Funkciókivonatolás
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- A gépi tanulási projekteknek a (klasszikus) ML Studióból a Azure Machine Learning való áthelyezésére vonatkozó információk.
- További információ a Azure Machine Learning.
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Szöveges adatok konvertálása egész számokkal kódolt funkciókká a Vowpal Wabbit kódtár használatával
Kategória: Text Analytics
Megjegyzés
Csak a következőre vonatkozik: Machine Learning Studio (klasszikus)
Hasonló húzási modulok érhetők el Azure Machine Learning tervezőben.
A modul áttekintése
Ez a cikk bemutatja, hogyan alakíthat át angol nyelvű szövegfolyamokat egész számokként ábrázolt funkciókká a Machine Learning Studio (klasszikus) Szolgáltatáskivonatoló moduljával. Ezután átadhatja ezt a kivonatolt funkciókészletet egy gépi tanulási algoritmusnak egy szövegelemzési modell betanítása érdekében.
Az ebben a modulban biztosított funkciókivonatolási funkció a Vowpal Wabbit keretrendszeren alapul. További információ: Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model.
További információ a funkciókivonatolásról
A funkciókivonatolás úgy működik, hogy az egyedi jogkivonatokat egész számokká alakítja. A bemenetként megadott pontos sztringeken működik, és nem végez nyelvi elemzést vagy előfeldolgozást.
Vegyük például az alábbihoz hasonló egyszerű mondatokat, amelyeket hangulatpontszám követ. Tegyük fel, hogy ezt a szöveget szeretné használni egy modell létrehozásához.
| USERTEXT (FELHASZNÁLÓI SZÖVEG) | HANGULAT |
|---|---|
| Imádtam ezt a könyvet | 3 |
| Utáltam ezt a könyvet | 1 |
| Ez a könyv nagyszerű volt | 3 |
| Szeretem a könyveket | 2 |
A Funkciókivonatoló modul belsőleg létrehoz egy n-grammból álló szótárt. Az adatkészlethez tartozó bigramok listája például a következőhöz hasonló:
| KIFEJEZÉS (bigram) | FREKVENCIA |
|---|---|
| Ez a könyv | 3 |
| Szerettem | 1 |
| Utáltam | 1 |
| Szeretem | 1 |
Az n-gramm méretét az N-gramm tulajdonság használatával szabályozhatja. Ha bigramokat választ, az unigramok is ki lesznek számítva. Így a szótár az alábbihoz hasonló kifejezéseket is tartalmaz:
| Kifejezés (unigram) | FREKVENCIA |
|---|---|
| Könyv | 3 |
| I | 3 |
| könyvek | 1 |
| Volt | 1 |
A szótár létrehozása után a Funkciókivonatoló modul kivonatértékekké alakítja a szótárkifejezéseket, és kiszámítja, hogy minden esetben használták-e a funkciót. A modul minden szöveges adatsorhoz egy oszlopkészletet ad ki, minden kivonatolt funkcióhoz egy-egy oszlopot.
A kivonatolás után például a funkcióoszlopok a következőképpen nézhetnek ki:
| Minősítés | Kivonatolási funkció 1 | Kivonatolási funkció 2 | Kivonatolási funkció 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Ha az oszlop értéke 0, a sor nem tartalmazza a kivonatolt funkciót.
- Ha az érték 1, akkor a sor tartalmazza a funkciót.
A funkciókivonatolás használatának előnye, hogy a változó hosszúságú szöveges dokumentumokat azonos hosszúságú numerikus jellemzővektorokként ábrázolhatja, és dimenziócsökkentést érhet el. Ezzel szemben, ha a szövegoszlopot a betanításhoz szeretné használni, akkor a rendszer kategorikus jellemzőoszlopként kezeli, amely sok-sok különböző értékkel rendelkezik.
Ha a kimenetek numerikusak, számos különböző gépi tanulási módszert is használhat az adatokkal, beleértve a besorolást, a fürtözést vagy az információlekérést. Mivel a keresési műveletek sztring-összehasonlítás helyett egész számkivonatokat használhatnak, a jellemzők súlyozása is sokkal gyorsabb.
Szolgáltatáskivonatolás konfigurálása
Adja hozzá a Funkciókivonatoló modult a kísérlethez a (klasszikus) Studióban.
Csatlakozás az elemezni kívánt szöveget tartalmazó adatkészletet.
Tipp
Mivel a szolgáltatáskivonatolás nem végez lexikális műveleteket, például a lefuttatást vagy a csonkolást, néha jobb eredményeket érhet el, ha a funkciók kivonatolása előtt szöveg-előfeldolgozást végez. Javaslatokért tekintse meg az ajánlott eljárásokat és a műszaki megjegyzéseket .
Céloszlopok esetén jelölje ki azokat a szöveges oszlopokat, amelyeket kivonatolt funkciókká szeretne alakítani.
Az oszlopoknak sztring adattípusúnak kell lenniük, és funkcióoszlopként kell megjelölni.
Ha több szövegoszlopot választ bemenetként, az nagy hatással lehet a jellemzők dimenziójára. Ha például egy 10 bites kivonatot használ egyetlen szöveges oszlophoz, a kimenet 1024 oszlopot tartalmaz. Ha két szöveges oszlophoz 10 bites kivonatot használ, a kimenet 2048 oszlopot tartalmaz.
Megjegyzés
Alapértelmezés szerint a Studio (klasszikus) funkcióként jelöli meg a legtöbb szöveges oszlopot, így ha az összes szövegoszlopot kijelöli, előfordulhat, hogy túl sok oszlopot kap, köztük sok olyan oszlopot, amely valójában nem szabad szöveg. A Metaadatok szerkesztésefunkció Törlés funkciójával megakadályozhatja, hogy más szöveges oszlopok kivonatolódjanak.
A kivonatoló bitméret használatával adja meg a kivonattábla létrehozásakor használandó bitek számát.
Az alapértelmezett bitméret 10. Sok probléma esetén ez az érték több mint megfelelő, de hogy az adatokhoz elegendő-e, a betanítási szövegben található n-gramm szókincs méretétől függ. Nagy szókincs esetén több helyre lehet szükség az ütközések elkerülése érdekében.
Javasoljuk, hogy ehhez a paraméterhez különböző számú bitet használjon, és értékelje ki a gépi tanulási megoldás teljesítményét.
N-gramm esetén írjon be egy számot, amely meghatározza a betanítási szótárhoz hozzáadandó n-gramm maximális hosszát. Az n-gram egy n szósorozat, amelyet egyedi egységként kezelnek.
N-gramm = 1: Egygramm vagy egyetlen szó.
N-gramm = 2: Bigramok vagy kétszavas szekvenciák, plusz unigramok.
N-gramm = 3: Trigramok vagy háromszavas szekvenciák, valamint bigramok és unigramok.
Futtassa a kísérletet.
Results (Eredmények)
A feldolgozás befejezése után a modul egy átalakított adatkészletet ad ki, amelyben az eredeti szövegoszlop több oszlopra lett konvertálva, amelyek mindegyike a szöveg egy funkcióját képviseli. A szótár nagyságától függően az eredményül kapott adathalmaz rendkívül nagy lehet:
| Oszlopnév 1 | 2. oszloptípus |
|---|---|
| USERTEXT (FELHASZNÁLÓI SZÖVEG) | Eredeti adatoszlop |
| HANGULAT | Eredeti adatoszlop |
| USERTEXT – Kivonatolási funkció 1 | Kivonatolt szolgáltatás oszlopa |
| USERTEXT – Kivonatolási funkció 2 | Kivonatolt szolgáltatás oszlopa |
| USERTEXT – Kivonatolási funkció n | Kivonatolt szolgáltatás oszlopa |
| USERTEXT – Kivonatolási funkció 1024 | Kivonatolt szolgáltatás oszlopa |
Miután létrehozta az átalakított adatkészletet, használhatja a Modell betanítása modul bemeneteként egy jó besorolási modellel, például kétosztályos támogatóvektor-géppel.
Ajánlott eljárások
A szöveges adatok modellezése során használható ajánlott eljárásokat az alábbi, egy kísérletet ábrázoló diagram szemlélteti
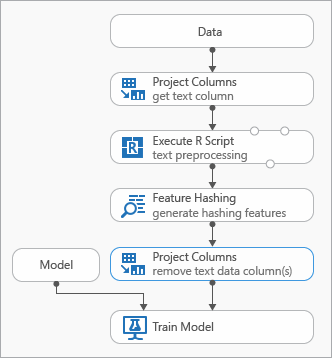
Előfordulhat, hogy a bemeneti szöveg előfeldolgozásához hozzá kell adnia egy R-szkript végrehajtása modult a funkciókivonatolás használata előtt. Az R-szkriptekkel rugalmasan használhat egyéni vokabulátorokat vagy egyéni átalakításokat is.
A szöveges oszlopoknak a kimeneti adatkészletből való eltávolításához a Funkciókivonatoló modul után hozzá kell adnia az Adathalmaz oszlopainak kijelölése modult. A kivonatolási funkciók létrehozása után nincs szükség a szöveges oszlopokra.
Másik lehetőségként a Metaadatok szerkesztése modullal törölheti a funkcióattribútumot a szövegoszlopból.
Érdemes lehet ezeket a szövegelőfeldolgozási beállításokat használni az eredmények egyszerűsítése és a pontosság növelése érdekében:
- szótörés
- szóeltávolítás leállítása
- case normalization
- írásjelek és speciális karakterek eltávolítása
- szárító.
Az egyes megoldásokban alkalmazható előfeldolgozási módszerek optimális készlete a tartománytól, a szókincstől és az üzleti igénytől függ. Javasoljuk, hogy kísérletezzen az adataival, hogy lássa, melyik egyéni szövegfeldolgozási módszer a leghatékonyabb.
Példák
A funkciókivonatolás szövegelemzéshez való használatáról az Azure AI-katalógusban talál példákat:
Hírek kategorizálása: Funkciókivonatolással a cikkeket előre meghatározott kategóriákba sorolja.
Hasonló vállalatok: A Wikipédia-cikkek szövegét használva kategorizálja a vállalatokat.
Szövegbesorolás: Ez az ötrészes minta a Twitter-üzenetek szövegét használja hangulatelemzéshez.
Műszaki megjegyzések
Ez a szakasz implementálási részleteket, tippeket és válaszokat tartalmaz a gyakori kérdésekre.
Tipp
A szolgáltatások kivonatolása mellett más módszerekkel is kinyerhet funkciókat a szövegből. Például:
- A Szöveg előfeldolgozása modullal eltávolíthatja az összetevőket, például a helyesírási hibákat, vagy egyszerűsítheti a szöveg kivonatolásra való előkészítését.
- A kulcskifejezések kinyerése természetes nyelvi feldolgozást használ a kifejezések kinyeréséhez.
- A Nevesített entitások felismerése funkcióval azonosíthatja a fontos entitásokat.
Machine Learning Studio (klasszikus) egy szövegbesorolási sablont biztosít, amely végigvezeti Önt a Funkciókivonatoló modulon a funkciók kinyerésére.
Megvalósítás részletei
A Funkciókivonatolás modul egy Vowpal Wabbit nevű gyors gépi tanulási keretrendszert használ, amely a jellemzők szavait kivonatolja a memóriabeli indexekbe egy népszerű nyílt forráskód murmurhash3 nevű kivonatoló függvénnyel. Ez a kivonatoló függvény egy nem kriptográfiai kivonatoló algoritmus, amely a szöveges bemeneteket egész számokra képezi le, és népszerű, mivel jól teljesít a kulcsok véletlenszerű eloszlásában. A kriptográfiai kivonatoló függvényekkel ellentétben a támadók könnyen megfordíthatják, így nem alkalmasak titkosítási célokra.
A kivonatolás célja, hogy a változó hosszúságú szöveges dokumentumokat egyenlő hosszúságú numerikus jellemzővektorokká alakítsa, hogy támogassa a dimenziócsökkentést, és felgyorsítsa a jellemzők súlyainak keresését.
Minden kivonatolási funkció egy vagy több n-gram szöveges jellemzőt jelöl (unigram vagy egyéni szó, két gramm, három gramm stb.), a bitek számától (k-ként jelölve) és a paraméterként megadott n-gramm számától függően. A murmurhash v3 (csak 32 bites) algoritmussal a gépi architektúra alá nem írt szavakra projekteli a szolgáltatások nevét, amely ezután (2^k)-1-gyel van ÉS-el elosztva. Ez azt jelenti, hogy a kivonatolt érték az első k alsóbbrendű bitre lesz vetítve, a többi bit pedig nullázva lesz. Ha a megadott számú bit 14, a kivonattábla 214-1 (vagy 16 383) bejegyzést tartalmazhat.
Sok probléma esetén az alapértelmezett kivonattábla (bitméret = 10) több, mint megfelelő; azonban az n-gramm szókincs méretétől függően a betanítási szövegben több helyre lehet szükség az ütközések elkerülése érdekében. Javasoljuk, hogy próbáljon meg eltérő számú bitet használni a kivonatoló bitméret paraméterhez, és értékelje ki a gépi tanulási megoldás teljesítményét.
Várt bemenetek
| Név | Típus | Description |
|---|---|---|
| Adathalmaz | Adattábla | Bemeneti adatkészlet |
Modulparaméterek
| Name | Tartomány | Típus | Alapértelmezett | Description |
|---|---|---|---|---|
| Céloszlopok | Bármelyik | ColumnSelection | StringFeature | Válassza ki azokat az oszlopokat, amelyekre a kivonatolást alkalmazni szeretné. |
| Kivonatoló bitméret | [1;31] | Egész szám | 10 | Írja be a kijelölt oszlopok kivonatolásához használandó bitek számát |
| N-gramm | [0;10] | Egész szám | 2 | Adja meg a kivonatolás során létrehozott N-grammok számát. Alapértelmezés szerint az unigramok és a bigramok is kinyerhetők |
Kimenetek
| Név | Típus | Description |
|---|---|---|
| Átalakított adatkészlet | Adattábla | Kimeneti adatkészlet kivonatolt oszlopokkal |
Kivételek
| Kivétel | Description |
|---|---|
| 0001-s hiba | Kivétel akkor fordul elő, ha egy vagy több megadott adathalmaz-oszlop nem található. |
| 0003-os hiba | Kivétel akkor fordul elő, ha egy vagy több bemenet null értékű vagy üres. |
| 0004-s hiba | Kivétel akkor fordul elő, ha a paraméter kisebb vagy egyenlő egy adott értékkel. |
| 0017-s hiba | Kivétel akkor fordul elő, ha egy vagy több megadott oszlop típusa nem támogatott az aktuális modulban. |
A Studio (klasszikus) modulokkal kapcsolatos hibák listáját Machine Learning hibakódok között találja.
Az API-kivételek listájáért lásd Machine Learning REST API hibakódjait.