Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() SQL Server Linux rendszeren
SQL Server Linux rendszeren
Ez a cikk a Linux-alapú SQL Server-telepítések rendelkezésre állási csoportjainak (AG-k) jellemzőit ismerteti. Emellett a Linux- és a Windows Server feladatátvevő fürtön (WSFC) alapuló AG-k közötti különbségeket is ismerteti. Az AG-k alapjaiért tekintse meg az Always On rendelkezésre állási csoportot , mivel a WSFC kivételével Windowson és Linuxon is ugyanúgy működnek.
Megjegyzés:
A Windows Server Feladatátvételi Fürtszolgáltatást (WSFC) nem használó rendelkezésre állási csoportok, például az olvasási skálájú rendelkezésre állási csoportok vagy Linuxon futó rendelkezésre állási csoportok esetében a rendelkezésre állási csoportok DMV-iben a fürtcsoportokkal kapcsolatos oszlopok egy belső alapértelmezett fürt adatait jeleníthetik meg. Ezek az oszlopok csak belső használatra használhatók, és figyelmen kívül hagyhatók.
Magas szintű szempontból a linuxos SQL Server rendelkezésre állási csoportjai ugyanazok, mint a WSFC-alapú implementációkban. Ez azt jelenti, hogy minden korlátozás és funkció azonos, néhány kivétellel. A fő különbségek a következők:
- A Microsoft Distributed Transaction Coordinator (DTC) linuxos környezetben támogatott, kezdve az SQL Server 2017 CU 16-tal. A DTC azonban még nem támogatott a linuxos rendelkezésre állási csoportokban. Ha az alkalmazások elosztott tranzakciók használatát igénylik, és AG-ra van szükségük, telepítse az SQL Servert Windows rendszeren.
- A magas rendelkezésre állást igénylő Linux-alapú üzemelő példányok wSFC helyett a Pacemakert használják a fürtözéshez.
- A Windowson futó AG-k legtöbb konfigurációjától eltérően a Munkacsoportfürt forgatókönyv kivételével a Pacemaker soha nem igényel Active Directory Domain Servicest (AD DS).
- Az AG egyik csomópontról a másikra való meghiúsulása a Linux és a Windows között eltérő.
- Bizonyos beállítások, például
required_synchronized_secondaries_to_commitcsak a Pacemakeren keresztül módosíthatók Linuxon, míg egy WSFC-alapú telepítés Transact-SQL-t használ.
Replikák és fürtcsomópontok száma
Az SQL Server Standard kiadásban az AG két teljes replikával rendelkezhet: egy elsődleges és egy másodlagos replikával, amelyek csak rendelkezésre állási célokra használhatók. Nem használható máshoz, például olvasható lekérdezésekhez. Az SQL Server Enterprise kiadásban egy AG legfeljebb kilenc replikával rendelkezhet: egy elsődleges és legfeljebb nyolc másodpéldányt, amelyek közül legfeljebb három (az elsődlegeset is beleértve) szinkronizálható. Ha mögöttes fürtöt használ, a Corosync használata esetén legfeljebb 16 csomópont lehet összesen. A rendelkezésre állási csoportok az SQL Server Enterprise kiadással rendelkező 16 csomópont közül legfeljebb kilencre, az SQL Server Standard kiadással pedig kettőre terjedhetnek ki.
Egy olyan kétreplika-konfiguráció, amely megköveteli az egyik replika automatikus feladatátvételének képességét, megköveteli egy csak konfigurációs replikának a használatát, ahogy az a Csak konfigurációs replika és kvórum részben le van írva. A csak konfigurációs replikák az SQL Server 2017 (14.x) 1. kumulatív frissítésében (CU 1) vezették be, ezért ehhez a konfigurációhoz a telepített minimális verzió ennek kell lennie.
Ha a Pacemakert használja, megfelelően kell konfigurálni, hogy működőképes maradjon. Ez azt jelenti, hogy a sikertelen csomópont kvórumát és kerítését a Pacemaker szempontjából megfelelően kell implementálni, az SQL Server követelményein túlmenően, például csak konfigurációs replika esetében.
Az olvasható másodlagos replikák csak az SQL Server Enterprise kiadásban támogatottak.
Fürttípus és feladatátvételi mód
Az SQL Server 2017 (14.x) újdonsága az elérhetőségi csoportok (Availability Groups) fürttípusának bevezetése. Linux esetén két érvényes érték van: Külső és Nincs. A külső klaszter típus azt jelenti, hogy a Pacemaker az AG keretrendszerében működik. A külső fürttípus használata megköveteli, hogy a feladatátvételi módot is Külső-re legyen beállítva, ami szintén új az SQL Server 2017 (14.x) verzióban. Az automatikus feladatátvétel támogatott, de a WSFC-vel ellentétben a feladatátvételi mód külsőre van állítva, nem pedig automatikusra a Pacemaker használatakor. Az AG Pacemaker része, a WSFC-vel ellentétben, az AG konfigurálása után jön létre.
Az, hogy a fürttípus "Nincs", azt jelenti, hogy nincs szükség Pacemakerre, és az AG sem használja azt. Még akkor is, ha egy Pacemakerrel konfigurált kiszolgálón egy AG None fürttípussal van konfigurálva, a Pacemaker nem észleli vagy kezeli ezt az AG-t. A Nincs fürttípus csak az elsődlegesről a másodlagos replikára történő manuális feladatátvételt támogatja. A "None" konfigurációval létrehozott AG-k elsősorban a frissítésekre és az olvasási felskálázásra összpontosítanak. Bár olyan forgatókönyvekben is működhetnek, mint a katasztrófa utáni helyreállítás vagy a helyi rendelkezésre állás, ahol nem szükséges automatikus feladatátvétel, nem ajánlott. A figyelő története is összetettebb Pacemaker nélkül.
A fürttípus tárolása az SQL Server dinamikus felügyeleti nézetében (DMV) sys.availability_groupstörténik, az oszlopokban cluster_type és cluster_type_desca .
szinkronizált másodlagosok szükségesek a végrehajtáshoz
Újdonság az SQL Server 2017 (14.x) verzióban az AG-k által használt beállítás required_synchronized_secondaries_to_commit. Ez tájékoztatja az AG-t a másodlagos replikák számáról, amelyeknek szinkronban kell lenniük az elsődlegessel. Ez lehetővé teszi az automatikus feladatátvételt (csak akkor, ha a Pacemakerrel integrálva van egy külső fürttípussal), és szabályozza az olyan dolgok viselkedését, mint az elsődleges rendelkezésre állása, ha a másodlagos replikák megfelelő száma online vagy offline. Ha többet szeretne megtudni ennek működéséről, olvassa el a magas rendelkezésre állás és az adatvédelem a rendelkezésre állási csoportok konfigurációihoz című témakört. Az required_synchronized_secondaries_to_commit érték alapértelmezés szerint be van állítva, és a Pacemaker/ SQL Server tartja karban. Ezt az értéket manuálisan is felülbírálhatja.
Az required_synchronized_secondaries_to_commit és az új sorszám kombinációja (ami a sys.availability_groups tárolva van) tájékoztatja a Pacemakert és az SQL Servert arról, hogy például automatikus átkapcsolás történhet. Ebben az esetben a másodlagos replika sorszáma megegyezik az elsődlegesével, ami azt jelenti, hogy naprakész az összes legújabb konfigurációs információval.
Három érték állítható be required_synchronized_secondaries_to_commit: 0, 1 vagy 2. Szabályozzák a replika elérhetetlenné válásának viselkedését. A számok az elsődleges replikával szinkronizálandó másodlagos replikák számának felelnek meg. Linux alatt a viselkedés a következő:
| Beállítás | Leírás |
|---|---|
0 |
A másodlagos replikáknak nem kell szinkronizált állapotban lenniük az elsődlegessel. Ha azonban a másodfokok nincsenek szinkronizálva, nincs automatikus feladatátvétel. |
1 |
Egy másodlagos replikának szinkronizált állapotban kell lennie az elsődlegessel; automatikus feladatátvétel lehetséges. Az elsődleges adatbázis nem érhető el, amíg el nem érhető egy másodlagos szinkron replika. |
2 |
A három vagy több csomópont AG-konfigurációban lévő másodlagos replikákat szinkronizálni kell az elsődlegessel; automatikus feladatátvétel lehetséges. |
required_synchronized_secondaries_to_commit nem csak a szinkron replikákkal végzett feladatátvételek viselkedését szabályozza, hanem az adatvesztést is. Az 1 vagy 2 érték esetén a másodlagos replikát mindig szinkronizálni kell az adatredundancia biztosítása érdekében. Ez azt jelenti, hogy nincs adatvesztés.
Az érték required_synchronized_secondaries_to_commitmódosításához használja az alábbi szintaxist:
Megjegyzés:
Az érték módosítása miatt az erőforrás újraindul, ami rövid kimaradást jelent. Ezt csak úgy kerülheti el, ha ideiglenesen úgy állítja be az erőforrást, hogy ne a fürt kezelje.
Red Hat Enterprise Linux (RHEL) és Ubuntu
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<value>
SUSE Linux Enterprise Server (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
Megjegyzés:
Az SQL Server 2025 -től (17.x) kezdődően a SUSE Linux Enterprise Server (SLES) nem támogatott.
Ebben a példában <AGResourceName> az AG-hez konfigurált erőforrás neve, és <value> 0, 1 vagy 2. Ha vissza szeretné állítani a paramétert kezelő Pacemaker alapértelmezett értékére, hajtsa végre ugyanazt az utasítást érték nélkül.
Az AG automatikus feladatátvétele a következő feltételek teljesülése esetén lehetséges:
- Az elsődleges és a másodlagos replika szinkron adatáthelyezésre van beállítva.
- A másodlagos állapota szinkronizált (nem szinkronizáló), ami azt jelenti, hogy a kettő azonos adatpontnál tartanak.
- A fürt típusa Külsőre van állítva. Az automatikus feladatátvétel nem lehetséges a Nincs fürttípussal.
- Az
sequence_numberelsődlegessé váló másodlagos replika sorszáma a legmagasabb – vagyis a másodlagos replikasequence_numbermegegyezik az eredeti elsődleges replikaéval.
Ha ezek a feltételek teljesülnek, és az elsődleges replikát üzemeltető kiszolgáló meghibásodik, az AG egy szinkron replikára módosítja a tulajdonjogot. A szinkron replikák viselkedését (amelyek közül három lehet összesen: egy elsődleges és két másodlagos replika) tovább szabályozható required_synchronized_secondaries_to_commit. Ez windowsos és linuxos AG-kkel is működik, de másképpen van konfigurálva. A Linux rendszeren az értéket a fürt automatikusan konfigurálja az AG-erőforráson belül.
Csak konfigurációs replika és kvórum
A Pacemakerrel való kvórumkezelési korlátok javítására egy kizárólag konfigurációs célú replika került bevezetésre, különösen akkor, amikor a sikertelen csomópont kerítésének kezelése szükséges. Két csomópontos konfiguráció használata nem megfelelő egy AG számára. Az FCI esetében a Pacemaker által biztosított kvórummechanizmusok rendben lehetnek, mivel az FCI feladatátvételi döntőbíráskodása a fürtrétegen történik. Egy AG esetében a Linux alatt történő választottbírósági eljárás az SQL Serveren történik, ahol az összes metaadat tárolása történik. Itt lép be a képbe a csak konfigurációs replika.
Minden más nélkül egy harmadik csomópontra és legalább egy szinkronizált replikára lenne szükség. A csak konfigurációs replika az AG-konfigurációt az master adatbázisban tárolja, ugyanúgy, mint az AG-konfiguráció többi replikáját. A csak konfigurációs replika nem rendelkezik az AG-ben részt vevő felhasználói adatbázisokkal. A konfigurációs adatokat a rendszer szinkron módon küldi el az elsődlegestől. Ezeket a konfigurációs adatokat ezután a rendszer a feladatátvétel során használja fel, függetlenül attól, hogy automatikusak vagy manuálisak.
Ahhoz, hogy egy AG fenntartsa a kvórumot, és engedélyezze az automatikus feladatátvételt külső fürttípussal, a következőkkel kell rendelkeznie:
- Három szinkron replikával rendelkezik (csak SQL Server Enterprise-kiadás); vagy
- Két replikát (elsődleges és másodlagos) és egy csak konfigurációs replikát tartalmaz.
Manuális feladatátvétel történhet, akár külső, akár nincs fürttípust alkalmazó AG-konfigurációk esetén. Bár a csak konfigurációs replikák olyan AG-vel konfigurálhatók, amelyek fürttípusa Nincs, nem ajánlott, mivel bonyolítja az üzembe helyezést. Ezen konfigurációk esetében manuálisan módosítsa required_synchronized_secondaries_to_commit úgy, hogy legalább 1 értékű legyen, hogy legalább egy szinkronizált replika legyen.
A csak konfigurációs replika az SQL Server bármely kiadásában üzemeltethető, beleértve az SQL Server Expresst is. Ez minimalizálja a licencelési költségeket, és biztosítja, hogy működjön az AG-kkel az SQL Server Standard kiadásban. Ez azt jelenti, hogy a harmadik szükséges kiszolgálónak csak meg kell felelnie az SQL Server minimális specifikációjának, mivel nem fogad felhasználói tranzakciós forgalmat az AG-hez.
Ha csak konfigurációs replikát használ, az alábbi viselkedéssel rendelkezik:
Alapértelmezés szerint
required_synchronized_secondaries_to_commit0 értékre van állítva. Ez manuálisan módosítható 1-re, ha szükséges.Ha az elsődleges nem működik, és
required_synchronized_secondaries_to_commit0, a másodlagos replika lesz az új elsődleges, és elérhető lesz az olvasáshoz és az íráshoz is. Ha az érték 1, automatikus feladatátvétel történik, de nem fogad el új tranzakciókat, amíg a másik replika nincs online állapotban.Ha egy másodlagos replika meghibásodik, és
required_synchronized_secondaries_to_commit0, az elsődleges replika továbbra is fogadja a tranzakciókat, de ha ebben az esetben az elsődleges replika meghibásodik, nincs védelem az adatok számára, és nem lehetséges a feladatátvétel (sem manuális, sem automatikus), mivel nincs elérhető másodlagos replika.Ha a csak konfigurációs replika meghibásodik, az AG normálisan működik, de nem lehetséges az automatikus feladatátvétel.
Ha a szinkron másodlagos replika és a csak konfigurációs replika is meghibásodik, az elsődleges nem fogadhat tranzakciókat, és nincs hova átváltson.
Több rendelkezésre állási csoport
Pacemaker klaszterenként vagy kiszolgáló készletenként több AG hozható létre. Az egyetlen korlátozás a rendszererőforrások. Az AG tulajdonjogát az elsődleges szereplő mutatja. A különböző AG-k különböző csomópontok tulajdonában lehetnek; nem mindegyiknek ugyanazon a csomóponton kell futnia.
Adatbázisok meghajtó- és mappahelye
A Windows-alapú AG-khez hasonlóan az AG-ben részt vevő felhasználói adatbázisok meghajtó- és mappastruktúrájának azonosnak kell lennie. Ha például a felhasználói adatbázisok az A kiszolgálón találhatók /var/opt/mssql/userdata , akkor a B kiszolgálón ugyanaz a mappa kell, hogy legyen. Ez alól az egyetlen kivételt a Windows-alapú rendelkezésreállási csoportokkal és replikákkal való együttműködés című szakasz ismerteti.
A hallgató Linux alatt
A figyelő nem kötelező funkció egy AG-hez. Egyetlen belépési pontot biztosít az összes kapcsolathoz (olvasási/írási műveletek az elsődleges replikára és/vagy írásvédett másodlagos replikákra), így az alkalmazásoknak és a végfelhasználóknak nem kell tudniuk, hogy melyik kiszolgáló üzemelteti az adatokat. A WSFC-ben ez egy hálózati néverőforrás és egy IP-erőforrás kombinációja, amely ezután regisztrálva van az AD DS-ben (ha szükséges) és a DNS-ben. Ezt az absztrakciót az AG-erőforrással együtt biztosítja. A figyelővel kapcsolatos további információkért lásd: Csatlakozás Always On rendelkezésre állási csoport figyelőhöz.
A Linux alatt futó figyelő másképpen van konfigurálva, de a funkciója ugyanaz. A Pacemakerben nincs hálózatinév-erőforrás fogalma, és az AD DS-ben létrehozott objektum sem; A Pacemakerben csak egy IP-címerőforrás van létrehozva, amely bármelyik csomóponton futtatható. Olyan bejegyzést kell létrehozni, amely az IP-erőforráshoz van társítva a figyelő számára a DNS-ben, egy "barátságos névvel". A figyelő IP-erőforrása csak azon a kiszolgálón aktív, amely az adott rendelkezésre állási csoport elsődleges replikáját üzemelteti.
Ha Pacemakert használ, és létrehoz egy IP-címerőforrást, amely a figyelőhöz van társítva, akkor rövid kimaradás következik be, mivel az IP-cím leáll az egyik kiszolgálón, és elindul a másikon, függetlenül attól, hogy az átvétel automatikus vagy manuális. Bár ez absztrakciót biztosít egyetlen név és IP-cím kombinációján keresztül, nem maszkolja a kimaradásokat. Az alkalmazásnak képesnek kell lennie kezelni a leválasztást úgy, hogy valamilyen funkcióval rendelkezik az észleléshez és az újracsatlakozáshoz.
A DNS-név és az IP-cím kombinációja azonban még mindig nem elegendő a WSFC-figyelő által biztosított összes funkció biztosításához, például a másodlagos replikák írásvédett útválasztásához. Az elérhetőségi csoport (AG) konfigurálásakor a figyelőt továbbra is konfigurálni kell az SQL Serveren. Ez látható a varázslóban és a Transact-SQL szintaxisban. Ez kétféleképpen konfigurálható úgy, hogy ugyanúgy működjön, mint a Windows esetén:
- Külső fürttípusú AG esetében az SQL Serverben létrehozott figyelőhöz tartozó IP-címnek meg kell egyeznie a Pacemakerben létrehozott erőforrás IP-címével.
- A fürttípus nélküli AG esetén használja az elsődleges replikához társított IP-címet.
A megadott IP-címhez társított példány lesz a koordinátor az alkalmazásokból érkező csak olvasható útválasztási kérelmek esetében.
Együttműködés Windows-alapú rendelkezésre állási csoportokkal és replikákkal
Egy olyan AG, amely külső vagy WSFC típusú fürttípussal rendelkezik, nem rendelkezhet replikáival platformfüggetlenként. Ez igaz, akár SQL Server Standard kiadásról, akár SQL Server Enterprise kiadásról van szó. Ez azt jelenti, hogy egy hagyományos, mögöttes fürttel rendelkező AG-konfigurációban az egyik replika nem lehet WSFC-n, a másik pedig Linuxon a Pacemakerrel.
A NONE típusú fürttípusú AG-k replikái az operációs rendszer határain átnyúlóak lehetnek, így linuxos és Windows-alapú replikák is lehetnek ugyanabban az AG-ben. Itt látható egy példa, ahol az elsődleges replika Windows-alapú, míg a másodlagos az egyik Linux-disztribúción található.
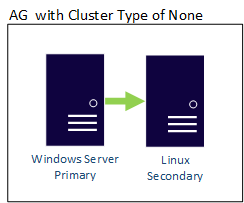
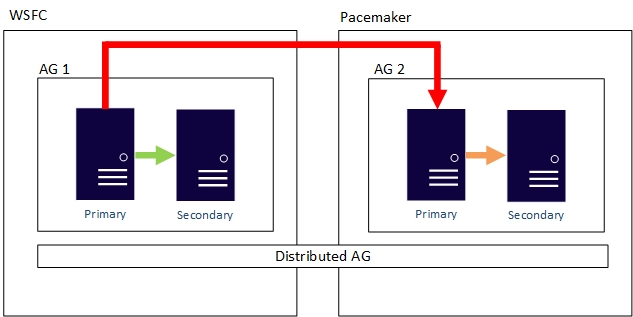
Az elosztott AG az operációs rendszer határait is átlépheti. A mögöttes rendelkezésre állási csoportokat (AG) a konfigurálásukra vonatkozó szabályok kötik, például egy külső, kizárólag Linux-alapú konfigurációval rendelkező AG-t csak így lehet beállítani, de az ahhoz csatlakoztatott AG-t lehet WSFC-vel is konfigurálni. Vegye figyelembe a következő példát:
Kapcsolódó tartalom
- Az SQL Server rendelkezésre állási csoportjának konfigurálása magas rendelkezésre álláshoz Linuxon
- SQL Server rendelkezésre állási csoport konfigurálása olvasási skálázáshoz Linuxon
- Pacemaker-fürt konfigurálása SQL Server rendelkezésre állási csoportokhoz
- Sql Server Always On rendelkezésre állási csoport konfigurálása Windowson és Linuxon (platformfüggetlen)