Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A fürt értékei automatikusan létrehoznak hasonló értékekkel rendelkező csoportokat egy homályos illesztési algoritmus használatával, majd az egyes oszlopok értékét a legjobban illeszkedő csoporthoz rendelik. Ez az átalakítás akkor hasznos, ha olyan adatokkal dolgozik, amelyek számos különböző variációval rendelkeznek ugyanannak az értéknek, és az értékeket konzisztens csoportokba kell egyesítenie.
Vegyünk egy mintatáblát egy azonosító oszlopmal, amely azonosítókat és egy Person oszlopot tartalmaz, amelyek a Miguel, Mike, William és Bill nevek különböző helyesírású és nagybetűs verzióit tartalmazzák.
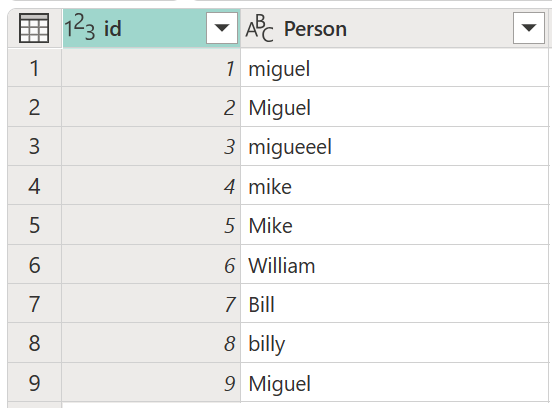
Ebben a példában a keresett eredmény egy új oszlopot tartalmazó táblázat, amely a Személy oszlopban szereplő értékek megfelelő csoportjait jeleníti meg, és nem az azonos szavak különböző változatait.
Megjegyzés:
A "Cluster values" funkció csak a Power Query Online-hoz érhető el.
Klaszter oszlop létrehozása
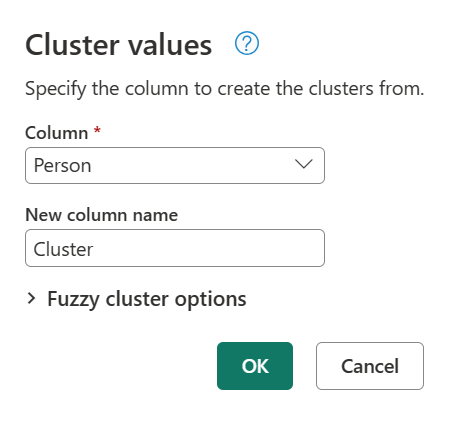
Fürtértékek esetén először jelölje ki a Személy oszlopot, lépjen a menüszalag Oszlop hozzáadása lapjára, majd válassza a Fürtértékek lehetőséget.
![]()
A Fürtértékek párbeszédpanelen erősítse meg a fürtök létrehozásához használni kívánt oszlopot, és adja meg az oszlop új nevét. Ebben az esetben nevezze el ezt az új oszlopot Cluster-nek.
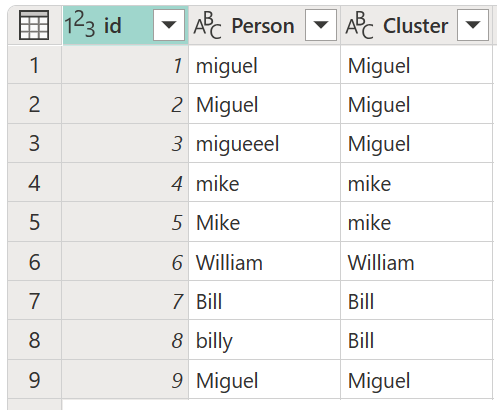
A művelet eredménye az alábbi képen látható.
Megjegyzés:
A Power Query minden egyes értékhalmaz esetében a kiválasztott oszlopból a leggyakrabban előforduló értéket választja ki "kanonikus" értékként. Ha több példány is előfordul ugyanazzal a gyakorisággal, a Power Query az elsőt választja ki.
A homályos klaszterezési beállítások használata
Az új oszlopban lévő értékek csoportosítására az alábbi lehetőségek érhetők el:
- Hasonlóság küszöbértéke (nem kötelező): Ez a beállítás jelzi, milyen mértékben kell a két értéknek hasonlónak lennie ahhoz, hogy csoportosíthatók legyenek. A nulla (0) minimális beállítása miatt az összes érték csoportosítva lesz. Az 1 érték maximális beállítása csak a pontosan egyező értékek csoportosítását teszi lehetővé. Az alapértelmezett érték 0,8.
- Kis- és nagybetűk figyelmen kívül hagyása: Szövegstringek összehasonlítása esetén a kis- és nagybetűket figyelmen kívül hagyják. Ez a beállítás alapértelmezés szerint engedélyezve van.
- Csoportosítás szövegrészek kombinálásával: Az algoritmus megpróbálja egyesíteni a szövegrészeket (például a Micro és a Soft egyesítését a Microsofttal) az értékek csoportosításához.
- Hasonlósági pontszámok megjelenítése: A bemeneti értékek és a számított reprezentatív értékek közötti hasonlósági pontszámokat jeleníti meg a homályos fürtözés után.
- Transzformációs táblázat (nem kötelező):Kiválaszthat egy olyan átalakítási táblát, amely az értékeket leképezi (például az MSFT-et a Microsofthoz rendeli), hogy csoportosítsa őket.
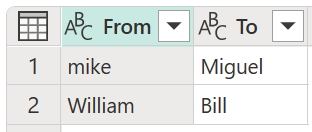
Ebben a példában egy új, Az átalakító tábla nevű átalakítási táblázat az értékek leképezésének bemutatására szolgál. Ez az átalakítási tábla két oszlopból áll:
- Feladó: A táblázatban keresni kívánt szöveges sztring.
- To: Az a szövegsztring, amely a From oszlopban lévő szövegsztringet helyettesíti.
Fontos
Fontos, hogy az átalakítási táblázat ugyanazokat az oszlopokat és oszlopneveket tartalmazza, mint az előző képen (ezeket "Feladó" és "Címzett" névvel kell elnevezni), ellenkező esetben a Power Query nem ismeri fel ezt a táblát átalakítási táblaként, és nem történik átalakítás.
A korábban létrehozott lekérdezés használatával kattintson duplán a Fürtözött értékek lépésre, majd a Fürtértékek párbeszédpanelen bontsa ki az Fuzzy fürtbeállításokat. Az Fuzzy cluster options területen engedélyezze a Hasonlósági pontszámok megjelenítése lehetőséget. Átalakítási tábla (nem kötelező) esetén válassza ki az átalakító táblát tartalmazó lekérdezést.
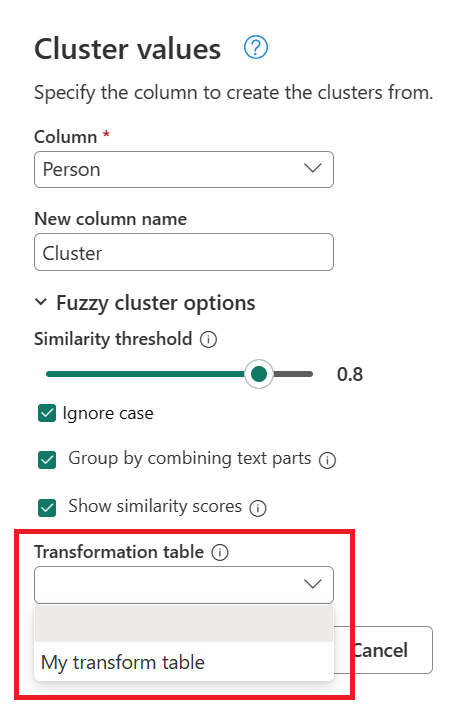
Miután kiválasztotta az átalakítási táblát, és engedélyezte a Hasonlósági pontszámok megjelenítése lehetőséget, válassza az OK gombot. A művelet eredménye egy olyan táblát biztosít, amely ugyanazt az ID és Személy oszlopot tartalmazza, mint az eredeti tábla, de két új, Cluster és Person_Cluster_Similarity nevű oszlopot is tartalmaz. A Fürt oszlop a nevek helyesen írt és nagybetűvel kezdődő verzióit tartalmazza, Miguel és Mike esetén Miguel, valamint Bill, Billy és William esetén William. A Person_Cluster_Similarity oszlop az egyes nevek hasonlósági pontszámait tartalmazza.
Képernyőkép a táblázatról, amely az új Cluster és Person_Cluster_Similarity oszlopokat tartalmazza.
Transzformációs tábla-parancsok
Észreveheti, hogy az előző szakaszban lévő átalakítási táblázat azt jelzi, hogy Mike példányai Miguelre változnak, a William-példányok pedig Billre változnak. Az eredményként kapott táblázatban azonban a Bill és a "billy" példányok williamre változtak. A transzformációs táblában nem közvetlen From - To útvonal található, hanem a táblázat szimmetrikus a klaszterezés során, ami azt jelenti, hogy a "mike" egyenértékű a "Miguel"-lel, és fordítva. Az átalakítási táblában megadott megfelelők eredménye a következő szabályoktól függ:
- Ha az azonos értékek többsége létezik, ezek az értékek elsőbbséget élveznek a nem dedentikus értékekkel szemben.
- Ha nincs több érték, az elsőként megjelenő érték elsőbbséget élvez.
Az ebben a cikkben használt eredeti táblázatban például a Miguel név elterjedt változatai (mind a kisbetűs "miguel", mind a nagybetűs Miguel) a Person oszlopban alkotják a Miguel és Mike nevek legtöbb példányát. Ezenkívül a Miguel név nagy kezdőbetűvel van írva, mivel ez a legjellemzőbb formája a névnek. Így Miguel és származékai, valamint Mike és származékai társítása az átalakító táblában azt eredményezi, hogy Miguel név szerepel a Fürt oszlopban.
A William, Bill és "billy" nevek esetében azonban az értékeknek nincs többsége, mivel mind a három egyedi. Mivel Vilmos az első, William a Fürt oszlopban van használatban. Ha a "billy" először megjelenik a táblázatban, akkor a "billy" a Fürt oszlopban lesz használva. Mivel az értékeknek nincs többsége, a rendszer az egyes nevek által használt esetet használja. Ez azt jelenti, hogy ha Vilmos az első, akkor a nagybetűs "W"-vel rendelkező Vilmos lesz a kimeneti érték; ha a "billy" az első, akkor a kisbetűs "b"-vel rendelkező "billy" lesz a kimeneti érték.