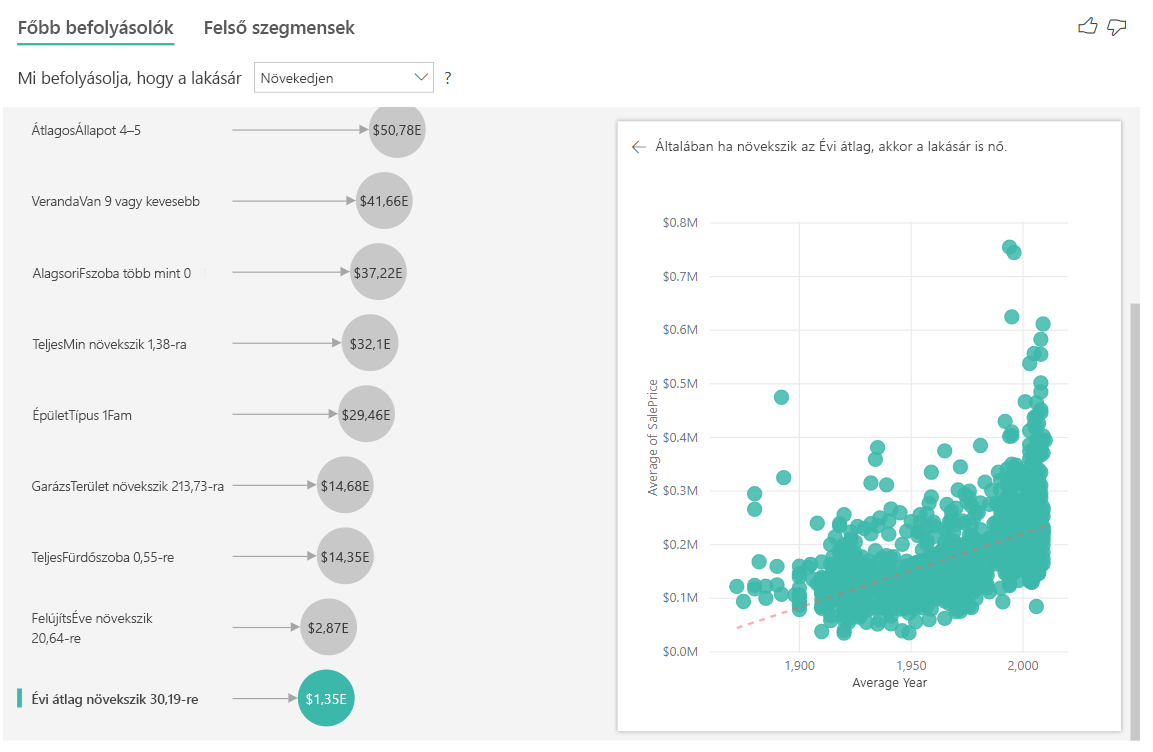
Végül az intézkedések esetében azt vizsgáljuk, hogy egy ház mely évben épült átlagosan. Az elemzés a következő:
- A jobb oldali panel pontdiagramja a táblázat egyes különböző értékeinek átlagos házárat ábrázolja.
- A buborék értéke azt mutatja, hogy mennyivel nő az átlagos lakásár (ebben az esetben 1 350 \$), amikor az átlagos évszám a szórásával (ebben az esetben 30 év) növekszik.
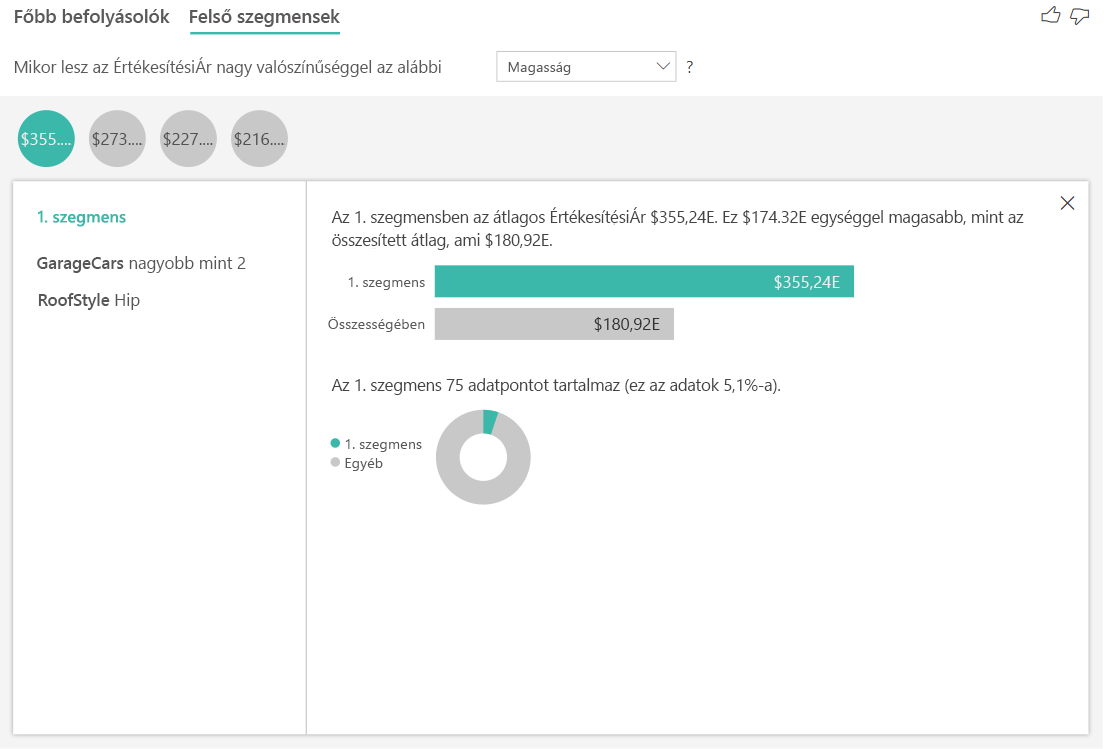
Az eredmények értelmezése a felső szegmensek használatával
A numerikus célok felső szegmensei olyan csoportokat mutatnak, ahol a lakásárak átlagosan magasabbak, mint a teljes adatkészletben. Az alábbiakban például láthatjuk, hogy az 1. szegmens olyan házakból áll, ahol a GarageCars (a garázsban elférő autók száma) nagyobb, mint 2, és a RoofStyle Hip. Az ilyen jellemzőkkel rendelkező házak átlagos ára 355 000 USD, szemben az adatok összesített, 180 000 USD-os átlagával.
Mérték vagy összegzett oszlop metrikáinak elemzése
Mérték vagy összegzett oszlop esetén az elemzés alapértelmezés szerint a cikk korábbi részében ismertetett folyamatos elemzési típusra mutat. Ezek az adatok nem módosíthatók. Az érték/összegzett oszlop és a nem összegzett numerikus oszlop elemzése között a legnagyobb különbség az a szint, amelyen az elemzés fut.
A nem kijelölt oszlopok esetében az elemzés mindig a tábla szintjén fut. A házár példájában elemeztük a Házár mutatót, hogy megnézzük, mi befolyásolja a házár növekedését vagy csökkenését. Az elemzés automatikusan a táblázat szintjén fut. A táblázat minden házhoz egyedi azonosítóval rendelkezik, így az elemzés házszinten fut.
A mértékek és az összesített oszlopok esetében nem tudjuk azonnal, hogy milyen szinten elemezzük őket. Ha a házárat átlagként összegezzük, akkor figyelembe kell vennünk, hogy milyen szinten szeretnénk kiszámítani ezt az átlagos lakásárat. Ez az átlagos házár a környék szintjén? Vagy talán regionális szinten?
A mértékeket és az összesített oszlopokat a rendszer automatikusan elemzi a használt mezők magyarázatának szintjén. Tegyük fel, hogy három mezőt szeretnénk megvizsgálni a Magyarázatban: Konyhaminőség, Épület típusa és Légkondicionáló. A házárak átlaga a három mező mindegyik egyedi kombinációjára számítható ki. Gyakran hasznos, ha táblázatnézetre vált, hogy lássa, hogyan néznek ki a kiértékelt adatok.
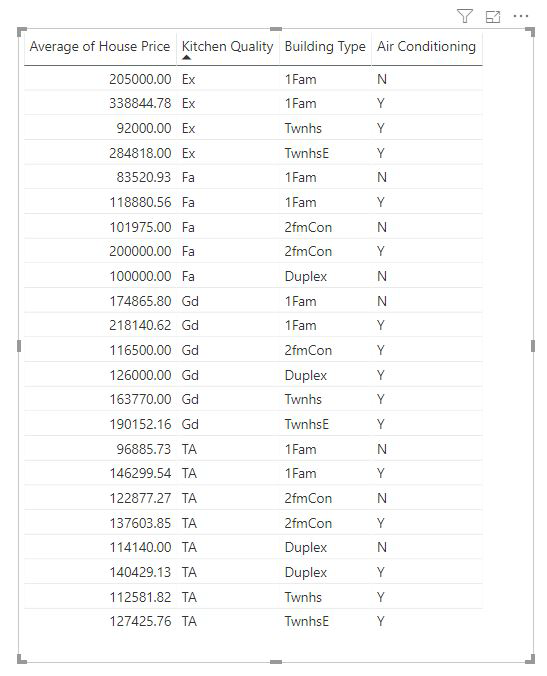
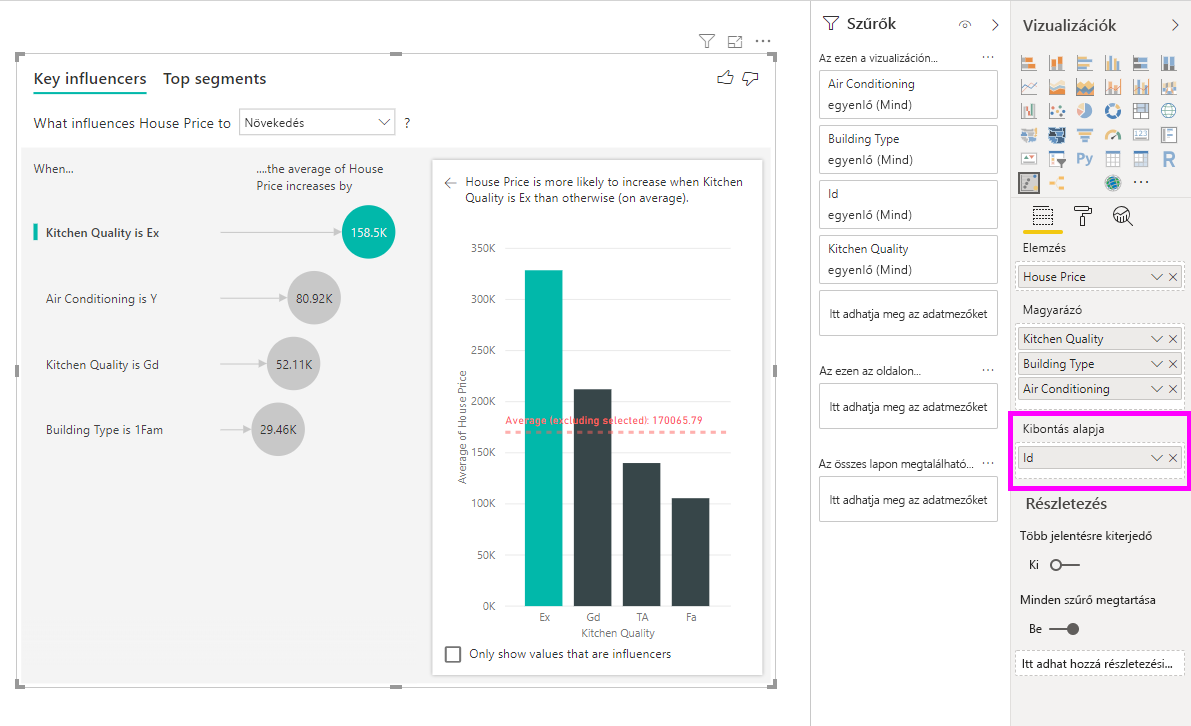
Ez az elemzés nagymértékben összefoglalva van, ezért a regressziós modell nehezen talál olyan mintákat az adatokban, amelyekből tanulhat. A jobb eredmények érdekében részletesebben kell futtatnunk az elemzést. Ha a lakásárat a ház szintjén szeretnénk elemezni, explicit módon hozzá kell adnunk az azonosító mezőt az elemzéshez. Mindazonáltal nem akarjuk, hogy a házazonosító befolyásolónak minősüljön. Nem hasznos rájönni arra, hogy a házazonosító növekedésével a ház ára nő. Itt hasznos lehet a Kibontás mező szerint lehetőség. A Kibontással olyan mezőket adhat hozzá, amelyeket az elemzés szintjének beállításához szeretne használni új befolyásolók keresése nélkül.
Tekintse meg, hogyan néz ki a vizualizáció, ha hozzáadjuk az azonosítót a Kibontás gombra. Miután meghatározta a mérték kiértékelésének szintjét, a befolyásolók értelmezése pontosan ugyanaz, mint a nem kijelölt numerikus oszlopok esetében.
Ha meg szeretné tudni, hogyan használja a Power BI az ML.NET-et a háttérben az adatok feldolgozásához és az információk természetes megjelenítéséhez, tekintse meg a Power BI azonosítja a kulcsfontosságú befolyásolókat az ML.NET segítségével című részt.
Megfontolandó szempontok és hibaelhárítás
Milyen korlátozások vonatkoznak a vizualizációra?
A főbb befolyásolók vizualizációja bizonyos korlátozásokkal rendelkezik:
- A Közvetlen lekérdezés nem támogatott.
- Az Azure Analysis Services és az SQL Server Analysis Services élő kapcsolata nem támogatott.
- A webes közzététel nem támogatott.
- A .NET-keretrendszer 4.6-os vagy újabb verziójára van szükség.
- A SharePoint Online-beágyazás nem támogatott.
- A kategorikus metrikák elemzése nem támogatott, ha az implicit mértékek elriasztásaigaz értékre van állítva az adatmodellben (például amikor számítási csoportok vannak definiálva az adatmodellben).
Látom, hogy hiba történt, mert nem találhatók befolyásolók vagy szegmensek. Ennek mi az oka?
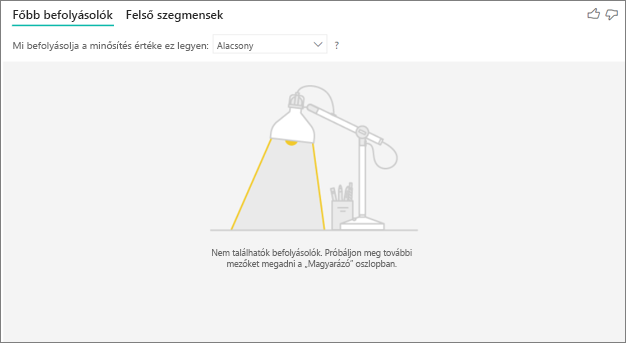
Ez a hiba akkor fordul elő, ha mezőket adott hozzá a Magyarázat alapján, de nem találtak befolyásolókat. Ellenőrizze, hogy az alábbi problémák valamelyike alkalmazható-e.
- Az Elemzésbe és Magyarázatba is belevette azt a metrikát, amit elemezett. Távolítsa el az Explain by funkcióból.
- A magyarázó mezők túl sok kategóriával rendelkeznek, kevés megfigyeléssel. Ez a helyzet megnehezíti a vizualizáció számára, hogy meghatározza, mely tényezők befolyásoló tényezők. Csak néhány megfigyelés alapján nehéz általánosítani. Numerikus mező elemzésekor érdemes lehet kategorikus elemzésrőlfolyamatos elemzésre váltani az Elemzés kártya Formátum vizualizáció paneljén.
- A magyarázó tényezőknek elegendő megfigyelésük van az általánosításhoz, de a vizualizáció nem talált értelmes összefüggéseket a jelentéshez.
Hibaüzenet jelenik meg, hogy az elemzett metrikának nincs elég adata az elemzés futtatásához. Ennek mi az oka?
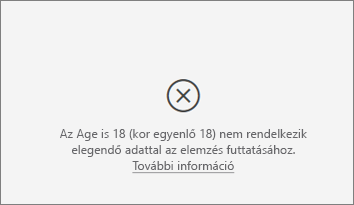
A vizualizáció úgy működik, hogy egy csoport adatainak mintáit tekinti meg a többi csoporthoz képest. Például azokat az ügyfeleket keresi, akik alacsony értékelést adtak a magas értékelést adó ügyfelekhez képest. Ha a modell adatainak csak néhány megfigyelése van, a mintákat nehéz megtalálni. Ha a vizualizáció nem rendelkezik elegendő adatval az értelmes befolyásolók megtalálásához, az azt jelzi, hogy több adatra van szükség az elemzés futtatásához.
Javasoljuk, hogy legalább 100 megfigyelése legyen a kiválasztott állapotra vonatkozóan. Ebben az esetben az állapot azokat az ügyfeleket jelenti, akik elhagyták a szolgáltatást. Az összehasonlításhoz használt állapotokhoz legalább 10 megfigyelésre van szükség. Ebben az esetben az összehasonlítási állapot azok az ügyfelek, akik nem lemorzsolódnak.
Numerikus mező elemzésekor érdemes lehet kategorikus elemzésrőlfolyamatos elemzésre váltani az Elemzés kártya Formátum vizualizáció paneljén.
Hibaüzenet jelenik meg, amely szerint ha az "Elemzés" nincs összegezve, az elemzés mindig a szülőtábla sorszintjén fut. A szintet a "Kibővítés szerint" mezők használatával történő módosítás nem engedélyezett. Ennek mi az oka?
Numerikus vagy kategorikus oszlopok elemzésekor az elemzés mindig a táblázat szintjén fut. Ha például a lakásárakat elemzi, és a táblázat egy azonosító oszlopot tartalmaz, az elemzés automatikusan a házazonosító szintjén fut.
Mérték vagy összegzett oszlop elemzésekor explicit módon meg kell adnia, hogy az elemzés mely szinten fusson. A Kibontás használatával új befolyásolók hozzáadása nélkül módosíthatja a mértékek és az összesített oszlopok elemzési szintjét. Ha a ház árát mértékként definiálták, hozzáadhatja a házazonosító oszlopot a Bővítéshez az elemzés szintjének módosításához.
Hibaüzenet jelenik meg, amely szerint a Explain by mező nem kapcsolódik egyedileg az elemzett metrikát tartalmazó táblához. Ennek mi az oka?
Az elemzés az elemzett mező táblaszintjén fut. Ha például a szolgáltatáshoz tartozó ügyfélvisszajelzéseket elemzi, lehet, hogy van egy táblázata, amelyből megtudhatja, hogy egy ügyfél magas vagy alacsony értékelést adott-e. Ebben az esetben az elemzés az ügyféltábla szintjén fut.
Ha a metrikát tartalmazó táblánál részletesebben van definiálva egy kapcsolódó tábla, akkor ez a hiba jelenik meg. Íme egy példa:
- Elemezheti, hogy mi készteti az ügyfeleket arra, hogy alacsony értékelést adjanak a szolgáltatásáról.
- Szeretné megtudni, hogy az az eszköz, amelyen az ügyfél használja a szolgáltatást, befolyásolja-e az általuk adott véleményeket.
- Az ügyfél többféleképpen is használhatja a szolgáltatást.
- Az alábbi példában az 10000000 ügyfél böngészőt és táblagépet is használ a szolgáltatás használatához.
Ha az eszközoszlopot próbálja magyarázó tényezőként használni, a következő hibaüzenet jelenik meg:

Ez a hiba azért jelenik meg, mert az eszköz nincs ügyfélszinten definiálva. Egy ügyfél több eszközön is használhatja a szolgáltatást. Ahhoz, hogy a vizualizáció mintákat találjon, az eszköznek az ügyfél attribútumának kell lennie. Számos megoldás létezik, amelyek a vállalkozás megértésétől függnek:
- Az eszközök összegzésének módját megváltoztathatja. Használja például a darabszámot, ha az eszközök száma befolyásolhatja az ügyfél által megadott pontszámot.
- Az eszközoszlop elforgatásával megállapíthatja, hogy a szolgáltatás adott eszközön való használata befolyásolja-e az ügyfél minősítését.
Ebben a példában az adatok átalakítása során új oszlopokat hozunk létre a böngészőre, mobilra és táblagépre. Az adatok átalakítása után törölje és hozza létre újra a kapcsolatokat a modellező nézetben. Most már használhatja ezeket az eszközöket a Magyarázó alkalmazásban. Minden eszközről kiderül, hogy befolyásolók, és a böngésző a legnagyobb hatással van az ügyfél pontszámára.
Pontosabban azok az ügyfelek, akik nem használják a böngészőt a szolgáltatás használatára, 3,79-szer nagyobb valószínűséggel adnak alacsony pontszámot, mint az ügyfelek. A listában lejjebb az inverz igaz a mobileszközökre. A mobilalkalmazást használó ügyfelek nagyobb valószínűséggel adnak alacsony pontszámot, mint azok az ügyfelek, akik nem.
Figyelmeztetést látok, hogy a mértékek nem szerepelnek az elemzésemben. Ennek mi az oka?
Az elemzés az elemzett mező táblaszintjén fut. Ha elemzi az ügyféllemorzsolódást, lehet, hogy van egy táblázata, amely jelzi, hogy egy ügyfél lemorzsolódott-e vagy sem. Ebben az esetben az elemzés az ügyféltábla szintjén fut.
Alapértelmezés szerint a mértékek és az összesítések alapértelmezés szerint a táblázat szintjén vannak elemezve. Ha lenne egy mérték az átlagos havi kiadásokhoz, az az ügyféltábla szintjén lenne elemezve.
Ha az ügyféltábla nem rendelkezik egyedi azonosítóval, nem értékelheti ki a mértéket, és az elemzés figyelmen kívül hagyja. A helyzet elkerülése érdekében győződjön meg arról, hogy a metrika táblája egyedi azonosítóval rendelkezik. Ebben az esetben ez az ügyféltábla, az egyedi azonosító pedig az ügyfélazonosító. A Power Query használatával is könnyen felvehet indexoszlopot.
Figyelmeztetés jelenik meg, hogy az elemzett metrika több mint 10 egyedi értékkel rendelkezik, és ez az összeg befolyásolhatja az elemzés minőségét. Ennek mi az oka?
Az AI-vizualizáció kategorikus mezőket és numerikus mezőket elemezhet. Kategorikus mezők esetén például a forgalom igen vagy nem, az ügyfél-elégedettség pedig magas, közepes vagy alacsony. Az elemezni kívánt kategóriák számának növelése azt jelenti, hogy kategóriánként kevesebb megfigyelés van. Ez a helyzet megnehezíti, hogy a vizualizáció mintákat találjon az adatokban.
Numerikus mezők elemzésekor lehetőség van a numerikus mezők szövegként való kezelésére, amely esetben ugyanazt az elemzést futtatja, mint a kategorikus adatok esetében (kategorikus elemzés). Ha sok különböző értékkel rendelkezik, javasoljuk, hogy az elemzést folyamatos elemzésre váltsa, mivel ez azt jelenti, hogy a számok növekedéséből vagy csökkenéséből következtethetünk ahelyett, hogy különálló értékekként kezelnénk őket. A Kategorikus elemzésrőlfolyamatos elemzésre válthat az Analysis kártya Vizualizáció formázása paneljén.
Az erősebb befolyásolók megtalálásához javasoljuk, hogy a hasonló értékeket egyetlen egységbe csoportosítsa. Például, ha rendelkezik egy árkategóriával, valószínűleg jobb eredményeket érhet el, ha a hasonló árakat Magas, Közepes és Alacsony kategóriákba csoportosítja az egyes árpontok használata helyett.
Vannak olyan tényezők az adataimban, amelyek úgy néznek ki, mintha kulcsfontosságú befolyásolók lennének, de nem azok. Hogyan történhet ez meg?
Az alábbi példában a fogyasztók alacsony értékeléseket eredményeznek, a minősítések 14,93%-a alacsony. A rendszergazdai szerepkör esetében is magas az alacsony értékelések aránya, 13,42%%, ám mégsem tekinthető befolyásolónak.
Ennek a meghatározásnak az az oka, hogy a vizualizáció az adatpontok számát is figyelembe veszi, amikor befolyásolókat talál. Az alábbi példában több mint 29 000 felhasználó és tízszer kevesebb rendszergazda van, körülbelül 2900. Közülük csak 390 adott alacsony értékelést. A vizualizáció nem rendelkezik elegendő adattal annak meghatározásához, hogy talált-e mintát a rendszergazdák értékeléseiben, vagy csak véletlen megállapításról van-e szó.
Milyen adatpontkorlátok vonatkoznak a főbb befolyásolókra?
Az elemzést 10 000 adatpontból álló mintán futtatjuk. Az egyik oldalon a buborékok az összes befolyásolót mutatják, amelyeket találtak. A másik oldalon lévő oszlopdiagramok és pontdiagramok betartják az alapvető vizualizációk mintavételezési stratégiáit.
Hogyan számíthatók ki a főbb befolyásolók a kategorikus elemzéshez?
A háttérben az AI-vizualizáció a ML.NET használatával futtat logisztikai regressziót a főbb befolyásolók kiszámításához. A logisztikai regresszió olyan statisztikai modell, amely különböző csoportokat hasonlít össze egymással.
Ha látni szeretné, hogy mi vezérli az alacsony értékeléseket, a logisztikai regresszió azt vizsgálja, hogy az alacsony pontszámot adó ügyfelek miben különböznek a magas pontszámot adó ügyfelektől. Ha több kategóriával rendelkezik, például magas, semleges és alacsony pontszámokkal, meg kell vizsgálnia, hogy az alacsony értékelést adó ügyfelek miben különböznek azoktól az ügyfelektől, akik nem adtak alacsony értékelést. Ebben az esetben miben különböznek az alacsony pontszámot adó ügyfelek azoktól az ügyfelektől, akik magas vagy semleges értékelést adtak?
A logisztikai regresszió mintázatokat keres az adatokban, és azt keresi, hogy az alacsony értékelést adó ügyfelek miben különbözhetnek a magas értékelést adó ügyfelektől. Előfordulhat például, hogy a több támogatási jeggyel rendelkező ügyfelek magasabb százalékban adnak alacsony minősítést, mint a kevés vagy nem támogatott jegyekkel rendelkező ügyfelek.
A logisztikai regresszió azt is figyelembe veszi, hogy hány adatpont található. Ha például a rendszergazdai szerepkörrel rendelkező ügyfelek arányosan több negatív pontszámot adnak, de csak néhány rendszergazda van, ez a tényező nem tekinthető befolyásosnak. Ezt a meghatározást azért kell meghatározni, mert nincs elegendő adatpont egy minta következtetéséhez. A statisztikai teszt, más néven Wald-teszt, annak meghatározására szolgál, hogy egy tényező befolyásolónak minősül-e. A vizualizációban a p-érték 0,05, amely a küszöbérték meghatározására szolgál.
Hogyan számíthatók ki a főbb befolyásolók a numerikus elemzéshez?
A színfalak mögött az AI-vizualizáció a ML.NET használatával futtat lineáris regressziót a főbb befolyásolók kiszámításához. A lineáris regresszió egy statisztikai modell, amely a magyarázó tényezők alapján vizsgálja meg, hogy az elemzett mező milyen eredményt ad a változásoknak.
Ha például a lakásárakat elemezzük, a lineáris regresszió azt vizsgálja, hogy a kiváló konyha milyen hatással van a lakásárakra. A kiváló konyhával rendelkező házak általában alacsonyabbak vagy magasabbak a házárakhoz képest, mint a kiváló konyha nélküli házak?
A lineáris regresszió az adatpontok számát is figyelembe veszi. Ha például a teniszpályákkal rendelkező házak magasabb árakkal rendelkeznek, de kevés teniszpályával rendelkező házunk van, ez a tényező nem tekinthető befolyásosnak. Ezt a meghatározást azért kell meghatározni, mert nincs elegendő adatpont egy minta következtetéséhez. A statisztikai teszt, más néven Wald-teszt, annak meghatározására szolgál, hogy egy tényező befolyásolónak minősül-e. A vizualizációban a p-érték 0,05, amely a küszöbérték meghatározására szolgál.
Hogyan számítja ki a szegmenseket?
A színfalak mögött az AI-vizualizáció a ML.NET-et használja egy döntési fa futtatásához, hogy érdekes alcsoportokat találjon. A döntési fának az a célja, hogy olyan adatpontok alcsoportja legyen, amelyek viszonylag magasak az Ön számára fontos metrikában. Lehet, hogy alacsony minősítéssel rendelkező ügyfelek vagy magas árakkal rendelkező házak.
A döntési fa minden magyarázó tényezőt figyelembe vesz, és megpróbálja indokolni, hogy melyik tényező adja a legjobb felosztást. Ha például úgy szűri az adatokat, hogy csak nagyvállalati ügyfeleket tartalmazzon, az elkülöníti a magas értékelést és az alacsony minősítést adó ügyfeleket? Vagy talán jobb szűrni az adatokat, hogy csak azokat az ügyfeleket tartalmazza, akik megjegyzést fűztek a biztonsághoz?
A döntési fa felosztása után az adatok alcsoportját veszi fel, és meghatározza az adatok következő legjobb felosztását. Ebben az esetben az alcsoport az ügyfelek, akik megjegyzést fűztek a biztonsághoz. Az egyes felosztások után a döntési fa azt is figyelembe veszi, hogy elegendő adatponttal rendelkezik-e ahhoz, hogy a csoport elég reprezentatív legyen ahhoz, hogy mintázatot lehessen kikövetkeztetni. Ha nem, akkor ez egy anomália az adatokban, és nem valódi szegmens. Egy másik statisztikai tesztet alkalmazunk a felosztási feltétel statisztikai pontosságának ellenőrzésére 0,05 p-értékkel.
A döntési fa futása után az összes felosztást végrehajtja, például biztonsági megjegyzéseket és nagyvállalati beállításokat, és Power BI-szűrőket hoz létre. A szűrők e kombinációja szegmensként van csomagolva a vizualizációban.
Miért válnak bizonyos tényezők befolyásolókká, vagy miért nem lesznek befolyásolók, amikor több mezőt helyezek át a Magyarázatba?
A vizualizáció az összes magyarázó tényezőt együtt értékeli ki. Egy tényező önmagában is befolyásoló lehet, de más tényezőkkel együtt figyelembe véve nem feltétlenül. Tegyük fel, hogy azt szeretné elemezni, hogy mi okozza a házárak magas szintre emelkedését, ahol a hálószobák száma és a ház mérete magyarázó tényezők lehetnek.
- Önmagában több hálószoba lehet az oka annak, hogy az ingatlanárak magasak legyenek.
- Ha beleszámítva a ház méretét az elemzésbe, az azt jelenti, hogy most megnézzük, mi történik a hálószobákkal, miközben a ház mérete állandó marad.
- Ha a ház mérete 1500 négyzetméteren van rögzítve, nem valószínű, hogy a hálószobák számának folyamatos növekedése jelentősen növeli a ház árát.
- A hálószobák talán nem olyan fontos tényezők, mint korábban, mikor a ház méretét vették figyelembe.
A jelentés Power BI-munkatárssal való megosztásához külön Fabric- vagy Power BI Pro-licenccel kell rendelkeznie, vagy a jelentést prémium szintű kapacitásba kell mentenie. Lásd a megosztási jelentéseket.