Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik a következőkre:![]() SQL Server 2016 (13.x) és későbbi verziók
SQL Server 2016 (13.x) és későbbi verziók ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
A lekérdezéseket JSON-dokumentumokra optimalizálhatja standard indexek használatával.
Note
Az SQL Server 2025 -ben (17.x) használhatja a CREATE JSON INDEX (Transact-SQL) funkciót.
Az indexek ugyanúgy működnek a JSON-adatokon varchar/nvarchar vagy a natív json adattípusban.
Az adatbázisindexek javítják a szűrési és rendezési műveletek teljesítményét. Indexek nélkül az SQL Servernek minden adat lekérdezésekor teljes táblázatvizsgálatot kell végeznie.
Note
- általánosan elérhető az Azure SQL Database és az Azure SQL Managed Instance az SQL Server 2025 vagy az Always-up-to-date frissítési szabályzattal.
- előzetes verzióban érhető el az SQL Server 2025 (17.x) és az SQL Database a Fabricben.
JSON-tulajdonságok indexelése számított oszlopok használatával
Ha JSON-adatokat tárol az SQL Serveren, általában a JSON-dokumentumok egy vagy több tulajdonsága szeretné szűrni vagy rendezni a lekérdezési eredményeket.
Example
Ebben a példában tegyük fel, hogy a AdventureWorks.SalesOrderHeader tábla egy Info oszlopot tartalmaz, amely különböző információkat tartalmaz JSON formátumban az értékesítési rendelésekről. Például strukturálatlan adatokat tartalmaz az ügyfélről, az értékesítőről, a szállítási és számlázási címekről stb. A Info oszlop értékeivel szűrheti egy ügyfél értékesítési rendeléseit.
Alapértelmezés szerint a használt oszlop Info nem létezik, az adatbázisban az AdventureWorks alábbi kóddal hozható létre. Az alábbi példák nem vonatkoznak a AdventureWorksLT mintaadatbázisok sorozatára.
IF NOT EXISTS (SELECT *
FROM sys.columns
WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]')
AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader]
ADD [Info] NVARCHAR (MAX) NULL;
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c
ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p
ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Optimalizálandó lekérdezés
Íme egy példa az index használatával optimalizálni kívánt lekérdezés típusára.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell';
Példaindex
Ha fel szeretné gyorsítani a szűrőket vagy ORDER BY záradékokat egy JSON-dokumentumban lévő tulajdonságon, ugyanazokat az indexeket használhatja, amelyeket más oszlopokban már használ. A JSON-dokumentumokban azonban nem közvetlenül referenciatulajdonságokat.
- Először hozzon létre egy "virtuális oszlopot", amely a szűréshez használni kívánt értékeket adja vissza.
- Ezután hozzon létre egy indexet a virtuális oszlopban.
Az alábbi példa létrehoz egy számított oszlopot, amely indexelésre használható. Ezután létrehoz egy indexet az új számított oszlopban. Ez a példa létrehoz egy oszlopot, amely elérhetővé teszi az ügyfél nevét, amelyet a JSON-adatok $.Customer.Name elérési útján tárol.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info, '$.Customer.Name');
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName);
Ez az utasítás a következő figyelmeztetést adja vissza:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
A JSON_VALUE függvény legfeljebb 8000 bájt szöveges értékeket adhat vissza (például nvarchar(4000) típust). Az 1700 bájtnál hosszabb értékek azonban nem indexelhetők. Ha az indexelt számított oszlopban 1700 bájtnál hosszabb értéket próbál meg megadni, az adatmanipulációs nyelv (DML) művelet meghiúsul.
A jobb teljesítmény érdekében próbálja meg egy számított oszlop használatával a legkisebb alkalmazható adattípusba beszűkíteni a kiteendő értéket. Sztringtípusok helyett használjon int és datetime2 típusokat.
További információ a számított oszlopról
A számított oszlop nem tárolódik. A számított oszlopokat csak akkor számítja ki a rendszer, ha az indexet újra kell alakítani. Nem foglal el további helyet a táblázatban.
Fontos, hogy a számított oszlopot ugyanazzal a kifejezéssel hozza létre, amelyet a lekérdezésekben használni szeretne – ebben a példában a kifejezés JSON_VALUE(Info, '$.Customer.Name').
Nem kell újraírnia a lekérdezéseket. Ha a JSON_VALUE függvénnyel használ kifejezéseket az előző példa lekérdezésben látható módon, az SQL Server azt látja, hogy ugyanazzal a kifejezéssel egyenértékű számított oszlop található, és lehetőség szerint indexet alkalmaz.
Végrehajtási terv ehhez a példához
Ebben a példában a lekérdezés végrehajtási terve látható.
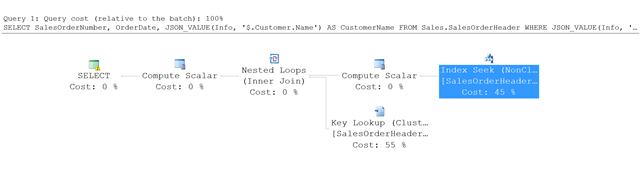
A teljes táblavizsgálat helyett az SQL Server egy indexkeresést használ a nemclustered indexbe, és megkeresi a megadott feltételeknek megfelelő sorokat. Ezután a SalesOrderHeader tábla kulcskeresésével beolvassa a lekérdezésben hivatkozott többi oszlopot – ebben a példában SalesOrderNumber és OrderDate.
Az index további optimalizálása a belefoglalt oszlopokkal
Ha kötelező oszlopokat ad hozzá az indexhez, elkerülheti a további kereséseket a táblában. Ezeket az oszlopokat normál oszlopként is hozzáadhatja az alábbi példában látható módon, amely kiterjeszti az előző CREATE INDEX példát.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber, OrderDate);
Ebben az esetben az SQL Servernek nem kell további adatokat olvasnia a SalesOrderHeader táblából, mert minden szükséges adatot tartalmaz a nem rendezett JSON-index. Ez az indextípus jó módszer a JSON- és oszlopadatok lekérdezésekben való kombinálására, valamint a számítási feladatok optimális indexeinek létrehozására.
A JSON-indexek rendezésérzékeny indexek
A JSON-adatokon keresztüli indexek fontos jellemzője, hogy az indexek rendezésérzékenyek. A számított oszlop létrehozásakor használt JSON_VALUE függvény eredménye egy szöveges érték, amely örökli a rendezést a bemeneti kifejezéstől. Ezért az index értékei a forrásoszlopokban meghatározott rendezési szabályok alapján vannak rendezve.
Annak bemutatásához, hogy az indexek rendezésérzékenyek, az alábbi példa egy egyszerű gyűjteménytáblát hoz létre elsődleges kulccsal és JSON-tartalommal.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR (MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON] CHECK (ISJSON(json) > 0)
);
Az előző parancs a szerb cirill betűs rendezést adja meg a json oszlophoz. Az alábbi példa kitölti a táblát, és létrehoz egy indexet a névtulajdonságon.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}');
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json, '$.name');
CREATE INDEX idx_name
ON JsonCollection(vName);
Az előző parancsok létrehoznak egy szabványos indexet a számított vNameoszlopon, amely a JSON $.name tulajdonság értékét jelöli. A szerb cirill kódlapon a betűk sorrendje А, Б, В, Г, Д, Ђ, Еstb. Az index elemeinek sorrendje megfelel a szerb cirill szabályoknak, mert a JSON_VALUE függvény eredménye örökli a rendezést a forrásoszlopból. Az alábbi példa lekérdezi ezt a gyűjteményt, és név szerint rendezi az eredményeket.
SELECT JSON_VALUE(json, '$.name'),
*
FROM JsonCollection
ORDER BY JSON_VALUE(json, '$.name');
Ha megtekinti a tényleges végrehajtási tervet, láthatja, hogy a nem klaszterezett index rendezett értékeit használja.

Bár a lekérdezés rendelkezik ORDER BY záradékkal, a végrehajtási terv nem használ Rendezési operátort. A JSON-index már a szerb cirill szabályok szerint van rendezve. Ezért az SQL Server használhatja a nemclustered indexet, ahol az eredmények már rendezve vannak.
Ha azonban módosítja a ORDER BY kifejezés rendezési tervét – például ha COLLATE French_100_CI_AS_SC a JSON_VALUE függvény után adja hozzá – egy másik lekérdezés-végrehajtási tervet kap.

Mivel az index értékeinek sorrendje nem felel meg a francia rendezési szabályoknak, az SQL Server nem tudja az indexet használni az eredmények sorrendjére. Ezért hozzáad egy rendezési operátort, amely francia rendezési szabályokkal rendezi az eredményeket.
Microsoft-videók
A beépített JSON-támogatás vizuális bemutatásához tekintse meg az alábbi videót: