Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Andrew Marshall, Jugal Parikh, Emre Kiciman és Ram Shankar Siva Kumar
Külön köszönet Raul Rojasnak és az AETHER Security Engineering Workstreamnek
2019. november
Ez a dokumentum az AETHER mesterséges intelligenciával foglalkozó munkacsoport mérnöki gyakorlatainak terméke, és kiegészíti a meglévő SDL-fenyegetésmodellezési eljárásokat azáltal, hogy új útmutatást nyújt a mesterséges intelligenciára és a gépi tanulási területre vonatkozó fenyegetések számbavételével és kockázatcsökkentésével kapcsolatban. Referenciaként szolgál a következők biztonsági tervének felülvizsgálata során:
Mesterséges intelligencián/ML-alapú szolgáltatásokon interakcióba lépő vagy függőséget vállaló termékek/szolgáltatások
A mesterséges intelligencia/gépi tanulás alapú termékek/szolgáltatások
A hagyományos biztonsági fenyegetések mérséklése minden eddiginél fontosabb. A biztonsági fejlesztési életciklus által meghatározott követelmények elengedhetetlenek egy olyan termékbiztonsági alap létrehozásához, amelyre ez az útmutató épül. A hagyományos biztonsági fenyegetések elhárításának elmulasztása segít engedélyezni a jelen dokumentumban szereplő AI-/ML-specifikus támadásokat mind a szoftveres, mind a fizikai tartományokban, valamint csökkenti a biztonsági réseket a szoftververemen. A net-új biztonsági fenyegetések ezen a téren való bemutatásáért lásd : A mesterséges intelligencia és az ML jövőjének védelme a Microsoftnál.
A biztonsági mérnökök és adattudósok készségei általában nem fedik egymást. Ez az útmutató lehetővé teszi, hogy mindkét tudományág strukturált beszélgetéseket folytatott ezeken a netes új fenyegetéseken/kockázatcsökkentéseken anélkül, hogy a biztonsági mérnökök adattudósokká válhatnak, vagy fordítva.
Ez a dokumentum két szakaszból áll:
- A "Legfontosabb új szempontok a fenyegetésmodellezésben" az új gondolkodásmódra és az AI/ML-rendszerek fenyegetésmodellezése során felteendő új kérdésekre összpontosít. Ezt mind az adattudósoknak, mind a biztonsági mérnököknek át kell tekinteniük, mivel ez lesz a forgatókönyvük a fenyegetésmodellezési megbeszélésekhez és a kockázatcsökkentési rangsoroláshoz.
- Az "AI-/ML-specifikus fenyegetések és azok kockázatcsökkentései" című témakör részletesen ismerteti az adott támadásokat, valamint a Microsoft termékeinek és szolgáltatásainak ezen fenyegetések elleni védelméhez jelenleg használt konkrét kockázatcsökkentési lépéseket. Ez a szakasz elsősorban olyan adattudósokat céloz meg, akiknek a fenyegetésmodellezési/biztonsági felülvizsgálati folyamat kimeneteként konkrét fenyegetéscsökkentéseket kell implementálniuk.
Ez az útmutató Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen és Jeffrey Snover "Failure Modes in Machine Learning" című Adversarial Machine Learning Threat Taxonomy köré van szervezve. A jelen dokumentumban részletezett biztonsági fenyegetések osztályozásával kapcsolatos incidenskezelési útmutatásért tekintse meg az AI/ML-fenyegetések SDL-hibasávját. Ezek mind élő dokumentumok, amelyek idővel fejlődni fognak a fenyegetési környezettel.
A fenyegetésmodellezés legfontosabb új szempontjai: A megbízhatósági határok megtekintésének módosítása
Tegyük fel, hogy a betanított adatok biztonsága vagy mérgezése az adatszolgáltatótól származik. Ismerje meg a rendellenes és rosszindulatú adatbejegyzések észlelését, valamint a köztük való különbségtételt és azok helyreállítását
Összefoglalás
A betanítási adattárak és az azokat üzemeltető rendszerek a fenyegetésmodellezési hatókör részét képezik. A gépi tanulás legnagyobb biztonsági fenyegetése az adatmérgezés, mivel ezen a területen nincs szabványos észlelés és kockázatcsökkentés, és a betanítási adatok forrásaként a nem megbízható/nem minősített nyilvános adathalmazok függőségével párosul. Az adatok eredetének és származásának nyomon követése elengedhetetlen annak megbízhatóságának biztosításához és a "szemétbe, szemétbe" betanítási ciklus elkerüléséhez.
Biztonsági felülvizsgálatban feltenni kívánt kérdések
Ha az adatait megmérgezik vagy megváltoztatják, honnan tudná?
-Milyen telemetriával rendelkezik a tréning adatok minőségének torzulásának észleléséhez?
A felhasználó által megadott bemenetek alapján tanítanak?
-Milyen típusú bemeneti ellenőrzést/tisztítást végez ezen a tartalomon?
– Az adatok struktúrája az Adatlapok Adatkészletekhez hasonlóan van dokumentálva?
Ha online adattárakat használ tanításra, milyen lépéseket tesz a modell és az adatok közötti kapcsolat biztonságának biztosítása érdekében?
- Van mód arra, hogy biztonsági réseket jelentsenek a hírcsatornájuk felhasználóinak?
- Vajon képesek erre?
Mennyire érzékeny az aadat, amellyel tanítanak?
-Katalogizálja vagy szabályozza az adatbejegyzések hozzáadását/frissítését/törlését?
Képes a modell bizalmas adatokat kibocsátani?
- Ezeket az adatokat a forrás engedélyével szerezték be?
A modell csak a cél eléréséhez szükséges eredményeket adja eredményként?
A modell nyers megbízhatósági pontszámokat vagy bármilyen más közvetlen kimenetet ad vissza, amely rögzíthető és duplikálható?
Milyen hatással van a betanítási adatok visszanyerése a modell feltörésével vagy megfordításával?
Ha a modell kimenetének megbízhatósági szintje hirtelen csökken, megtudhatja, hogyan/miért, valamint az azt okozó adatokkal?
Definiált egy jól formázott bemenetet a modellhez? Mit tesz annak érdekében, hogy a bemenetek megfeleljenek ennek a formátumnak, és mit tegyen, ha nem?
Ha a kimenetek hibásak, de nem okoznak hibajelentést, honnan tudhatná?
Tudja, hogy a betanítási algoritmusok rugalmasak-e matematikai szinten a támadó bemenetekkel szemben?
Hogyan lehet helyreállni a betanítási adatok kártékony szennyeződéséből?
- El tudja különíteni/karanténba helyezni a kártékony tartalmakat, és újra betaníthatja az érintett modelleket?
-Visszaállítható/helyreállítható egy korábbi verzió modellje az újratanításhoz?
Nem minősített nyilvános tartalmakon használja a Reinforcement Learninget?
Kezdjen el gondolkodni az adatok eredetéről – ha problémát találna, tudná követni a bevezetésének folyamatát az adathalmazban? Ha nem, az probléma?
Tudja, honnan származnak a betanítási adatok, és azonosítsa a statisztikai normákat annak érdekében, hogy megértse, hogyan néznek ki az anomáliák
-A betanítási adatok mely elemei vannak kitéve a külső hatásoknak?
- Ki járulhat hozzá az ön által betanítandó adatkészletekhez?
– Hogyan támadná meg a betanítási adatok forrásait, hogy kárt okozz egy versenytársnak?
Kapcsolódó fenyegetések és kockázatcsökkentések ebben a dokumentumban
Adversarial Perturbation (minden változat)
Adatmérgezés (minden változat)
Példák a támadásokra
A jóindulatú e-mailek levélszemétként való besorolása kényszerítése vagy a rosszindulatú példák észrevétlen maradása
Támadó által készített bemenetek, amelyek csökkentik a megfelelő besorolás megbízhatósági szintjét, különösen a nagy következménnyel járó helyzetekben
A támadó véletlenszerűen injektál zajt a besorolt forrásadatokba, hogy csökkentse a megfelelő besorolás valószínűségét a jövőben, és hatékonyan lebutíthassa a modellt
A betanítási adatok szennyeződése a kiválasztott adatpontok helytelen besorolásának kényszerítése érdekében, ami meghatározott műveletek végrehajtását vagy kihagyását eredményezi egy rendszer számára
Azonosítsa azokat a műveleteket, amelyeket a modell(ek) vagy a termék/szolgáltatás végrehajthat, ami az ügyfelek online vagy fizikai tartománybeli károsodását okozhatja
Összefoglalás
Ha nem enyhítik, az AI/ML-rendszerek elleni támadások átcsaphatnak a fizikai világba. Minden olyan forgatókönyv, amely pszichés vagy fizikai károkat okozhat a felhasználóknak, katasztrofális kockázatot jelent a termékre/szolgáltatásra nézve. Ez kiterjed az ügyfelekre vonatkozó bizalmas adatokra, amelyeket betanítási és tervezési döntésekhez használnak, amelyek kiszivároghatnak ezekről a privát adatpontokról.
Biztonsági felülvizsgálatban feltenni kívánt kérdések
Adversarial példákkal tanít? Milyen hatással vannak a modell kimenetére a fizikai tartományban?
Hogyan néz ki a trollkodás a termékhez/szolgáltatáshoz? Hogyan észlelheti és válaszolhat rá?
Mi szükséges ahhoz, hogy a modell olyan eredményt adjon vissza, amely a szolgáltatását arra utasítja, hogy megtagadja a hozzáférést a jogszerű felhasználókhoz?
Milyen hatással van arra, ha a modell másolják vagy ellopják?
Használhatja a modellt arra, hogy egy adott csoportban vagy egyszerűen a betanítási adatokban egy adott személy tagságát következtethesse?
Okozhat-e a támadó hírnévromlást vagy PR-visszahatást a termékének azáltal, hogy adott műveletek végrehajtására kényszeríti?
Hogyan kezeli a megfelelően formázott, de túlzottan elfogult adatokat, például trollokból?
A modell minden interakciója vagy lekérdezése esetén kikérdezhető ez a módszer a betanítási adatok vagy a modell funkcióinak felfedése érdekében?
Kapcsolódó fenyegetések és kockázatcsökkentések ebben a dokumentumban
Tagsági következtetés
Modell-inverzió
Modell ellopása
Példák a támadásokra
Betanítási adatok rekonstrukciója és kinyerése a modell ismételt lekérdezésével a maximális megbízhatósági eredmények érdekében
A modell megkettőzése kimerítő lekérdezési/válaszegyeztetés révén
A modell lekérdezése oly módon, hogy kiderüljön a személyes adatok egy adott eleme, amely szerepelt a betanítási készletben.
Önvezető autót úgy manipulálják, hogy figyelmen kívül hagyja a stop táblákat és közlekedési lámpákat.
Beszélgetési robotok manipulálva a jóindulatú felhasználók trollkodására
Azonosítsa az AI-/ML-függőségek összes forrását, valamint az előtérbeli bemutató rétegeket az adat-/modell ellátási láncában
Összefoglalás
Az AI és a Machine Learning számos támadása az API-khoz való jogszerű hozzáféréssel kezdődik, amelyek a modell lekérdezési hozzáférésének biztosítása érdekében jelennek meg. A gazdag adatforrások és a gazdag felhasználói élmény miatt a hitelesített, de "nem megfelelő" (itt van egy szürke terület) harmadik fél általi hozzáférés a modellekhez kockázatot jelent, mivel egy Microsoft által nyújtott szolgáltatás feletti bemutatórétegként is működhet.
Biztonsági felülvizsgálatban feltenni kívánt kérdések
Mely ügyfelek/partnerek vannak hitelesítve a modellhez vagy szolgáltatás API-khoz való hozzáféréshez?
- Működhetnek bemutató rétegként a szolgáltatás tetején?
- Gyorsan visszavonhatja a hozzáférésüket, ha veszélybe kerül?
- Mi a helyreállítási stratégia a szolgáltatás vagy függőségek rosszindulatú használata esetén?
Felépíthet-e egy harmadik fél egy külső réteget a modell köré, hogy újrahasznosítsa azt, és kárt okozzon a Microsoftnak vagy ügyfeleinek?
Az ügyfelek közvetlenül biztosítják Önnek a betanítási adatokat?
- Hogyan védi az adatokat?
- Mi a teendő, ha rosszindulatú, és a szolgáltatás a cél?
Hogyan néz ki itt egy hamis pozitív? Milyen hatása van a hamis negatívnak?
Nyomon tudja követni és mérni az igaz pozitív és a hamis pozitív arányok eltérését több modellben?
Milyen típusú telemetriára van szüksége ahhoz, hogy igazolja a modell kimenetének megbízhatóságát az ügyfelek számára?
Azonosítsa a harmadik féltől származó függőségeket az ML/betanítási adatelőállítási láncban – nem csak a nyílt forráskódú szoftvereket, hanem az adatszolgáltatókat is.
- Miért használja őket, és hogyan ellenőrzi a megbízhatóságukat?
Használ harmadik féltől származó előre elkészített modelleket, vagy betanítási adatokat küld harmadik fél MLaaS-szolgáltatóknak?
Leltár hírek a hasonló termékek/szolgáltatások elleni támadásokról. Tisztában van azzal, hogy a modelltípusok közötti számos AI-/ML-fenyegetés átvitele milyen hatással lenne ezekre a támadásokra a saját termékeire?
Kapcsolódó fenyegetések és kockázatcsökkentések ebben a dokumentumban
Neurális net-újraprogramozás
Ellenséges példák a fizikai tartományban
Rosszindulatú gépi tanulási szolgáltatók, akik helyreállítják a betanítási adatokat
Az ML ellátási lánc megtámadása
Hátsóajtós Modell
Kompromittálódott ML-specifikus függőségek
Példák a támadásokra
A rosszindulatú MLaaS-szolgáltató egy meghatározott megkerülési módszerrel trójait helyez el a modelljükben.
Az ellenséges ügyfél biztonsági rést talál egy gyakran használt OSS-függőségben, feltölti a manipulált betanítási adatcsomagot a szolgáltatás veszélyeztetése érdekében.
A gátlástalan partner arcfelismerő API-kat használ, és egy bemutatóréteget hoz létre a szolgáltatáson keresztül a Deep Fakes létrehozásához.
AI-/ML-specifikus fenyegetések és azok kockázatcsökkentései
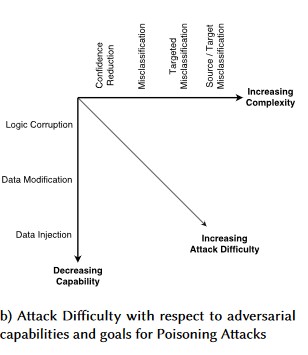
#1: Adverziális Zavarás
Leírás
Perturbáció stílusú támadások esetén a támadó alaposan módosítja a lekérdezést, hogy egy éles környezetben üzembe helyezett modellből elérje a kívánt választ[1]. Ez a modell bemeneti integritásának megsértése, amely olyan fuzzing-típusú támadásokhoz vezet, amelyek végeredménye nem feltétlenül a hozzáférés megsértése vagy a folyamat végpont megsértése, hanem a modell osztályozási teljesítményének veszélyeztetése. Ez bizonyos célszavakat használó trollok számára is nyilvánulhat meg oly módon, hogy az AI tiltsa őket, gyakorlatilag megtagadva a szolgáltatást a jogszerű felhasználóktól egy "tiltott" szónak megfelelő névvel.
 [24]
[24]
Variant #1a: Célzott helytelen besorolás
Ebben az esetben a támadók olyan mintát generálnak, amely nem tartozik a célzott osztályozó bemeneti osztályába, de a modell tévesen besorolja az adott bemeneti osztályba. A támadói minta véletlenszerű zajként jelenhet meg az emberi szem számára, de a támadók némi ismeretekkel rendelkeznek a célgép-tanulási rendszerről, hogy olyan fehér zajt generáljanak, amely nem véletlenszerű, hanem kihasználja a célmodell bizonyos aspektusait. A támadó olyan bemeneti mintát ad, amely nem legitim minta, de a célrendszer jogszerű osztályként sorolja be.
Példák
 [6]
[6]
Enyhítő intézkedések
Az Adversarial Training által kiváltott modell megbízhatóságának alkalmazása az Adversarial Robustness megerősítésére [19]: A szerzők a Nagyon Magabiztos Közeli Szomszéd (HCNN) nevű keretrendszert javasolják, amely kombinálja a megbízhatósági információkat és a legközelebbi szomszédkeresést, hogy megerősítse az alapmodellek adversarialis robusztusságát. Ez segíthet megkülönböztetni a helyes és helytelen modellelőjelzéseket az alapul szolgáló betanítási eloszlásból vett pont szomszédságában.
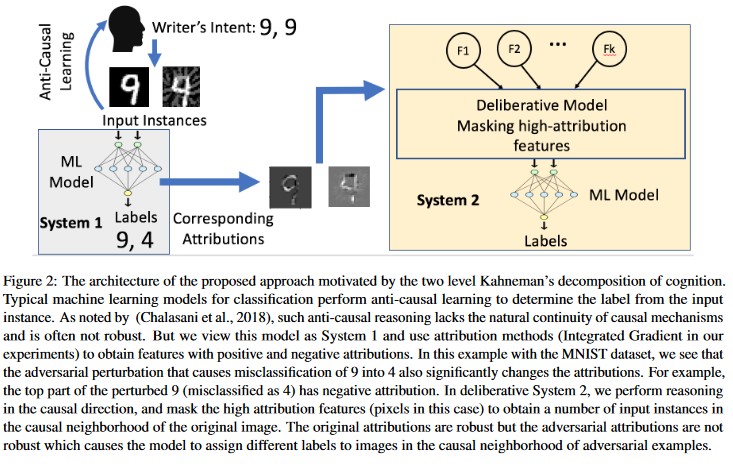
Attribútumalapú ok-okozati elemzés [20]: A szerzők az adversarial perturbációkkal szembeni rugalmasság és a gépi tanulási modellek által generált egyedi döntések attribútumalapú magyarázata közötti kapcsolatot tanulmányozzák. Azt jelentik, hogy az adverzális bemenetek nem robusztusak az attribúciós térben, azaz a magas attribúciós értékkel rendelkező néhány tulajdonság maszkolása változást okoz a gépi tanulási modellnek az adverzális példákon való döntésében. Ezzel szemben a természetes bemenetek robusztusak a forrástérben.
 [20]
[20]
Ezek a megközelítések ellenállóbbá tehetik a gépi tanulási modelleket a támadó támadásokkal szemben, mivel a kétrétegű megismerési rendszer becsapásához nem csak az eredeti modell megtámadása szükséges, hanem annak biztosítása is, hogy a támadó példához létrehozott hozzárendelés az eredeti példához hasonló legyen. Mindkét rendszert egyszerre kell feltörni egy sikeres támadó támadáshoz.
Hagyományos párhuzamok
Távoli jogosultságszint-emelés, mivel a támadó jelenleg a modell felett van
Súlyosság
Nélkülözhetetlen
Variant #1b: Forrás/Cél helytelen besorolása
Ezt úgy jellemzi, hogy a támadó megpróbálja lekérni a modellt, hogy visszaadja a kívánt címkét egy adott bemenethez. Ez általában arra kényszeríti a modellt, hogy hamis pozitív vagy hamis negatív értéket adjon vissza. A végeredmény a modell osztályozási pontosságának finom átvétele, amely révén a támadó akaratuk szerint képes megkerüléseket létrehozni.
Bár ez a támadás jelentős káros hatással van a besorolás pontosságára, időt is igénybe vehet, mivel a támadónak nem csak a forrásadatokat kell manipulálnia, hogy az már ne legyen megfelelően megjelölve, hanem kifejezetten a kívánt hamis címkével is megcímkézze őket. Ezek a támadások gyakran több lépést/kísérletet is magukban foglalnak a helytelen besorolás kényszerítésére [3]. Ha a modell érzékeny a célzott helytelen besorolást kényszerítő tanulási támadások átvitelére, előfordulhat, hogy nem észlelhető a támadók forgalmi lábnyoma, mivel a próbatámadások offline módban is végrehajthatók.
Példák
Arra kényszerítve a jóindulatú e-maileket, hogy levélszemétként legyenek besorolva, vagy rosszindulatú példát okozva észrevétlenül menjenek. Ezeket model kikerülési vagy mimikri támadásoknak is nevezik.
Enyhítő intézkedések
Reaktív/védekező észlelési műveletek
- Implementáljon egy minimális időküszöböt a besorolási eredményeket nyújtó API-ba irányuló hívások között. Ez lelassítja a többlépéses támadástesztelést azáltal, hogy növeli a sikeres zavaráshoz szükséges teljes időt.
Proaktív/védelmi műveletek
Jellemzők zajmentesítése az adverzáriális robusztusság növelésére [22]: A szerzők egy új hálózati architektúrát fejlesztenek ki, amely a jellemzők zajmentesítésével növeli az adverzáriális robusztusságot. A hálózatok olyan blokkokat tartalmaznak, amelyek nem helyi eszközök vagy más szűrők használatával szűrik a jellemzőket; az egész hálózatot végponttól végpontig képzik. A támadói betanítással kombinálva a hálózatokat denoizáló funkció jelentősen javítja a támadási hatékonyság csúcsát mind a white-box, mind a black-box támadási beállításokban.
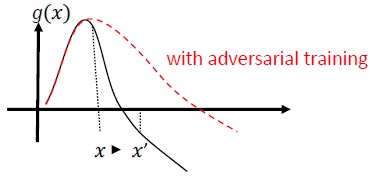
Ellenséges Képzés és Szabályozás: Képezzen ismert ellenséges mintákkal, rugalmasságot és ellenálló képességet építve a rosszindulatú bemenetekkel szemben. Ez a szabályszerűség egyik formája is lehet, amely bünteti a bemeneti színátmenetek normát, és simábbá teszi az osztályozó előrejelzési függvényét (növelve a bemeneti margót). Ide tartoznak az alacsonyabb megbízhatósági arányú helyes besorolások.
Fektessen be a monoton besorolás fejlesztésébe monoton jellemzők kiválasztásával. Ez biztosítja, hogy a támadó nem kerülheti el az osztályozót úgy, hogy egyszerűen kipárnáztatja a negatív osztály elemeit [13].
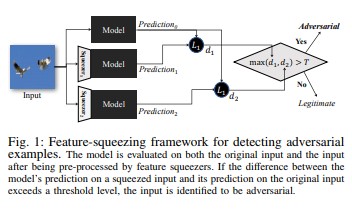
A funkcióbeszorítás [18] használható a DNN-modellek megkeményítésére a támadó példák észlelésével. Csökkenti a támadók számára elérhető keresési területet azáltal, hogy az eredeti tér számos különböző funkcióvektorának megfelelő mintákat egyetlen mintába alakítja. Ha összehasonlítja egy DNN-modell eredeti bemenetre vonatkozó előrejelzését a kipréselt bemenettel, a funkciók lenyomása segíthet észlelni a támadó példákat. Ha az eredeti és a kipréselt példák jelentősen eltérő kimeneteket eredményeznek a modelltől, a bemenet valószínűleg kártékony lesz. Az előrejelzések közötti eltérés mérésével és egy küszöbérték kiválasztásával a rendszer képes a helyes előrejelzést megadni a helyes példákhoz, és elutasítja a támadó bemeneteket.

 [18]
[18]Certified Defenses against Adversarial Examples [22]: A szerzők egy félig határozott relaxáción alapuló módszert javasolnak, amely egy tanúsítványt ad ki, amely egy adott hálózati és tesztelési bemenet esetén nem kényszerítheti a hibát egy bizonyos érték túllépésére. Másodszor, mivel ez a tanúsítvány megkülönböztethető, a szerzők közösen optimalizálják a hálózati paraméterekkel, és egy adaptív regularizert biztosítanak, amely minden támadással szemben robusztusságot ösztönöz.
Válaszműveletek
- Riasztásokat ad ki a besorolási eredményekről az osztályozók közötti nagy eltéréssel, különösen akkor, ha egyetlen felhasználóból vagy kis felhasználói csoportból származik.
Hagyományos párhuzamok
Távoli jogosultság-emelés
Súlyosság
Nélkülözhetetlen
Variant #1c: Véletlenszerű helytelen besorolás
Ez egy speciális változat, amelyben a támadó célbesorolása nem lehet más, mint a jogos forrásbesorolás. A támadás általában magában foglalja a zaj véletlenszerű beinjektálását a besorolt forrásadatokba annak érdekében, hogy csökkenjen annak a valószínűsége, hogy a jövőben megfelelő besorolást használnak [3].
Példák
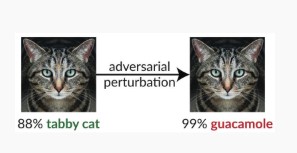
Enyhítő intézkedések
Ugyanaz, mint az 1a változat.
Hagyományos párhuzamok
Nem állandó szolgáltatásmegtagadás
Súlyosság
Fontos
Variant #1d: Megbízhatóság csökkentése
A támadók bemeneteket készíthetnek a megfelelő besorolás megbízhatósági szintjének csökkentése érdekében, különösen a nagy következményekkel járó helyzetekben. Ez számos hamis pozitívum formájában is megjelenhet, amelyek a rendszergazdákat vagy a monitorozási rendszereket próbálják túlterhelni, mivel ezeket a hamis riasztásokat nem lehet megkülönböztetni a legitim riasztásoktól [3].
Példák

Enyhítő intézkedések
- A Variant #1a által érintett műveletek mellett az események szabályozása is alkalmazható az egyetlen forrásból származó riasztások mennyiségének csökkentésére.
Hagyományos párhuzamok
Nem állandó szolgáltatásmegtagadás
Súlyosság
Fontos
#2a célzott adatmérgezés
Leírás
A támadó célja a betanítási fázisban létrehozott gépmodell szennyeződése, hogy az új adatokra vonatkozó előrejelzések a tesztelési fázisban módosuljanak[1]. Célzott mérgezéses támadások esetén a támadó meg szeretné tévesen besorolni a konkrét példákat, hogy adott műveleteket hajtsanak végre vagy hagyjanak ki.
Példák
Az AV-szoftverek kártevőként való benyújtása annak érdekében, hogy hibásan rosszindulatúként sorolják be, és így megszüntessék a célzott AV-szoftverek használatát az ügyfélrendszereken.
Enyhítő intézkedések
Anomáliadetektívek definiálása az adateloszlás napi szintű megtekintéséhez és a változatokra vonatkozó riasztásokhoz
-A betanítási adatok napi változásainak mérése, telemetria ferdeség/eltérés esetén
Bemeneti ellenőrzés, mind a fertőtlenítés, mind az integritás ellenőrzése
A mérgezés károsítja a kívülálló tanítómintákat. A fenyegetés elleni küzdelem két fő stratégiája:
-Adatfertőtlenítés/ -ellenőrzés: mérgezési minták eltávolítása a betanítási adatokból -Bagging a mérgezéses támadások elleni küzdelemhez [14]
-Reject-on-Negative-Impact (RONI) védelem [15]
-Robust Learning: Olyan tanulási algoritmusokat válasszon, amelyek mérgezési minták jelenlétében robusztusak.
-Az egyik ilyen megközelítést a [21] ismerteti, ahol a szerzők két lépésben foglalkoznak az adatmérgezés problémájával: 1) bevezetnek egy új, robusztus mátrix-faktorizációs módszert a valódi altér helyreállításához, és 2) egy új, robusztus elvi összetevő regresszióját az adversarial-példányok eltávolításához az (1) lépésben helyreállított alap alapján. Ezek jellemzik a valódi altér sikeres helyreállításához szükséges és elégséges feltételeket, és bemutatnak egy határt a földi igazsághoz képest várható előrejelzési veszteségre vonatkozóan.
Hagyományos párhuzamok
Trójai gazdagép, amelyen keresztül a támadó tartósan a hálózaton marad. A betanítási vagy konfigurációs adatok biztonsága sérül, és a modelllétrehozáshoz be van osztva/megbízható.
Súlyosság
Nélkülözhetetlen
#2b Válogatás nélküli adatmérgezés
Leírás
A cél az, hogy tönkretegye a megtámadott adatkészlet minőségét/integritását. Számos adathalmaz nyilvános/nem megbízható/nem minősített, ezért ez további aggályokat vet fel az ilyen adatintegritási jogsértések észlelése kapcsán. Az ismeretlenül veszélyeztetett adatokkal végzett betanítás egy olyan helyzet, ahol rossz a bemenet, rossz a kimenet. Az észlelés után a triage-nek meg kell határoznia a megsértett adatok mértékét, valamint a karantént/újratanítást.
Példák
A vállalat lekapar egy jól ismert és megbízható webhelyet az olaj határidős adataihoz a modelljeik betanítása érdekében. Az adatszolgáltató webhelye ezt követően sql-injektálási támadáson keresztül sérül. A támadó akarata szerint megmérgezheti az adathalmazt, és a betanított modell nem tudja, hogy az adatok el vannak-e szennyezve.
Enyhítő intézkedések
Ugyanaz, mint a 2a változat.
Hagyományos párhuzamok
Hitelesített szolgáltatásmegtagadás egy értékes vagyontárgy ellen.
Súlyosság
Fontos
#3 Modell inverziós támadásai
Leírás
A gépi tanulási modellekben használt privát funkciók helyreállíthatók [1]. Ez magában foglalja az olyan privát betanítási adatok rekonstruálását, amelyekhez a támadó nem fér hozzá. Más néven hegymászó támadások a biometrikus közösségben [16, 17] Ezt úgy érik el, hogy megtalálják azt a bemenetet, amely maximalizálja a visszaadott megbízhatósági szintet, a célnak megfelelő besorolásnak [4] megfelelően.
Példák
 [4]
[4]
Enyhítő intézkedések
A bizalmas adatokból betanított modellek interfészeinek erős hozzáférés-vezérlésre van szükségük.
Modell által engedélyezett sebességkorlátos lekérdezések
A felhasználók/hívók és a tényleges modell közötti kapuk implementálása az összes javasolt lekérdezés bemeneti ellenőrzésének végrehajtásával, elutasítva mindent, amely nem felel meg a modell bemeneti helyességének definíciójának, és csak a minimálisan szükséges információmennyiséget adja vissza.
Hagyományos párhuzamok
Célzott, fedett információfeltárás
Súlyosság
Ez alapértelmezés szerint fontos a standard SDL hibasáv alapján, de ha bizalmas vagy személyazonosításra alkalmas adatokat nyernek ki, akkor ez kritikus szintre emelkedik.
#4 Tagsági következtetési támadás
Leírás
A támadó megállapíthatja, hogy egy adott adatrekord a modell betanítási adatkészletének része volt-e[1]. A kutatók az attribútumok (pl. életkor, nem, kórház) alapján előre tudták jelezni a páciens fő eljárását (pl. a beteg műtétjét).
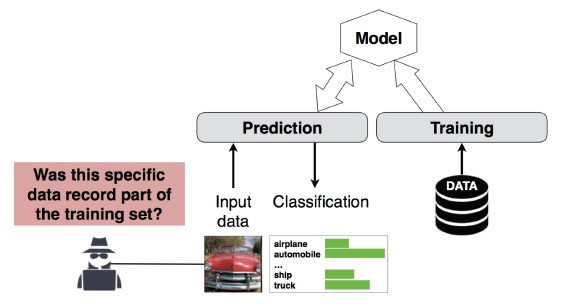 [12]
[12]
Enyhítő intézkedések
A támadás életképességét bemutató kutatási dokumentumok szerint a differenciált adatvédelem [4, 9] hatékony megoldás lenne. Ez még mindig egy feltörekvő terület a Microsoftnál, és az AETHER Security Engineering azt javasolja, hogy szakértelmet építsünk a kutatási befektetésekkel ezen a területen. Ennek a kutatásnak számba kell vennie a különbségi adatvédelmi képességeket, és kockázatcsökkentésként értékelnie kell a gyakorlati hatékonyságukat, majd meg kell terveznie a védelmi megoldások transzparens öröklésének módjait az online szolgáltatási platformjainkon, hasonlóan ahhoz, ahogyan a Visual Studióban a kód összeállítása on-byalapértelmezett biztonsági védelmet nyújt, amelyek transzparensek a fejlesztő és a felhasználók számára.
A neuronok kiesésének és a modellek halmozásának használata bizonyos mértékig hatékony megoldás lehet. A neuronok kiesése nemcsak növeli a neurális háló rugalmasságát a támadással szemben, hanem növeli a modell teljesítményét is [4].
Hagyományos párhuzamok
Adatvédelem. Következtetéseket vonunk le arról, hogy egy adatpont szerepel-e a betanítási csoportban, de maga a betanítási adatok nem kerülnek nyilvánosságra
Súlyosság
Ez adatvédelmi probléma, nem biztonsági probléma. A fenyegetésmodellezési útmutató azért foglalkozik vele, mert a tartományok átfedésben vannak, de itt minden választ az adatvédelem, nem pedig a biztonság vezérelne.
#5 Modelllopás
Leírás
A támadók a modell jogszerű lekérdezésével újra létrehoznak egy mögöttes modellt. Az új modell működése megegyezik a mögöttes modell funkcióival[1]. A modell újbóli létrehozása után megfordítható, hogy helyreállíthatóak legyenek a jellemző információk, vagy következtetéseket vonhassunk le a betanulási adatok alapján.
Egyenletmegoldás – Az osztály valószínűségét API-kimenettel visszaadó modell esetében a támadó lekérdezéseket készíthet a modell ismeretlen változóinak meghatározásához.
Útvonal keresés – olyan támadás, amely az API-sajátosságokat kihasználó módon kinyeri a döntéseket, amelyeket a fa hoz a bemenet osztályozásakor [7].
Átvihetőségi támadás – A támadók betaníthatnak egy helyi modellt – lehetséges, hogy előrejelzési lekérdezéseket bocsátanak ki a megcélzott modellnek –, és használva olyan támadó példákat készíthetnek, amelyek átkerülnek a célmodellbe [8]. Ha a modell kinyerése után sebezhetőnek bizonyul egy ellenséges bemenettel szemben, az éles környezetben működő modell ellen irányuló új támadásokat teljesen offline módon fejlesztheti ki az a támadó, aki kinyert egy példányt a modellből.
Példák
Azokban a beállításokban, ahol az ML-modell a támadó viselkedés észlelésére szolgál, például a levélszemét azonosítására, a kártevők besorolására és a hálózati anomáliák észlelésére, a modell kinyerése megkönnyítheti a kijátszási támadásokat [7].
Enyhítő intézkedések
Proaktív/védelmi műveletek
Minimalizálja vagy elrejtse az előrejelzési API-kban visszaadott adatokat, miközben továbbra is megőrzi hasznosságát a "becsületes" alkalmazások számára [7].
Adjon meg egy jól formázott lekérdezést a modell bemeneteihez, és csak a kész, jól formázott, a formátumnak megfelelő bemenetekre adott válaszként adja vissza az eredményeket.
Kerekített megbízhatósági értékeket ad vissza. A legtöbb megbízható hívónak nincs szüksége több tizedesjegyű precizitásra.
Hagyományos párhuzamok
A rendszeradatok hitelesítés nélküli, csak olvasható befolyásolása, célzott, magas értékű adatkitettség?
Súlyosság
Fontos a biztonsági szempontból érzékeny modellekben, mérsékelten különben
#6 Neurális net-újraprogramozás
Leírás
Egy támadótól származó, speciálisan létrehozott lekérdezéssel a gépi tanulási rendszerek átprogramozhatók olyan feladatra, amely eltér a létrehozó eredeti szándékától [1].
Példák
Gyenge hozzáférési ellenőrzések egy arcfelismerő API-n, amely lehetővé teszi, hogy harmadik felek beépítsék olyan alkalmazásokba, amelyek kárt okoznak a Microsoft ügyfeleinek, például egy deep fake generátor.
Enyhítő intézkedések
Erős ügyfél-kiszolgáló<> kölcsönös hitelesítés és hozzáférés-vezérlés a modell interfészeihez
A jogsértő fiókok levétele.
Azonosítsa és kényszerítse ki az API-k szolgáltatásszintű szerződését. Állapítsa meg a hiba elfogadható kijavítási idejét, miután jelentette, és győződjön meg arról, hogy a probléma már nem jelentkezik, ha az SLA lejár.
Hagyományos párhuzamok
Ez egy visszaélési forgatókönyv. Kevésbé valószínű, hogy biztonsági incidenst kezdeményez ezen, mint hogy egyszerűen letiltsa az elkövető fiókját.
Súlyosság
Fontosból kritikussá
#7 Ellenséges példa a fizikai tartományban (bitek-atomok>)
Leírás
A támadó példa egy rosszindulatú entitás bemenete/lekérdezése, amelynek célja kizárólag a gépi tanulási rendszer félrevezetése [1]
Példák
Ezek a példák a fizikai tartományban nyilvánulhatnak meg, például egy önvezető autó, amely egy stopjel futtatásával trükközik, mert egy bizonyos színű fény (a támadó bemenet) a stop jelre kerül, és arra kényszeríti a képfelismerő rendszert, hogy többé ne láthassa a stopjelet stop jelként.
Hagyományos párhuzamok
Jogosultságszint emelése, távoli kódvégrehajtás
Enyhítő intézkedések
Ezek a támadások azért jelentkeznek, mert a gépi tanulási réteg (az AI-alapú döntéshozatal alatti adat- és algoritmusréteg) problémáit nem enyhítették. Akárcsak más szoftverek vagy fizikai rendszerek esetében, a cél alatti réteg mindig támadható hagyományos támadási vektorokkal. Emiatt a hagyományos biztonsági eljárások minden eddiginél fontosabbak, különösen az AI és a hagyományos szoftverek között használt, enyhítetlen sebezhetőségek rétege (adat/algo réteg) miatt.
Súlyosság
Nélkülözhetetlen
#8 Rosszindulatú ML-szolgáltatók, akik visszanyerhetik a betanítási adatokat
Leírás
A rosszindulatú szolgáltatók egy háttéralgoritmust mutatnak be, amelyben a privát betanítási adatok helyreállnak. Képesek voltak arcokat és szövegeket rekonstruálni, egyedül a modellnek köszönhetően.
Hagyományos párhuzamok
Célzott információfelfedés
Enyhítő intézkedések
A támadás életképességét bemutató kutatási dokumentumok szerint a homomorf titkosítás hatékony megoldás lenne. Ez egy olyan terület, ahol kevés befektetés van a Microsoftnál és az AETHER Security Engineering azt javasolja, hogy szakértelmet építsünk ki a kutatási befektetésekkel ezen a területen. Ennek a kutatásnak a homomorf titkosítási halmazokat kell számba vennie, és a gyakorlati hatékonyságukat kockázatcsökkentésként kell értékelnie a rosszindulatú ml-szolgáltatókkal szemben.
Súlyosság
Fontos, ha az adatok személyes azonosító információkat tartalmaznak, egyébként mérsékelt helyzet.
#9 Az ML ellátási lánc megtámadása
Leírás
Az algoritmusok betanítása érdekében szükséges nagy erőforrások (adatok + számítások) miatt a jelenlegi gyakorlat az, hogy a nagyvállalatok által betanított modelleket újra felhasználják, és kissé módosítják őket a feladathoz (például: A ResNet a Microsoft népszerű képfelismerő modellje). Ezek a modellek a Model Zoo-ban vannak összeválogatva (a Caffe népszerű képfelismerő modelleket üzemeltet). Ebben a támadásban a támadó megtámadja a Caffe-ban üzemeltetett modelleket, ezáltal bárki más számára megmérgezi a kútokat. [1]
Hagyományos párhuzamok
Harmadik fél nem biztonsági jellegű függőségének kompromittálása
Az App Store tudatlan módon üzemeltet kártevőt
Enyhítő intézkedések
Lehetőség szerint minimalizálja a modellek és adatok külső függőségeit.
Ezeket a függőségeket beépítheti a fenyegetésmodellezési folyamatba.
Használja ki az erős hitelesítést, a hozzáférés-vezérlést és a titkosítást az első/másik fél rendszerek között.
Súlyosság
Nélkülözhetetlen
#10 Backdoor Machine Learning
Leírás
A betanítási folyamatot kiszervezik egy rosszindulatú harmadik félnek, aki illetéktelenül módosítja a betanítási adatokat, és olyan trójai modellt adott meg, amely a célzott téves besorolásokat kényszeríti, például egy bizonyos vírus nem rosszindulatúként való besorolását[1]. Ez a szolgáltatásként történő ml-modellgenerálási forgatókönyvekben kockázatot jelent.
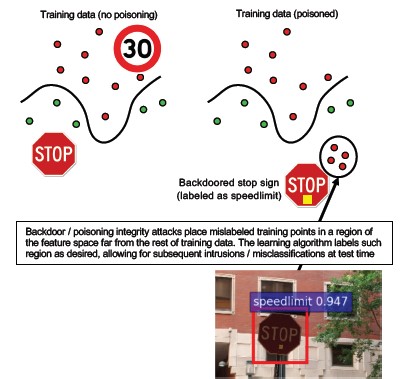 [12]
[12]
Hagyományos párhuzamok
Harmadik fél biztonsági függőségének veszélyeztetése
Sérült szoftverfrissítési mechanizmus
Hitelesítésszolgáltató kompromittálása
Enyhítő intézkedések
Reaktív/védekező észlelési műveletek
- A kár már megtörtént a fenyegetés felderítése után, így a rosszindulatú szolgáltató által biztosított modell és betanítási adatok nem megbízhatók.
Proaktív/védelmi műveletek
Az összes érzékeny modell betanítása házon belül
Betanítási adatok katalógusa, vagy győződjön meg arról, hogy egy megbízható, erős biztonsági eljárásokkal rendelkező harmadik féltől származnak
Fenyegetésmodell az MLaaS-szolgáltató és a saját rendszerek közötti interakcióra
Válaszműveletek
- Ugyanaz, mint a külső függőségek kompromittálása esetén
Súlyosság
Nélkülözhetetlen
#11 Az ML-rendszer szoftverfüggőségeinek kihasználása
Leírás
Ebben a támadásban a támadó NEM manipulálja az algoritmusokat. Ehelyett kihasználja a szoftveres biztonsági réseket, például a puffer túlcsordulását vagy a helyek közötti szkriptelést[1]. Az AI/ML alatti szoftverrétegeket még mindig könnyebb feltörni, mint közvetlenül támadni a tanulási réteget, ezért a biztonsági fejlesztési életciklusban részletesen részletezett hagyományos biztonsági fenyegetéscsökkentési eljárások elengedhetetlenek.
Hagyományos párhuzamok
Sérült nyílt forráskódú szoftverfüggőség
Webkiszolgáló biztonsági rése (XSS, CSRF, API-bemenet érvényesítési hibája)
Enyhítő intézkedések
Dolgozzon együtt a biztonsági csapattal, hogy kövesse az alkalmazható biztonsági fejlesztési életciklus és operatív biztonsági garancia legjobb gyakorlatokat.
Súlyosság
Változó; A hagyományos szoftveres biztonsági rés típusától függően akár kritikus fontosságú is lehet.
Bibliográfia
[1] Hibamódok a gépi tanulásban, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen és Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team
[3] Az ellenséges példák a mélytanulásban: Jellemzés és eltérés, Wei és társai, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-leaks: Modell- és adatfüggetlen tagsági következtetési támadások és védekezések gépi tanulási modelleken, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha és T. Ristenpart: "Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures", a 2015-ös ACM SIGSAC Számítógép és Kommunikációs Biztonság (CCS) konferencia előadásai között.
[6] Nicolas Papernot és Patrick McDaniel - Ellenséges példák a gépi tanulásban AIWTB 2017
[7] Machine Learning-modellek ellopása előrejelzési API-kkal, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell Egyetem; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] Az átvihető ellenpéldák tere, Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh és Patrick McDaniel
[9] A tagsági következtetések megértése a Well-Generalized tanulási modelleken Yunhui Long1, Vincent Bindschaedler1, Lei Wang2, Diyue Bu2, Xiaofeng Wang2, Haixu Tang2, Carl A. Gunter1 és Kai Chen3,4
[10] Simon-Gabriel et al., A neurális hálózatok adversariális sebezhetősége növekszik a bemeneti dimenzióval, ArXiv 2018;
[11] Lyu et al., Egy egységes gradiens regulációs család az ellenpéldákhoz, ICDM 2015
[12] Vad minták: Tíz évvel az Adversarial Machine Learning felemelkedése után – NeCS 2019 Battista Biggioa, Fabio Roli
[13] Ellenségesen Robusztus Malware-Észlelés Monoton Osztályozás Felhasználásával, Inigo Incer et al.
Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto és Fabio Roli. Bagging osztályozók használata mérgezéses támadások elleni küzdelemhez az ellentétes osztályozási feladatokban.
[15] Továbbfejlesztett védelmi mechanizmus negatív hatások ellen Hongjiang Li és Patrick P.K. Chan
[16] Adler. A biometrikus titkosítási rendszerek biztonsági rései. 5. Nemzeti Konferencia AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Az arc-ellenőrzési rendszerek sebezhetőségéről a hegymászó támadások ellen. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Funkcióbeszorítás: Támadó példák észlelése a mély neurális hálózatokban. 2018- os hálózati és elosztott rendszerbiztonsági szimpózium. Február 18-21.
[19] Az adversarial robusztusság megerősítése az adversarial training által kiváltott modellbizalommal – Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Az adversarial-példák észlelésének attribútumalapú okozati elemzése, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robusztus lineáris regresszió a betanítási adatmérgezés ellen – Chang Liu et al.
[22] Zajszűrés az ellenálló képesség javítása érdekében, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Tanúsított védelmek az adverszális példák ellen – Aditi Raghunathan, Jacob Steinhardt, Percy Liang