Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
A Power BI Dataflow Gen1 már örökölt állapotban van, és nem kap új funkcióberuházást. A Fabric-hozzáféréssel rendelkező prémium ügyfelek számára a Dataflow Gen2 az ajánlott elérési út, amely jobb teljesítményt, skálázást, megbízhatóságot, funkcionalitást és beépített AI-t kínál. A Pro/PPU-ügyfelek továbbra is használhatják a Gen1-et, mivel a Gen2 útmutatása ezekhez a forgatókönyvekhez folyamatosan fejlődik. A frissítési útmutatót az Adatfolyam Gen1-ről a Dataflow Gen2-re való frissítéssel kapcsolatban találhatja meg.
A dimenziómodell tervezése az adatfolyamokkal elvégezhető leggyakoribb feladatok egyike. Ez a cikk néhány ajánlott eljárást mutat be a dimenziómodell adatfolyamok használatával történő létrehozásához.
Adatfolyamok átmeneti előkészítése
Az adatintegrációs rendszerek egyik legfontosabb pontja a forrás operációs rendszerből származó olvasások számának csökkentése. A hagyományos adatintegrációs architektúrában ez a csökkentés egy új, átmeneti adatbázisnak nevezett adatbázis létrehozásával történik. Az átmeneti adatbázis célja, hogy az adatforrásból származó adatokat változtatás nélkül, rendszeresen betöltse abba.
A többi adatintegráció ezt követően az előkészítési adatbázist használja a további átalakítás forrásaként, és átalakítja azt a dimenziómodell-struktúrába.
Javasoljuk, hogy ugyanezt a megközelítést kövesse adatfolyamok használatával. Hozzon létre egy adatfolyam-készletet, amely felelős azért, hogy az adatokat változtatás nélkül betöltse a forrásrendszerből (és csak a szükséges táblákhoz). Az eredmény ezután az adatfolyam tárolási struktúrájában lesz tárolva (azure Data Lake Storage vagy Dataverse). Ez a módosítás biztosítja, hogy a forrásrendszerből származó olvasási művelet minimális legyen.
Ezután létrehozhat más adatfolyamokat is, amelyek az adatfolyamok átmeneti folyamatából származtatják az adatokat. Ennek a megközelítésnek az előnyei a következők:
- A forrásrendszerből származó olvasási műveletek számának csökkentése és a forrásrendszer terhelésének csökkentése.
- Az adatátjárók terhelésének csökkentése helyszíni adatforrás használata esetén.
- Az adatok köztes másolata egyeztetés céljából, ha a forrásrendszer adatai megváltoznak.
- Az átalakítási adatfolyamok forrásfüggetlensé tétele.
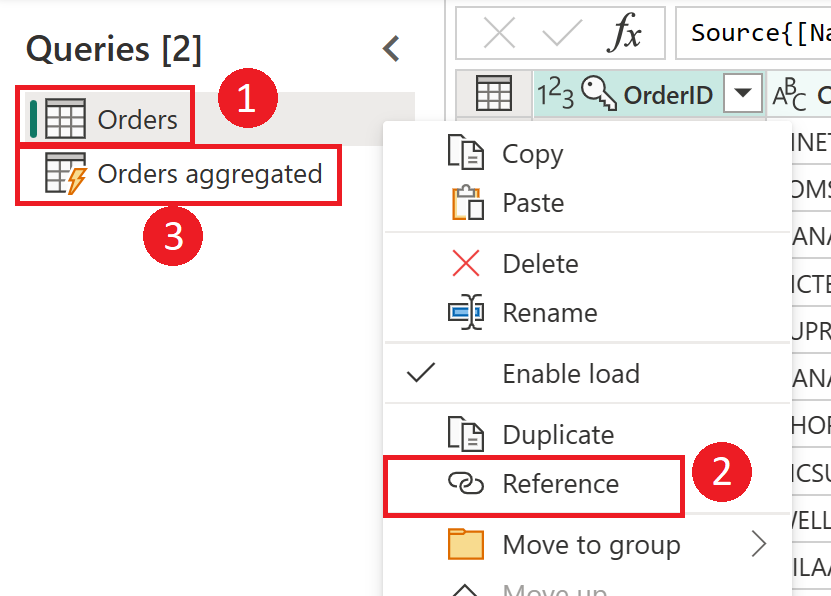
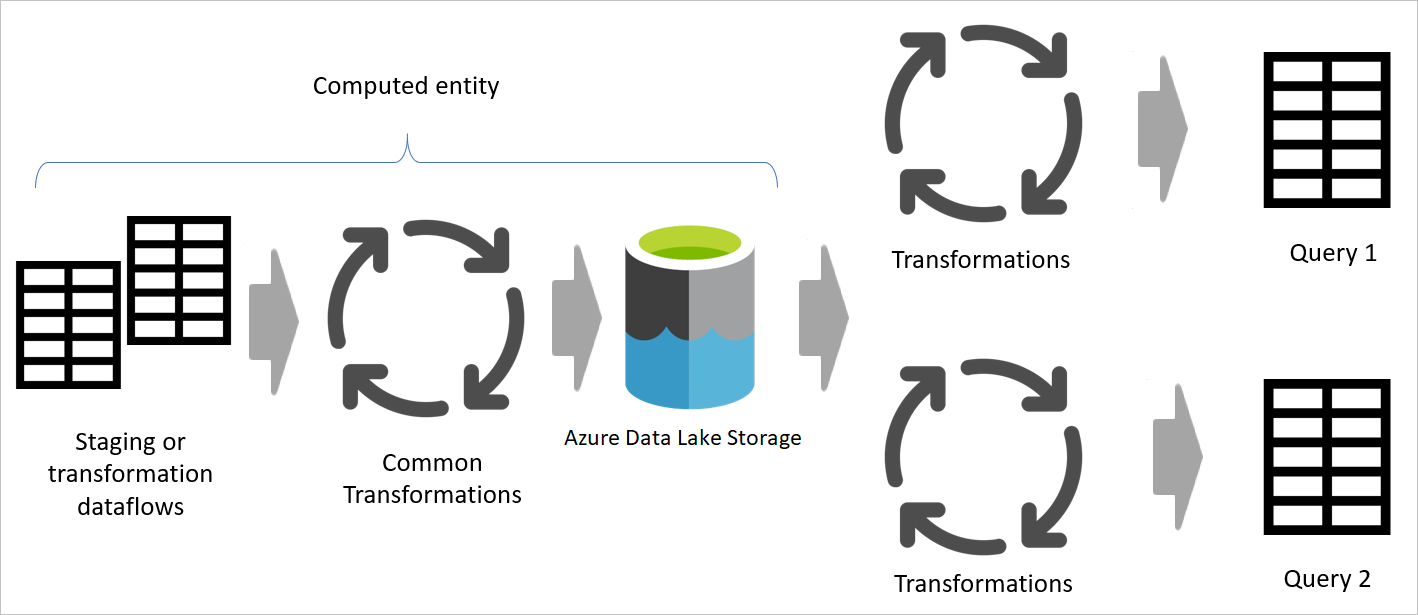
Az ábra bemutatja az adatfolyamok előkészítésének folyamatát.
Az átmeneti adatfolyamokat és az átmeneti tárolót bemutató diagram. Az ábra az átmeneti adatfolyam által az adatforrásból elért adatokat, valamint a Cadaversben vagy az Azure Data Lake Storage-ban tárolt táblákat mutatja. Ezután a táblák át lesznek alakítva más adatfolyamokkal együtt, amelyeket a rendszer lekérdezésekként küld ki.
Átalakítási adatfolyamok
Ha elkülöníti az átalakítási adatfolyamokat az átmeneti adatfolyamoktól, az átalakítás független a forrástól. Ez az elkülönítés segít, ha a forrásrendszert egy új rendszerre migrálja. Ebben az esetben mindössze annyit kell tennie, hogy módosítja az átmeneti adatfolyamokat. Az átalakítási adatfolyamok valószínűleg probléma nélkül működnek, mert csak az átmeneti adatfolyamokból származnak.
Ez az elkülönítés abban az esetben is segít, ha a forrásrendszer-kapcsolat lassú. Az átalakítási adatfolyamnak nem kell sokáig várnia, hogy a rekordok lassú kapcsolaton keresztül érkezhessenek a forrásrendszerből. Az átmeneti adatfolyam már elvégezte ezt a részt, és az adatok készen állnak az átalakítási rétegre.
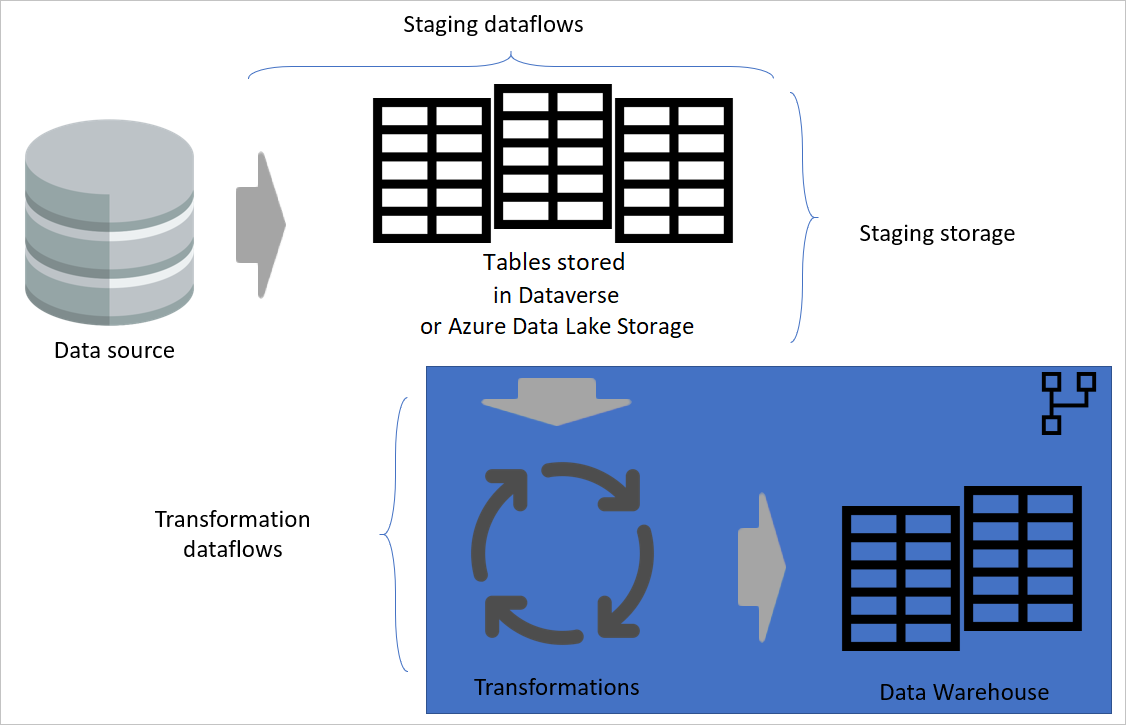
Rétegzett architektúra
A rétegzett architektúra olyan architektúra, amelyben külön rétegekben hajthat végre műveleteket. Az előkészítési és átalakítási adatfolyamok egy többrétegű adatfolyam-architektúra két rétegét is tartalmazhatják. A rétegekben végzett műveletek végrehajtása biztosítja a minimális karbantartást. Ha módosítani szeretne valamit, csak abban a rétegben kell módosítania, ahol az található. A többi rétegnek továbbra is jól kell működnie.
Az alábbi képen egy többrétegű architektúra látható az adatfolyamokhoz, amelyek tábláit ezután a Power BI szemantikai modelljeiben használják.
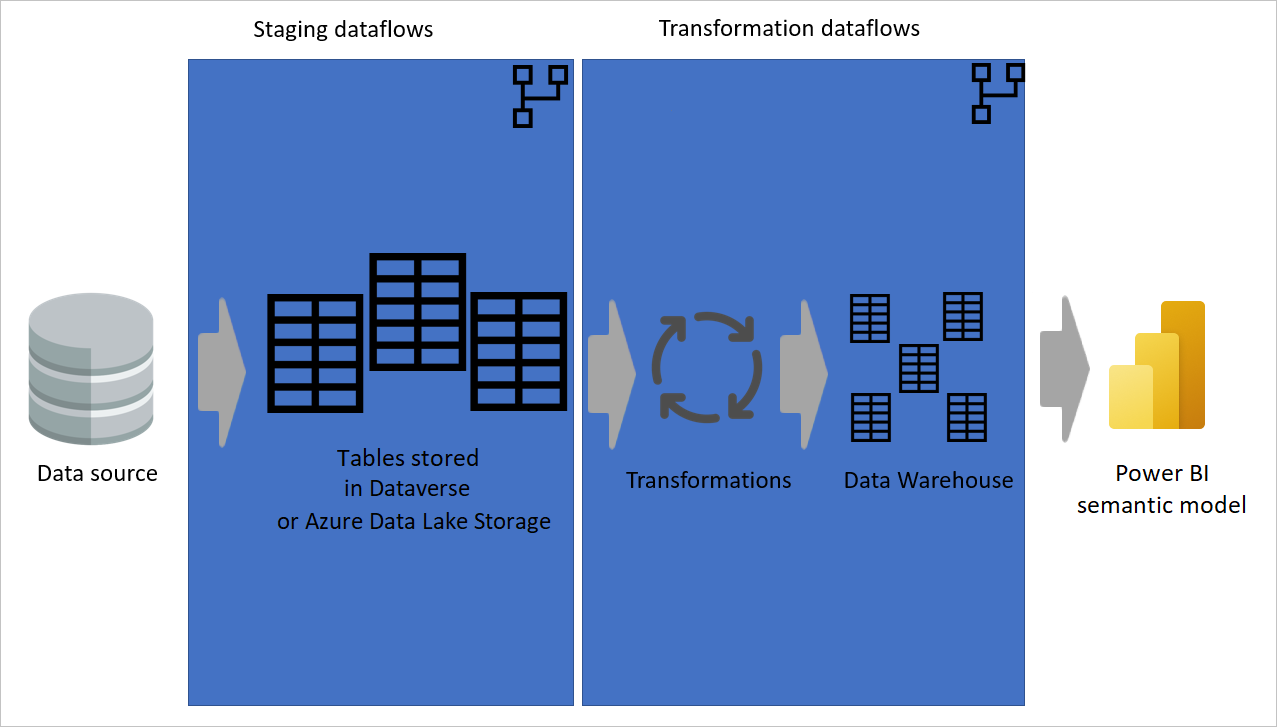
Számított tábla használata a lehető legnagyobb mértékben
Amikor egy adatfolyam eredményét egy másik adatfolyamban használja, a számított tábla fogalmát használja, ami azt jelenti, hogy adatokat kell lekérte egy "már feldolgozott és tárolt" táblából. Ugyanez történhet egy adatfolyamon belül is. Ha egy másik táblából származó táblára hivatkozik, használhatja a számított táblát. Ez a módszer akkor hasznos, ha több táblában kell elvégeznie az átalakításokat, amelyeket gyakori átalakításoknak nevezünk.
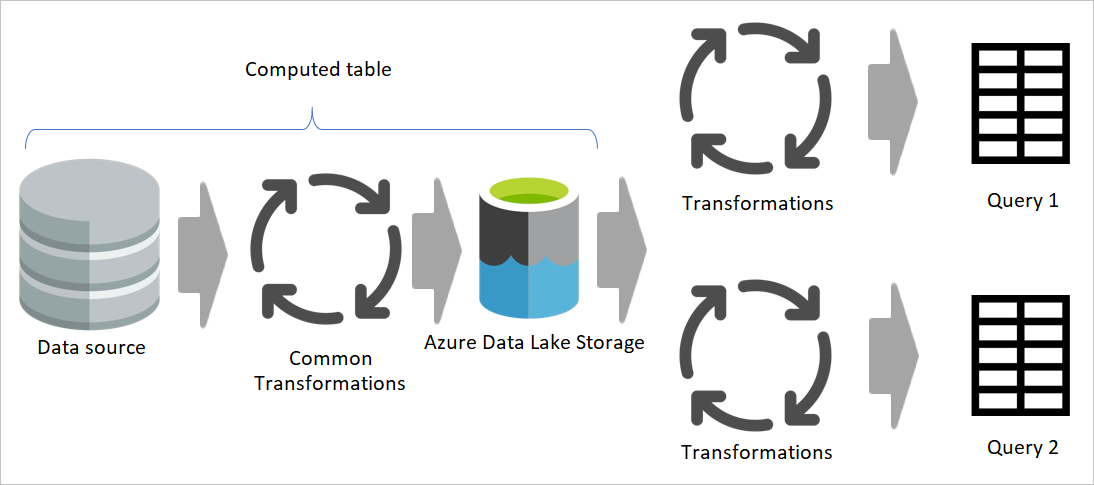
Az előző képen a számított tábla közvetlenül a forrásból szerzi be az adatokat. Az előkészítési és átalakítási adatfolyamok architektúrájában azonban valószínű, hogy a számított táblák az átmeneti adatfolyamokból származnak.
Csillagséma létrehozása
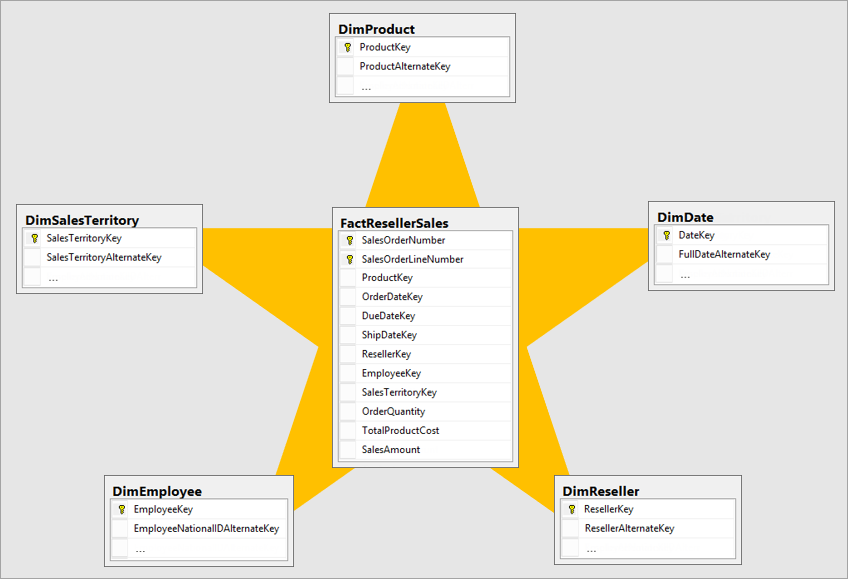
A legjobb dimenziómodell egy csillagsémamodell, amelynek dimenziói és ténytáblái úgy vannak kialakítva, hogy minimalizálják a modell adatainak lekérdezéséhez szükséges időt. A csillagséma-modell megkönnyíti az adatábrázoló megértését is.
Nem ideális, ha az operatív rendszer azonos elrendezésében lévő adatokat egy BI-rendszerbe viszi. Az adattáblákat újra kell átalakítani. Néhány táblának dimenziótábla formájában kell lennie, amely megőrzi a leíró információkat. Néhány táblának ténytábla formájában kell lennie, hogy megőrizze az összesíthető adatokat. A ténytáblák és dimenziótáblák legjobb elrendezése csillagséma. További információ: A csillagséma és a Power BI fontossága.
Egyedi kulcsérték használata dimenziókhoz
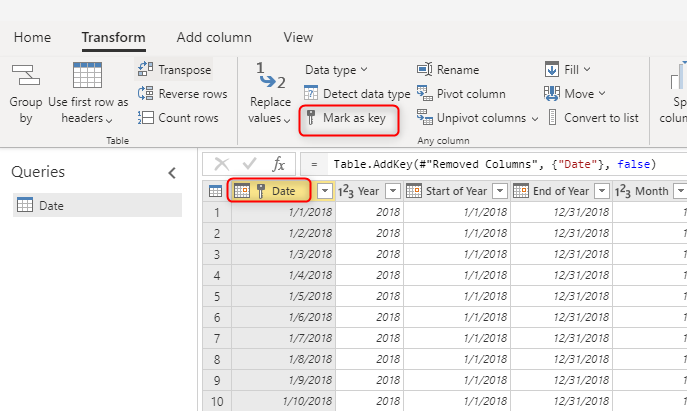
Dimenziótáblák készítésekor győződjön meg arról, hogy mindegyikhez van kulcs. Ez a kulcs biztosítja, hogy a dimenziók között ne legyenek több-többhöz (vagy más szóval "gyenge") kapcsolatok. A kulcsot úgy hozhatja létre, hogy valamilyen átalakítást alkalmaz annak érdekében, hogy egy oszlop vagy oszlopkombináció egyedi sorokat adjon vissza a dimenzióban. Ezután az oszlopok kombinációja megjelölhető kulcsként az adatfolyam táblájában.
Növekményes frissítés nagy ténytáblák esetén
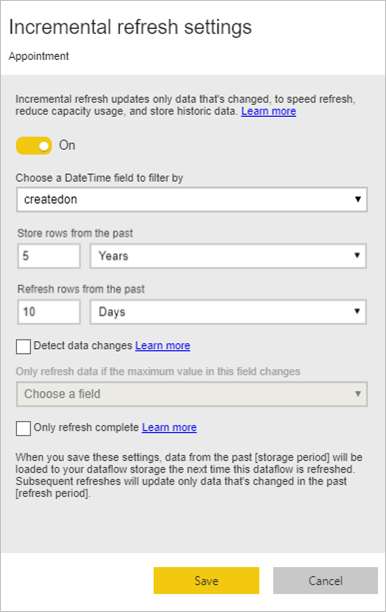
A ténytáblák mindig a dimenziómodell legnagyobb táblái. Javasoljuk, hogy csökkentse a táblákhoz átvitt sorok számát. Ha nagyon nagy ténytáblával rendelkezik, győződjön meg arról, hogy növekményes frissítést használ az adott táblához. Növekményes frissítés elvégezhető a Power BI szemantikai modellben és az adatfolyam-táblákban is.
Növekményes frissítés használatával csak az adatok egy részét, a módosított részt frissítheti. Több lehetőség közül választhatja ki, hogy az adatok mely része frissüljön, és melyik rész legyen megőrizve. További információ: Növekményes frissítés használata Power BI-adatfolyamokkal.
Hivatkozás dimenziók és ténytáblák létrehozására
A forrásrendszerben gyakran van egy tábla, amelyet tény- és dimenziótáblák létrehozására használ az adattárházban. Jó jelöltek számított táblának és köztes adatfolyamok számára ezek a táblák. A folyamat gyakori része – például az adattisztítás, valamint a további sorok és oszlopok eltávolítása – egyszer elvégezhető. A műveletek kimenetéből származó hivatkozással létrehozhatja a dimenzió- és ténytáblákat. Ez a módszer a számított táblát használja a gyakori átalakításokhoz.