Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA-adatelemzés | Ügyfélbiztonság és megbízhatóság |
| Microsoft | Microsoft |
absztrakt – A biztonsági hibajelentések (SBR-k) azonosítása a szoftverfejlesztési életciklus létfontosságú lépése. A felügyelt gépi tanuláson alapuló megközelítésekben általában azt feltételezzük, hogy a teljes hibajelentések elérhetők a betanításhoz, és hogy címkéik zajmentesek. Legjobb tudásunk szerint ez az első tanulmány, amely azt mutatja, hogy a pontos címke-előrejelzés az SBR-ek számára akkor is lehetséges, ha csak a cím áll rendelkezésre, és a címkezaj jelenlétében.
indexfeltételek – Machine Learning, Helytelen címkézés, Zaj, Biztonsági hibajelentés, Hibatárak
Én. BEVEZETÉS
A jelentett hibák közötti biztonsági problémák azonosítása sürgető igény a szoftverfejlesztői csapatok körében, mivel az ilyen problémák gyorsabb javításokat igényelnek a megfelelőségi követelmények teljesítése és a szoftver- és ügyféladatok integritásának biztosítása érdekében.
A gépi tanulás és a mesterségesintelligencia-eszközök azt ígérik, hogy a szoftverfejlesztést gyorsabbá, rugalmasabbá és helyesebbé teszik. Számos kutató alkalmazta a gépi tanulást a biztonsági hibák azonosításának problémájára [2], [7], [8], [18]. A korábbi közzétett tanulmányok feltételezték, hogy a teljes hibajelentés elérhető egy gépi tanulási modell betanításához és pontozásához. Nem feltétlenül ez a helyzet. Vannak olyan helyzetek, amikor a teljes hibajelentés nem érhető el. A hibajelentés tartalmazhat például jelszavakat, személyazonosításra alkalmas adatokat (PII) vagy más bizalmas adatokat – ez a Microsoftnál jelenleg tapasztalható eset. Ezért fontos megállapítani, hogy a biztonsági hibák azonosítása mennyire végezhető el kevesebb információval, például ha csak a hibajelentés címe érhető el.
Emellett a hibatárak gyakran tartalmaznak tévesen címkézett bejegyzéseket [7]: a nem biztonsági hibajelentések biztonsági szempontból kapcsolódóként vannak besorolva, és fordítva. A helytelen címkézésnek számos oka lehet, a fejlesztési csapat biztonsági szakértelmének hiányától kezdve bizonyos problémák homályosságáig, például lehetséges, hogy a nem biztonsági hibákat közvetett módon használják ki, ami biztonsági következményekkel jár. Ez komoly probléma, mivel az SBR-k helytelen címkézése azt eredményezi, hogy a biztonsági szakértőknek költséges és időigényes munkával manuálisan kell áttekinteniük a hibaadatbázist. Annak megértése, hogy a zaj milyen hatással van a különböző osztályozókra, és hogy a különböző gépi tanulási technikák mennyire robusztusak (vagy törékenyek) a különböző zajokkal szennyezett adathalmazok jelenlétében, olyan probléma, amelyet meg kell oldani az automatikus besoroláshoz a szoftverfejlesztés gyakorlatához.
Az előzetes munka azt állítja, hogy a hibatárak belsőleg zajosak, és hogy a zaj káros hatással lehet a gépi tanulási osztályozók teljesítményére [7]. A biztonsági hibajelentések (SB-k) azonosításának problémájára azonban nem létezik szisztematikus és mennyiségi vizsgálat arra vonatkozóan, hogy a különböző zajszintek és zajtípusok hogyan befolyásolják a különböző felügyelt gépi tanulási algoritmusok teljesítményét.
Ebben a tanulmányban bemutatjuk, hogy a hibajelentések besorolása akkor is elvégezhető, ha kizárólag a cím áll rendelkezésre a képzéshez és a pontozáshoz. A legjobb tudomásunk szerint ez az első olyan tanulmány, amely ezt megteszi. Emellett biztosítjuk a zaj hatásának első szisztematikus vizsgálatát a hibajelentések besorolásában. Összehasonlító tanulmányt készítünk három gépi tanulási technika (logisztikai regresszió, naiv Bayes és AdaBoost) robusztusságáról az osztályfüggetlen zaj ellen.
Bár vannak olyan elemzési modellek, amelyek rögzítik a zaj általános hatását néhány egyszerű osztályozó esetében [5], [6], ezek az eredmények nem biztosítanak szoros határokat a zajnak a pontosságra gyakorolt hatására, és csak egy adott gépi tanulási technikára érvényesek. A zaj hatásának pontos elemzése a gépi tanulási modellekben általában számítási kísérletek futtatásával történik. Ezek az elemzések számos forgatókönyv esetében történtek, a szoftveres mérési adatoktól [4], a műholdas képbesorolásig [13] és az orvosi adatokig [12]. Ezek az eredmények azonban nem fordíthatók le a konkrét problémánkra, mivel nagy mértékben függ az adathalmazok természetétől és az alapul szolgáló besorolási problémától. Legjobb tudásunk szerint nincsenek közzétett eredmények a zajos adathalmazok biztonsági hibajelentések besorolására gyakorolt hatásának problémájára vonatkozóan.
KUTATÁSI HOZZÁJÁRULÁSAINK:
Osztályozókat tanítunk be a biztonsági hibajelentések (SBR-k) azonosítására kizárólag a jelentések címe alapján. A legjobb tudomásunk szerint ez az első ilyen munka. Az előző munkák vagy a teljes hibajelentést használták, vagy továbbfejlesztettük a hibajelentést további kiegészítő funkciókkal. A hibák kizárólag a csempén alapuló besorolása különösen fontos, ha a teljes hibajelentések adatvédelmi megfontolások miatt nem érhetők el. Hírhedt például a jelszavakat és más bizalmas adatokat tartalmazó hibajelentések esete.
Az SBR-k automatikus besorolásához használt különböző gépi tanulási modellek és technikák zajtűrésének első szisztematikus vizsgálatát is biztosítjuk. Összehasonlító tanulmányt készítünk három különböző gépi tanulási technika robusztusságáról (logisztikai regresszió, naiv Bayes és AdaBoost) az osztályfüggő és osztályfüggetlen zajokkal szemben.
A papír fennmaradó része a következőképpen jelenik meg: A II. szakaszban bemutatunk néhány korábbi művet a szakirodalomban. A III. szakaszban ismertetjük az adatkészletet és az adatok előzetes feldolgozásának módját. A módszertant a IV. szakasz ismerteti, és az V. szakaszban elemzett kísérleteink eredményeit. Végül a következtetéseket és a jövőbeli munkákat a VI.
II. KORÁBBI MUNKÁK
GÉPI TANULÁSI ALKALMAZÁSOK HIBATÁRAKBA.
Széles körű szakirodalom áll rendelkezésre a szövegbányászat, a természetes nyelvfeldolgozás és a gépi tanulás hibatárakon való alkalmazásáról, például a biztonsági hibaészlelés [2], [7], [8], [18], hibák ismétlődésének azonosítása [3], hibaosztályozás [1], [11], néhány alkalmazást megemlítve. Ideális esetben a gépi tanulás (ML) és a természetes nyelvi feldolgozás házassága potenciálisan csökkenti a hibaadatbázisok kurálásához szükséges manuális munkát, lerövidíti ezeknek a feladatoknak a elvégzéséhez szükséges időt, és növelheti az eredmények megbízhatóságát.
[7] A szerzők egy természetes nyelvi modellt javasolnak az SBR-k besorolásának automatizálásához a hiba leírása alapján. A szerzők kinyernek egy szókincset a betanítási adatkészlet összes hibaleírásából, és manuálisan három szólistává alakítják: a releváns szavakat, a stop szavakat (a besorolás szempontjából irrelevánsnak tűnő gyakori szavakat) és a szinonimákat. Összehasonlítják a biztonsági mérnökök által kiértékelt adatokon betanított biztonsági hibaosztályozó teljesítményét egy olyan osztályozóval, amely az általános hibabejelentők által címkézett adatokra van betanítva. Bár a modell egyértelműen hatékonyabb, ha biztonsági mérnökök által ellenőrzött adatokon tanítják be, a javasolt modell egy manuálisan kialakított szókincsen alapul, amely az emberi gondozástól teszi függővé. Ezenkívül nincs elemzés arról, hogy a különböző zajszintek hogyan befolyásolják a modelljüket, hogyan reagálnak a különböző osztályozók a zajra, és hogy a zaj mindkét osztályban eltérően befolyásolja-e a teljesítményt.
Zou et. az al [18] a hibajelentésekben található számos olyan információtípust használ, amely magában foglalja a hibajelentés nem szöveges mezőit (metafunkciók, például idő, súlyosság és prioritás), valamint a hibajelentés szöveges tartalmát (szöveges funkciók, azaz az összefoglaló mezők szövegét). Ezen funkciók alapján létrehoznak egy modellt, amely automatikusan azonosítja az SBR-eket természetes nyelvi feldolgozással és gépi tanulási technikákkal. [8] A szerzők hasonló elemzést végeznek, de emellett összehasonlítják a felügyelt és nem felügyelt gépi tanulási technikák teljesítményét, és megvizsgálják, hogy mennyi adatra van szükség a modelljeik betanítása érdekében.
[2] A szerzők különböző gépi tanulási technikákat is felfedeznek, amelyek a leírásuk alapján SBR-ként vagy NSBR-ként (nem biztonsági hibajelentés) sorolják be a hibákat. A TFIDF-en alapuló adatfeldolgozási és modellbetanítási folyamatot javasolnak. Összehasonlítják a javasolt csővezetéket egy bag-of-words és naiv Bayes-alapú modellel. Wijayasekara et al. [16] szövegbányászati technikákat is alkalmaztak annak érdekében, hogy az egyes hibajelentések jellemzővektorát létrehozzák a gyakori szavak alapján, a rejtett hatású hibák (HIB-k) azonosítására. Yang et al. [17] azt állította, hogy kifejezésfrekvencia (TF) és Naiv Bayes segítségével azonosítanak magas hatású hibajelentéseket (pl. SBR-eket). [9] A szerzők egy modellt javasolnak a hiba súlyosságának előrejelzéséhez.
CÍMKEZAJ
A címkezajú adathalmazok kezelésének problémáját széles körben tanulmányozták. Frenay és Verleysen javaslatot tesznek a zaj osztályozására [6] a zajos címke különböző típusainak megkülönböztetése érdekében. A szerzők három különböző zajtípust javasolnak: a címkezajt, amely a valódi osztálytól és a példány jellemzőitől függetlenül történik; olyan címkezaj, amely csak a valódi címkétől függ; és címkéznek zajt, ahol a téves jelölés valószínűsége a funkcióértéktől is függ. Munkánk során az első két zajtípust tanulmányozzuk. Elméleti szempontból a címkezaj általában csökkenti a modell teljesítményét [10], néhány konkrét eset kivételével [14]. Általánosságban elmondható, hogy a robusztus módszerek a címkezaj kezeléséhez a túlillesztés elkerülésére támaszkodnak [15]. A besorolás zajhatásainak tanulmányozása korábban számos területen történt, például a műholdas képek besorolása [13], a szoftverminőségi besorolás [4] és az orvosi tartományok besorolása [12]. Legjobb tudásunk szerint nincsenek olyan közzétett művek, amelyek a zajos címkék hatásainak pontos számszerűsítését tanulmányozták az SBR-besorolás problémájában. Ebben a forgatókönyvben a zajszintek, a zajtípusok és a teljesítménycsökkenés pontos összefüggése nem került megállapításra. Ezenkívül érdemes megérteni, hogy a különböző osztályozók hogyan viselkednek a zaj jelenlétében. Általánosabban nem tudunk olyan munkáról, amely szisztematikusan vizsgálja a zajos adathalmazok hatását a különböző gépi tanulási algoritmusok teljesítményére a szoftveres hibajelentések kontextusában.
III. ADATKÉSZLET LEÍRÁSA
Adatkészletünk 1 073 149 hibacímből áll, amelyek közül 552 073 SBR-nek, 521 076 pedig NSBR-nek felel meg. Az adatok a Microsoft különböző csapataitól 2015, 2016, 2017 és 2018 évben gyűltek össze. Az összes címkét aláírásalapú hibaellenőrzési rendszerek vagy emberi címkével rendelkezők szerezték be. Az adatkészletünkben található hibacímek nagyon rövid szövegek, amelyek körülbelül 10 szót tartalmaznak, és áttekintik a problémát.
Egy. Adatok előfeldolgozása Minden hibacímet szóközök mentén bontunk fel, így kifejezések listája jön létre. A tokenek listáját az alábbiak szerint dolgozzuk fel:
Az összes fájlelérési út eltávolítása
Elemek felosztása, ahol a következő szimbólumok találhatók: { , (, ), -, [, ] }
Távolítsa el a stop szavakat, a számszerű karakterekből álló tokeneket, valamint azokat a tokeneket, amelyek a teljes korpuszban kevesebb mint 5 alkalommal fordulnak elő.
IV. MÓDSZERTAN
A gépi tanulási modellek betanításának folyamata két fő lépésből áll: az adatok funkcióvektorokba való kódolásából és a felügyelt gépi tanulási osztályozók betanításából.
Egy. Funkcióvektorok és gépi tanulási technikák
Az első rész magában foglalja az adatok funkcióvektorokba való kódolását a frequencyinverse document frequency algoritmus (TF-IDF) használatával a [2] alkalmazásban használt módon. TF-IDF egy olyan információlekérési technika, amely egy kifejezés gyakoriságát (TF) és inverz dokumentum gyakoriságát (IDF) méri. Minden szónak vagy kifejezésnek megvan a megfelelő TF- és IDF-pontszáma. A TF-IDF algoritmus a dokumentumban megjelenő hányszoros szám alapján rendeli hozzá a szót a fontossághoz, és ami még fontosabb, ellenőrzi, hogy a kulcsszó mennyire releváns az adathalmaz címgyűjteményében. Három besorolási technikát képeztünk ki és hasonlítottunk össze: naiv Bayes (NB), kiemelt döntési fákat (AdaBoost) és logisztikai regressziót (LR). Azért választottuk ezeket a technikákat, mert a szakirodalom azt mutatja, hogy a teljes jelentés alapján jól teljesítenek a biztonsági hibajelentések azonosításának kapcsolódó feladatában. Ezeket az eredményeket megerősítették egy előzetes elemzésben, amelyben ez a három osztályozó felülmúlta a támogató vektorgépeket és a véletlenszerű erdőket. Kísérleteink során a scikit-learn kódtárat használjuk a kódoláshoz és a modell betanításához.
B. Zajtípusok
Az ebben a munkában vizsgált zaj a betanítási adatok osztálycímkéjében lévő zajra utal. Ilyen zaj jelenlétében ennek következtében a tanulási folyamat és az eredményül kapott modell hibásan meghatározott példákkal rontható. Elemezzük az osztályinformációkra alkalmazott különböző zajszintek hatását. A címkezajok típusait a szakirodalom korábban különböző terminológiák használatával tárgyalta. Munkánk során két különböző címkezaj hatásait elemezzük osztályozóinkban: osztályfüggetlen címkezajt, amelyet a példányok véletlenszerű kiválasztásával és a címke megfordításával vezetünk be; és osztályfüggő zaj, ahol az osztályok eltérő valószínűséggel zajosak.
a) osztályfüggetlen zaj: Az osztályfüggetlen zaj a példányok valódi osztályától függetlenül fellépő zajra utal. Ilyen típusú zaj esetén a pbr hibacímkéjének valószínűsége megegyezik az adathalmaz összes példányára vonatkozóan. Az adathalmazokban osztályfüggetlen zajt vezetünk be úgy, hogy minden címkét véletlenszerűen megfordítunk pbrvalószínűséggel.
b) osztályfüggő zaj: Az osztályfüggő zaj a példányok valódi osztályától függő zajra utal. Ebben a zajtípusban az SBR osztályban a helytelen címkézés valószínűsége psbr, és az NSBR osztályban a helytelen címkézés valószínűsége pnsbr. Osztályfüggő zajt vezetünk be az adatkészletünkbe azáltal, hogy az adatkészlet minden egyes bejegyzésének SBR valódi címkéjét p valószínűséggel felcseréljüksbr. Hasonlóan, az NSBR-példányok osztálycímkéjét p valószínűséggel megfordítjuknsbr.
c) egyosztályos zaj: Az egyosztályos zaj az osztályfüggő zaj speciális esete, ahol pnsbr = 0 és psbr> 0. Vegye figyelembe, hogy osztályfüggetlen zaj esetén psbr = pnsbr = pbr.
C. Zajgenerálás
Kísérleteink a különböző zajtípusok és szintek hatását vizsgálják az SBR-osztályozók betanításában. Kísérleteink során az adatkészletet úgy állítjuk be, hogy 25% tesztadatként, 10% validációra, és 65% betanítási adatként szerepeljen.
Zajt adunk a betanítási és ellenőrzési adatkészletekhez a pbr, a psbr és a pnsbr különböző szintjeihez. A tesztadatkészletet nem módosítjuk. A különböző zajszintek a P = {0,05 × i|0 < i < 10}.
Az osztályfüggetlen zajkísérletekben a pbr ∈ P esetében a következőket tesszük:
Zaj létrehozása betanítási és validálási adatkészletekhez;
Logisztikai regressziós, naiv Bayes- és AdaBoost-modellek betanítása betanítási adatkészlettel (zajjal); * Modellek finomhangolása érvényesítési adatkészlettel (zajjal);
Tesztelje a modelleket tesztadatkészlettel (zajmentes).
Az osztályfüggő zajkísérletekben psbr ∈ P és pnsbr ∈ P esetében a psbr és a pnsbrösszes kombinációjára a következőket tesszük:
Zaj létrehozása betanítási és validálási adatkészletekhez;
Logisztikus regresszió, naiv Bayes és AdaBoost modellek betanítása tanító adatkészlettel (zajjal);
A modellek finomhangolása érvényesítési adatkészlettel (amely zajt tartalmaz);
Tesztelje a modelleket tesztadatkészlettel (zajmentes).
V. KÍSÉRLETI EREDMÉNYEK
Ebben a szakaszban a IV. szakaszban leírt módszertan szerint végzett kísérletek eredményeit elemzik.
a) A modell teljesítménye zaj nélkül a betanítási adathalmazban: A tanulmány egyik hozzájárulása egy gépi tanulási modell javaslata, amely a biztonsági hibákat csak a hiba címének használatával azonosítja a döntéshozatalhoz. Ez akkor is lehetővé teszi a gépi tanulási modellek betanítását, ha a fejlesztői csapatok bizalmas adatok jelenléte miatt nem szeretnének teljes körűen megosztani hibajelentéseket. Három gépi tanulási modell teljesítményét hasonlítjuk össze, ha csak hibacímekkel tanítják be.
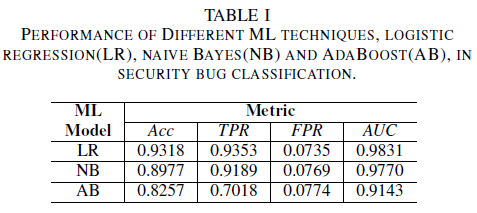
A logisztikai regressziós modell a legjobban teljesítő osztályozó. Ez az osztályozó rendelkezik a legmagasabb AUC-értékkel, amely 0,9826, a visszahívási aránya pedig 0,9353 a 0,0735-ös FPR érték mellett. A naiv Bayes-osztályozó valamivel alacsonyabb teljesítményt mutat, mint a logisztikai regressziós osztályozó, 0,9779 AUC-val és 0,9189-re visszahívással a 0,0769 FPR-hez. Az AdaBoost-osztályozó teljesítménye alacsonyabb a két korábban említett osztályozóhoz képest. 0,9143 AUC-t, 0,0774 FPR-hez pedig 0,7018-at hív vissza. A ROC-görbe (AUC) alatti terület jó metrika több modell teljesítményének összehasonlításához, mivel egyetlen értékben összegzi a TPR és az FPR relációt. Az ezt követő elemzés során az összehasonlító elemzést AUC-értékekre fogjuk korlátozni.
Egy. Osztályzaj: egyetlen osztályú
El lehet képzelni egy forgatókönyvet, amelyben alapértelmezés szerint minden hiba az NSBR osztályhoz van rendelve, és egy hiba csak akkor lesz hozzárendelve az SBR osztályhoz, ha egy biztonsági szakértő áttekinti a hibatárat. Ez a forgatókönyv az egyosztályos kísérleti beállításban jelenik meg, ahol feltételezzük, hogy pnsbr = 0 és 0 < psbr< 0,5.
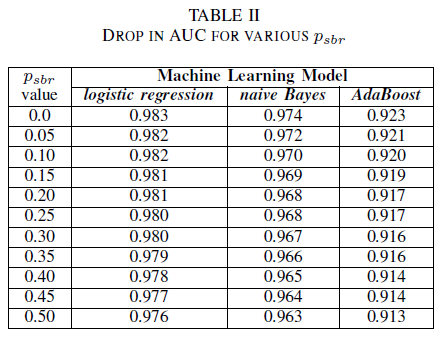
A II. táblázatból mind a három osztályozó esetében nagyon kis hatást tapasztalunk az AUC-ban. Az AUC-ROC érték egy olyan modellből, amelyet a psbr = 0 alapján tanítottak, összehasonlítva egy másik modell AUC-ROC értékével, ahol psbr = 0,25, 0,003-mal különbözik logisztikai regresszió esetén, 0,006-tal a naiv Bayes esetén, és 0,006-tal az AdaBoost esetén. Psbr = 0,50 esetén az egyes modellekhez mért AUC a psbr = 0-val betanított modellhez képest 0,007-tel különbözik a logisztikus regresszió esetén, 0,011-gyel a naiv Bayes esetén, és 0,010-zel az AdaBoost esetén. az egyosztályos zaj jelenlétében betanított logisztikai regressziós osztályozó az AUC-metrika legkisebb variációját, azaz robusztusabb viselkedést mutatja a naiv Bayes- és AdaBoost-osztályozóinkhoz képest.
B. Osztályzaj: osztályfüggetlen
Összehasonlítjuk a három osztályozó teljesítményét abban az esetben, ha a betanítási csoportot osztályfüggetlen zaj rontja. AUC-t mérünk minden egyes modellnél, amit a betanítási adatokban különböző pbr szintekkel tanítottunk.
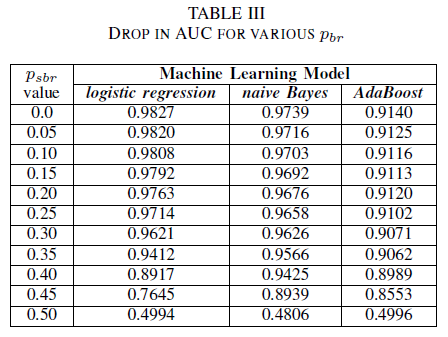
A III. táblázatban a kísérlet minden zajnövekményéhez megfigyeljük a AUC-ROC csökkenését. A zajmentes adatokon betanított modellből mért AUC-ROC különbséget mutat a pbr = 0,25 osztályfüggetlen zajjal betanított modell AUC-ROC értékéhez képest: a logisztikus regresszió esetében 0,011, a naiv Bayes esetében 0,008, és az AdaBoost esetében 0,0038 értékkel. Megfigyeljük, hogy a címkezaj nem befolyásolja jelentősen a naiv Bayes és az AdaBoost osztályozók AUC-ját, ha a zajszint 40-nél alacsonyabb%. A logisztikai regressziós osztályozó viszont hatással van a 30%feletti címkezaj-szintekre vonatkozó AUC-mértékre.
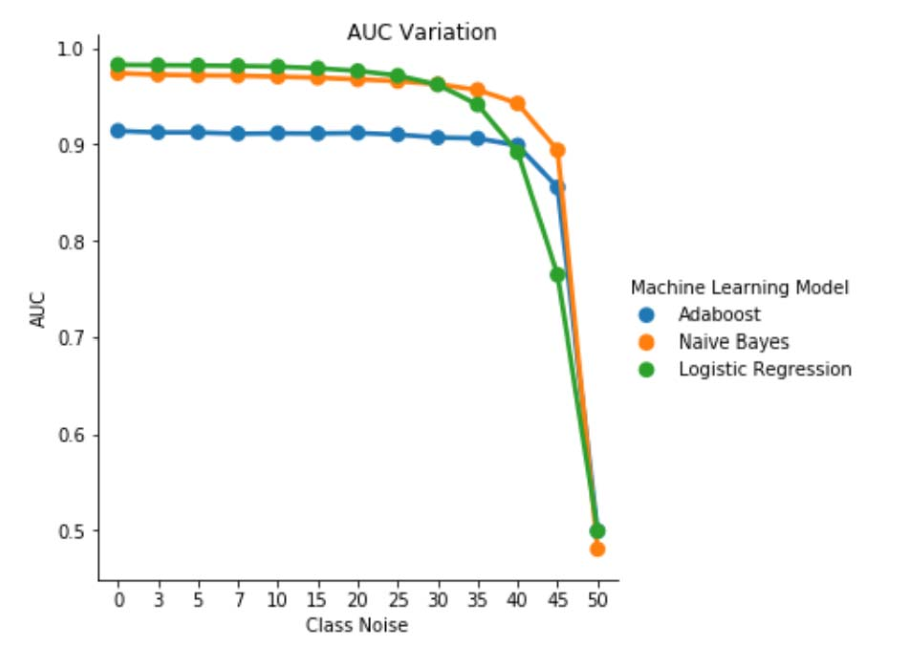
1. ábra. A AUC-ROC variációja osztályfüggetlen zajban. A zajszint pbr =0,5 esetén az osztályozó véletlenszerű osztályozóként működik, azaz AUC≈0.5. Megfigyelhető azonban, hogy az alacsonyabb zajszintek (pbr ≤0.30) esetében a logisztikai regressziós tanuló jobb teljesítményt nyújt a másik két modellhez képest. A 0,35≤ pbr ≤0,45 intervallumban a naiv Bayes-osztályozó jobb AUCROC-metrikákat ér el.
C. Osztályzaj: osztályfüggő
A kísérletek utolsó halmazában egy olyan forgatókönyvet veszünk figyelembe, amelyben a különböző osztályok különböző zajszinteket tartalmaznak, például psbr ≠ pnsbr. Az edzési adatokban a psbr és a pnsbr értéket egymástól függetlenül 0,05-tel növeljük, és megfigyeljük a három osztályozó viselkedésének változását.
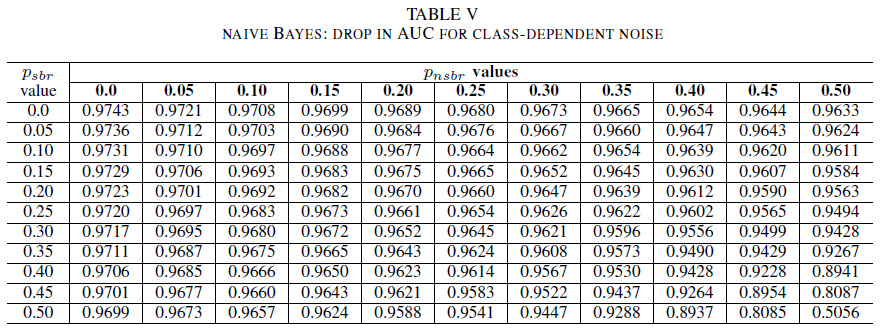
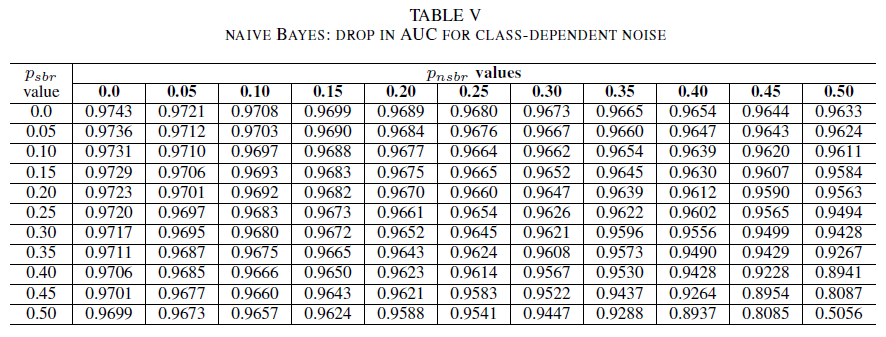
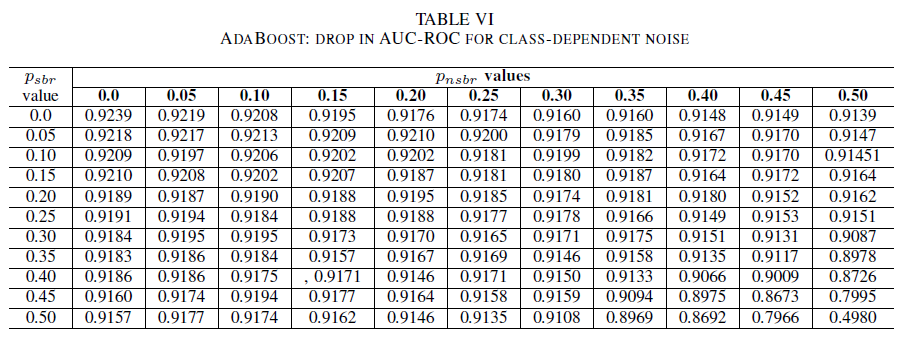
IV., V. és VI. táblázat bemutatja az AUC variációját, amint a zaj szintje nő az egyes osztályokban: a IV. táblázat a logisztikus regresszió, az V. táblázat a naiv Bayes és a VI. táblázat az AdaBoost esetében. Az összes osztályozó esetében az AUC-metrika hatása akkor jelenik meg, ha mindkét osztály 30%feletti zajszintet tartalmaz. A naiv Bayes még erőteljesebben viselkedik. Az AUC-ra gyakorolt hatás akkor is nagyon kicsi, ha a pozitív osztályban lévő 50% címke felcserélődik, feltéve, hogy a negatív osztály legfeljebb 30% zajos címkét tartalmaz. Ebben az esetben az AUC csökkenése 0,03. Az AdaBoost mindhárom osztályozó leg robusztusabb viselkedését mutatta be. Az AUC értékében csak akkor következik be jelentős változás, ha a zajszint mindkét osztályban meghaladja a 45%-t. Ebben az esetben 0,02-nél nagyobb AUC-bomlást kezdünk megfigyelni.
D. A reziduális zaj jelenléte az eredeti adatkészletben
Az adatkészletet aláírásalapú automatizált rendszerek és emberi szakértők címkézték. Ezenkívül az emberi szakértők az összes hibajelentést tovább vizsgálták és lezárták. Bár arra számítunk, hogy az adathalmazban a zaj mennyisége minimális és statisztikailag nem jelentős, a reziduális zaj jelenléte nem érvényteleníti a következtetéseinket. Az ábra kedvéért tegyük fel, hogy az eredeti adatkészletet minden bejegyzésnél egy osztályfüggetlen zaj rontja, amely 0 < p < 1/2 értékű, független és azonos módon elosztott (i.i.d).
Ha az eredeti zajon felül egy osztályfüggetlen zajt adunk hozzá pbr i.i.d valószínűséggel, akkor az eredményül kapott zaj bejegyzésenként p∗ = p(1 − pbr )+(1 − p)pbr . A 0 < p,pbr< 1/2 esetén a címkénkénti tényleges zaj p∗ szigorúan nagyobb, mint a mesterségesen hozzáadott zaj a pbr adatkészlethez. Így az osztályozóink teljesítménye még jobb lenne, ha először egy teljesen zajmentes adatkészlettel (p = 0) tanítanák őket. Összefoglalva, a reziduális zaj megléte a tényleges adathalmazban azt jelenti, hogy osztályozóink zajával szembeni ellenálló képessége jobb, mint az itt bemutatott eredmények. Továbbá, ha az adathalmazban lévő reziduális zaj statisztikailag releváns lenne, az osztályozóink AUC-jának értéke 0,5 -re (véletlenszerű becslés) változna a szigorúan 0,5-nél kisebb zajszint esetén. Az eredményekben nem figyeljük meg az ilyen viselkedést.
VI. KÖVETKEZTETÉSEK ÉS JÖVŐBELI MUNKÁK
Ebben a tanulmányban való közreműködésünk kettős.
Először bemutattuk a biztonsági hibajelentések besorolásának megvalósíthatóságát kizárólag a hibajelentés címe alapján. Ez különösen akkor releváns, ha a teljes hibajelentés adatvédelmi korlátozások miatt nem érhető el. Esetünkben például a hibajelentések privát információkat, például jelszavakat és titkosítási kulcsokat tartalmaztak, és nem voltak elérhetők az osztályozók betanításához. Az eredmény azt mutatja, hogy az SBR-azonosítás akkor is nagy pontossággal elvégezhető, ha csak jelentéscímek érhetők el. A TF-IDF és logisztikai regresszió kombinációját használó besorolási modellünk 0,9831 AUC-n teljesít.
Másodszor elemeztük a hibásan címkézett betanítási és érvényesítési adatok hatását. Három jól ismert gépi tanulási besorolási technikát (naiv Bayes, logisztikai regresszió és AdaBoost) hasonlítottunk össze a különböző zajtípusok és zajszintek robusztussága szempontjából. Mindhárom osztályozó robusztus az egyosztályos zajhoz. A betanulási adatok zaja nincs semmilyen jelentős hatással az eredményezett osztályozóra. Az AUC csökkenése nagyon kicsi (0,01) 50%zajszint esetén . A naiv Bayes- és AdaBoost-modellek jelentős eltéréseket mutatnak az AUC értékében csak akkor, ha mindkét osztályban jelen lévő, osztályfüggetlen zaj mértéke meghaladja a 40%-t az adatkészletben, amellyel betanították őket.
Végül az osztályfüggő zaj csak akkor befolyásolja jelentősen az AUC-t, ha mindkét osztályban több mint 35% zaj van. Az AdaBoost a leg robusztusabb volt. Az AUC hatása akkor is nagyon kicsi, ha a pozitív osztály címkéinek 50% zajos, feltéve, hogy a negatív osztály legfeljebb 45% zajos címkét tartalmaz. Ebben az esetben az AUC csökkenése kisebb, mint 0,03. Legjobb tudásunk szerint ez az első szisztematikus tanulmány a zajos adathalmazok biztonsági hibajelentés-azonosításra gyakorolt hatásáról.
JÖVŐBELI MUNKÁK
Ebben a tanulmányban megkezdtük a zaj hatásának szisztematikus vizsgálatát a gépi tanulási osztályozók teljesítményében a biztonsági hibák azonosítása érdekében. Ennek a munkának számos érdekes folytatása van, többek között a zajos adathalmazok hatásának vizsgálata a biztonsági hibák súlyossági szintjének meghatározásában; az osztályelegyensúlyozatlanságnak a betanított modellek zaj elleni rugalmasságára gyakorolt hatásának megértése; az adathalmazban adversarily módon bevezetett zaj hatásának megértése.
HIVATKOZÁSOK
[1] John Anvik, Lyndon Hiew és Gail C Murphy. Ki javítsa ki ezt a hibát? A 28. Nemzetközi Szoftverfejlesztési Konferencia előadásai, 361–370. oldal. ACM, 2006.
[2] Diksha Behl, Sahil Handa és Anuja Arora. Hibabányászati eszköz a biztonsági hibák Naiv Bayes és tf-idf használatával történő azonosítására és elemzésére. Az Optimalizálás, Megbízhatóság és Információtechnológia (ICROIT), a 2014-es Nemzetközi Konferencia, 294–299. oldal. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann és Sunghun Kim. Ismétlődő hibajelentések, amelyeket valóban károsnak tartanak? Szoftverkarbantartás, 2008. ICSM 2008. IEEE nemzetközi konferencia, 337–345. oldal. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse és Lofton Bullard. A tanulók azonosítása, akik ellenállóak az alacsony minőségű adatokkal szemben. A Információ újrafelhasználása és integrációja, 2008. IRI 2008. IEEE Nemzetközi Konferencia az-en, 190–195. oldal. IEEE, 2008.
[5] Benoˆıt Frenay. Bizonytalanság és címkezaj a gépi tanulásban.. PhD tézis, Katolikus Egyetem Louvain, Louvain-la-Neuve, Belgium, 2013.
[6] Benoˆıt Frenay és Michel Verleysen. Besorolás a "címkezaj" jelenlétében: felmérés. IEEE tranzakciók neurális hálózatokon és tanulási rendszereken, 25(5):845–869, 2014.
[7] Michael Gegick, Pete Rotella és Tao Xie. Biztonsági hibajelentések azonosítása szövegbányászattal: Ipari esettanulmány. A Bányászati szoftvertárak (MSR) 2010 7. IEEE munkakonferenciáján, 11–20. oldal. IEEE, 2010.
Katerina Goseva-Popstojanova és Jacob Tyo. A biztonsággal kapcsolatos hibajelentések azonosítása szövegbányászattal felügyelt és felügyelet nélküli besorolással. A 2018-as IEEE Nemzetközi Konferencia a Szoftverminőségről, Megbízhatóságról és Biztonságról (QRS) ,, 2018, 344–355. oldal.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger és Bart Goethals. Egy jelentett hiba súlyosságának előrejelzése. A Bányászati szoftvertárak (MSR) 2010 7. IEEE munkakonferenciáján, 1–10. oldal. IEEE, 2010.
[10] Naresh Manwani és PS Sastry. Zajtűrés kockázat minimalizálása mellett. IEEE kibernetikai tranzakciók, 43(3):1146–1151, 2013.
[11] G Murphy és D Cubranic. Automatikus hibaleképezés szövegkategorizálással. A Tizenhatodik Nemzetközi Szoftvermérnöki és Tudásmérnöki Konferencia Előadásai &. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen és Oleksandr Pechenizkiy. Osztályzaj és felügyelt tanulás orvosi területeken: A jellemzők kinyerésének hatása. A(z) nullesetében, az oldalakon: 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre és Gerard Dedieu. „A tanuló osztály címkéinek zajosságának hatása a műholdas képsorozatokkal végzett földfedés-leképezés osztályozási teljesítményére.” Távérzékelési, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra és Naresh Manwani. Folyamatos hatású tanulási automata csapat félterek zajrezisztens tanulásához. IEEE Közlemények a Rendszerekre, Emberre és Kibernetikára vonatkozóan, B rész (Kibernetika), 40(1):19–28, 2010.
[15] Choh-Man Teng. A zajkezelési technikák összehasonlítása. A(z) FLAIRS konferenciakiadványában, 269–273. oldal, 2001.
[16] Dumidu Wijayasekara, Milos Manic és Miles McQueen. Biztonságirés-azonosítás és -besorolás szövegbányászati hibaadatbázisokkal. In Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, pages 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia és Jianling Sun. A kiegyensúlyozatlan tanulási stratégiákat kihasználó nagy hatású hibajelentések automatikus azonosítása. A Számítógépes szoftverek és alkalmazások konferenciáján (COMPSAC), 2016 IEEE 40. éves, 1. kötet, 227–232. oldal. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li és Hai Jin. A biztonsági hibajelentések automatikus azonosítása többtípusos funkciók elemzésével. Az Ausztrál-ázsiai Konferencia az Információbiztonságról és Adatvédelemről, oldalak 619–633. Springer, 2018.