Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() Sql Server 2017 (14.x) és újabb verziók
Sql Server 2017 (14.x) és újabb verziók ![]() Felügyelt Azure SQL-példány
Felügyelt Azure SQL-példány
A négyrészes oktatóanyag-sorozat harmadik részében egy K-Means modellt fog létrehozni a Pythonban a fürtözés végrehajtásához. A sorozat következő részében ezt a modellt egy SQL Server Machine Learning Servicest vagy Big Data-fürtöket tartalmazó adatbázisban fogja üzembe helyezni.
A négyrészes oktatóanyag-sorozat harmadik részében egy K-Means modellt fog létrehozni a Pythonban a fürtözés végrehajtásához. A sorozat következő részében ezt a modellt egy SQL Server Machine Learning Services-alapú adatbázisban fogja üzembe helyezni.
A négyrészes oktatóanyag-sorozat harmadik részében egy K-Means modellt fog létrehozni a Pythonban a fürtözés végrehajtásához. A sorozat következő részében ezt a modellt egy adatbázisban fogja üzembe helyezni az Azure SQL Managed Instance Machine Learning Services szolgáltatással.
Ebben a cikkben megtudhatja, hogyan:
- A K-Means algoritmus fürtöinek számának meghatározása
- Fürtözés végrehajtása
- Az eredmények elemzése
Az első részben telepítette az előfeltételeket, és visszaállította a mintaadatbázist.
A második részben megtanulta, hogyan készítheti elő az adatokat egy adatbázisból a fürtözés végrehajtására.
A negyedik részben megtanulhatja, hogyan hozhat létre tárolt eljárást egy olyan adatbázisban, amely új adatok alapján képes fürtözést végezni a Pythonban.
Előfeltételek
- Az oktatóanyag harmadik része feltételezi, hogy teljesítette az első rész előfeltételeit, és elvégezte a második rész lépéseit.
Fürtök számának meghatározása
Az ügyféladatok fürtözéséhez a K-Means fürtözési algoritmust fogja használni, amely az adatok csoportosításának egyik legegyszerűbb és legismertebb módja. A K-középről a K-means klaszterezési algoritmus teljes útmutatójában olvashat bővebben.
Az algoritmus két bemenetet fogad el: magát az adatokat, és egy előre definiált "k" számot, amely a létrehozandó fürtök számát jelöli. A kimenet k fürtök, a bemeneti adatok a fürtök között particionáltak.
A K-eszközök célja, hogy az elemeket k fürtökbe csoportosítsa úgy, hogy az ugyanabban a fürtben lévő összes elem ugyanolyan hasonló legyen egymáshoz, és amennyire csak lehetséges, különbözjön a többi fürt elemeitől.
Az algoritmus által használandó fürtök számának meghatározásához használja a csoportokon belüli négyzetösszeget a kinyert fürtök száma alapján. A használni kívánt fürtök száma a diagram kanyarjában vagy "könyökében" van.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
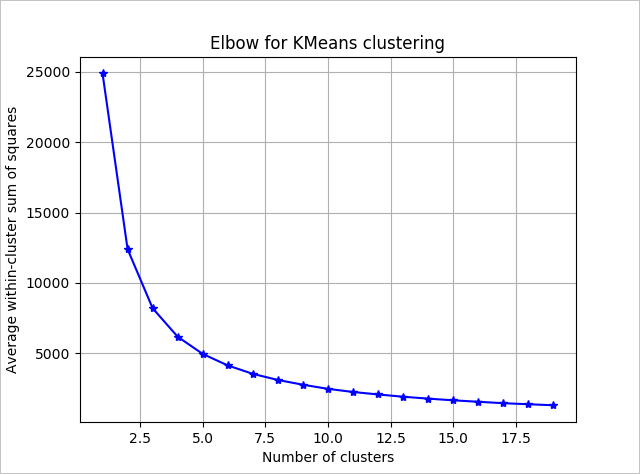
A gráf alapján úgy tűnik, hogy a k = 4 jó érték lenne. Ez a k érték négy fürtbe csoportosítja az ügyfeleket.
Fürtözés végrehajtása
A következő Python-szkriptben a Sklearn-csomag KMeans függvényét fogja használni.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
Az eredmények elemzése
Most, hogy a K-Means használatával végzett fürtözést, a következő lépés az eredmény elemzése, és annak megtekintése, hogy talál-e hasznosítható információt.
Tekintse meg az előző szkriptből kinyomtatott fürtözési középértékeket és fürtméreteket.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
A négy fürtátlag a első részben meghatározott változók használatával van megadva:
- orderRatio = visszatérési rendelés aránya (a részben vagy teljesen visszaadott rendelések teljes száma a rendelések teljes számával szemben)
- itemsRatio = return item ratio (a visszaadott elemek teljes száma és a megvásárolt elemek száma)
- monetaryRatio = visszatérési összeg aránya (a visszaadott tételek teljes pénzügyi összege a megvásárolt összeggel szemben)
- frequency = visszatérési gyakoriság
A K-Means használatával végzett adatbányászathoz gyakran további elemzésre van szükség az eredményekről, és további lépésekre van szükség az egyes fürtök jobb megértéséhez, de jó eredményeket adhat. Az alábbiakban néhány módszert talál az eredmények értelmezésére:
- A "Cluster 0" úgy tűnik, hogy egy olyan ügyfelekből álló csoport, amely nem aktív (minden érték nulla).
- A 3-as klaszter tűnik egy csoportnak, amely a hozam viselkedés szempontjából kiemelkedik.
A 0. klaszter olyan ügyfelek csoportja, akik egyértelműen nem aktívak. Talán célozhatja a marketing erőfeszítéseket erre a csoportra, hogy felkeltse a vásárlási érdeklődést. A következő lépésben lekérdezi az adatbázist a 0. fürt ügyfeleinek e-mail-címeiről, hogy marketing e-mailt küldhessen.
Erőforrások tisztítása
Ha nem folytatja ezt az oktatóanyagot, törölje a tpcxbb_1gb adatbázist.
Következő lépések
Az oktatóanyag-sorozat harmadik részében az alábbi lépéseket hajtotta végre:
- A K-Means algoritmus fürtöinek számának meghatározása
- Fürtözés végrehajtása
- Az eredmények elemzése
A létrehozott gépi tanulási modell üzembe helyezéséhez kövesse az oktatóanyag-sorozat negyedik részét: