Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Az SQL Serverben és az Azure SQL Database-ben a teljes szöveges kereséssel a felhasználók és alkalmazások teljes szöveges lekérdezéseket futtathatnak az SQL Server-táblákban lévő karakteres adatokon.
Fontos
Az SQL Server 2025 (17.x) és újabb verzióiban kompatibilitástörő változások történtek a Full-Text Search funkcióban. További információkért, lásd: Az SQL Server 2025 adatbázismotor-funkcióinak kompatibilitástörő változásai.
Alapműveletek
Ez a cikk áttekintést nyújt a Full-Text Keresésről, és ismerteti annak összetevőit és architektúráját. Ha szeretné azonnal megkezdeni az első lépéseket, itt találja az alapvető feladatokat.
- Első lépések a Full-Text Kereséshez
- Full-Text katalógusok létrehozása és kezelése
- Teljes szöveges indexek létrehozása és kezelése
- Feltölt Full-Text indexeket
- Lekérdezés Full-Text Keresés
Full-Text Keresés az SQL Server adatbázismotor választható összetevője. Ha nem a Full-Text Keresés lehetőséget választja az SQL Server telepítésekor, a hozzáadáshoz futtassa újra az SQL Server telepítőjét.
Áttekintés
A teljes szöveges indexek egy vagy több karakteralapú oszlopot tartalmaznak egy táblában. Ezek az oszlopok a következő adattípusok bármelyikével rendelkezhetnek: char, varchar, nchar, nvarchar, text, ntext, image, xml vagy varbinary(max) és FILESTREAM. Minden teljes szöveges index egy vagy több oszlopot indexel a táblázatból, és minden oszlop egy adott nyelvet használhat.
A teljes szöveges lekérdezések nyelvi keresést végeznek a szöveges adatokon teljes szöveges indexekben úgy, hogy egy adott nyelv szabályain ( például angol vagy japán) alapuló szavakon és kifejezéseken működnek. A teljes szöveges lekérdezések tartalmazhatnak egyszerű szavakat és kifejezéseket, illetve egy szó vagy kifejezés több formáját is. A teljes szöveges lekérdezés minden olyan dokumentumot visszaad, amely legalább egy egyezést (más néven találatot) tartalmaz. Egyezés akkor fordul elő, ha egy céldokumentum tartalmazza a teljes szöveges lekérdezésben megadott összes kifejezést, és megfelel minden más keresési feltételnek, például az egyező kifejezések közötti távolságnak.
Full-Text Keresési lekérdezések
Miután az oszlopokat hozzáadta egy teljes szöveges indexhez, a felhasználók és az alkalmazások teljes szöveges lekérdezéseket futtathatnak az oszlopok szövegén. Ezek a lekérdezések a következő feltételek bármelyikére kereshetnek:
- Egy vagy több konkrét szó vagy kifejezés (egyszerű kifejezés)
- Egy szó vagy kifejezés, amelyben a szavak megadott szöveggel kezdődnek (előtag kifejezés)
- Adott szó inflektív formái (generációs kifejezés)
- Egy másik szóhoz vagy kifejezéshez közeli szó vagy kifejezés (közelségi kifejezés)
- Egy adott szó szinonimái (szinonimaszótár)
- Súlyozott értékeket használó szavak vagy kifejezések (súlyozott kifejezés)
A teljes szöveges lekérdezések nem érzékenyek a kis- és nagybetűkre. Például a Aluminum vagy a aluminum keresése ugyanazokat az eredményeket adja vissza.
A teljes szöveges lekérdezések Transact-SQL predikátumok (CONTAINS és FREETEXT) és függvények (CONTAINSTABLE és FREETEXTTABLE) kis halmazát használják. Az adott üzleti forgatókönyv keresési céljai azonban befolyásolják a teljes szöveges lekérdezések szerkezetét. Például:
Termék keresése e-kereskedelmi webhelyen:
SELECT product_id FROM products WHERE CONTAINS ((product_description), '"Snap Happy 100EZ" OR FORMSOF(THESAURUS,"Snap Happy") OR "100EZ"') AND product_cost < 200;Toborzási forgatókönyv– olyan állásjelöltek keresése, akik tapasztalattal rendelkeznek az SQL Serverrel való munkában:
SELECT candidate_name, SSN FROM candidates WHERE CONTAINS ((candidate_resume), '"SQL Server"') AND candidate_division = 'DBA';
További információ: Lekérdezés Full-Text kereséssel.
Full-Text Keresési lekérdezések összehasonlítása a LIKE-predikátumhoz
A teljes szöveges kereséssel ellentétben a LIKE Transact-SQL predikátum csak karaktermintákon működik. Emellett a predikátum nem használható LIKE formázott bináris adatok lekérdezésére. Emellett a LIKE nagy mennyiségű strukturálatlan szöveges adat lekérdezése sokkal lassabb, mint az azonos adatokon végzett teljes szöveges lekérdezés. A LIKE több millió sornyi szöveges adat lekérdezésének visszaadása perceket vehet igénybe, míg a teljes szöveges lekérdezések csak másodperceket vagy kevesebbet vehetnek igénybe ugyanazon adatokhoz a visszaadott sorok számától függően.
Full-Text Keresési architektúra
A teljes szöveges keresési architektúra a következő folyamatokból áll:
Az SQL Server folyamata (
sqlservr.exe).A szűrő daemon gazdagép folyamata (
fdhost.exe).Biztonsági okokból a szűrőket külön folyamatok, úgynevezett szűrődémon-gazdagépek töltik be. A
fdhost.exefolyamatokat egy FDHOST-indítószolgáltatás (MSSQLFDLauncher) hozza létre, és az FDHOST indítószolgáltatás-fiók biztonsági hitelesítő adatai alatt futnak. Ezért az FDHOST indítószolgáltatásnak teljes szöveges indexeléshez és teljes szöveges lekérdezéshez kell futnia. A szolgáltatáshoz tartozó szolgáltatásfiók beállításáról további információt a Teljes szöveges szűrő démonindító szolgáltatásfiókjának beállítása című témakörben talál.
Ez a két folyamat tartalmazza a teljes szöveges keresési architektúra összetevőit. Ezeket az összetevőket és azok kapcsolatait az alábbi ábra foglalja össze. Az összetevőket az ábra után ismertetjük.
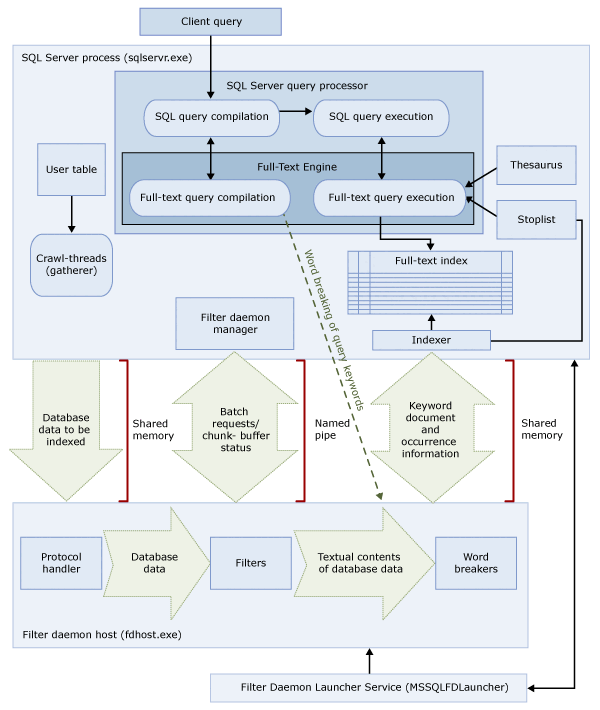
SQL Server-folyamat
Az SQL Server-folyamat a következő összetevőket használja a teljes szöveges kereséshez:
| Összetevő | Leírás |
|---|---|
| Felhasználói táblák | Ezek a táblák tartalmazzák a teljes szöveges indexelendő adatokat. |
| Teljes szöveges adatgyűjtő | A teljes szöveges adatösszegyűjtő a teljes szöveges bejárási folyamatokkal működik. Felelős a teljes szöveges indexek ütemezéséért és vezetéséért, valamint a teljes szöveges katalógusok monitorozásáért is. |
| Szinonimaszótár-fájlok | Ezek a fájlok a keresési kifejezések szinonimáit tartalmazzák. További információ: Szinonimaszótárfájlok konfigurálása és kezelése Full-Text kereséshez. |
| Lekciólista objektumok | A stoplist objektumok olyan gyakori szavak listáját tartalmazzák, amelyek nem hasznosak a kereséshez. További információkért lásd: Stopwords és Stoplists konfigurálása és kezelése a Full-Text Kereséshez. |
| SQL Server lekérdezésfeldolgozó | A lekérdezésfeldolgozó SQL-lekérdezéseket fordít és hajt végre. Ha egy SQL-lekérdezés tartalmaz egy teljes szöveges keresési lekérdezést, a rendszer elküldi a lekérdezést a Full-Text motornak a fordítás és a végrehajtás során is. A lekérdezés eredménye megfelel a teljes szöveges indexnek. |
| Full-Text motor | Az SQL Server Full-Text motorja teljes mértékben integrálva van a lekérdezésfeldolgozóval. A Full-Text motor lefordítja és végrehajtja a teljes szöveges lekérdezéseket. A lekérdezés végrehajtása során előfordulhat, hogy a Full-Text motor bemenetet kap a szinonimaszótárból és a stoplistából. |
| Indexíró (indexelő) | Az indexíró létrehozza az indexelt jogkivonatok tárolására használt struktúrát. |
| Szűrő démon kezelője | A szűrő démonkezelője felelős a Full-Text motorszűrő démongazda állapotának monitorozásáért. |
A Démon gazdagép szűrése folyamat
A szűrődémon gazdagépe egy folyamat, amelyet a Full-Text motor indít el. A következő teljes szöveges keresési összetevőket futtatja, amelyek a táblákból származó adatok eléréséért, szűréséért és szótöréséért, valamint a szavak feltöréséért és a lekérdezés bemenetének lekéréséért felelősek.
A szűrődémon gazdagép összetevői a következők:
| Összetevő | Leírás |
|---|---|
| Protokollkezelő | Ez az összetevő további feldolgozás céljából lekéri az adatokat a memóriából, és egy adott adatbázisban lévő felhasználói táblából fér hozzá az adatokhoz. Az egyik feladata az, hogy adatokat gyűjtsön a teljes szöveges indexáláson átesett oszlopokból, és átadja azokat a szűrődémon gazdának, amely szükség szerint alkalmazza a szűrést és a szótörést. |
| Szűrők | Bizonyos adattípusok szűrést igényelnek ahhoz, hogy a dokumentum adatai teljes szöveges indexelhetők legyenek, beleértve a varbináris, a varbinary(max), a kép vagy az XML-oszlopok adatait is. Az adott dokumentumhoz használt szűrő a dokumentum típusától függ. Különböző szűrőket használnak például a Microsoft Word-dokumentumokhoz.doc, a Microsoft Excel-dokumentumokhoz.xls és az XML- (.xml) dokumentumokhoz. Ezután a szűrő kinyeri a szövegrészeket a dokumentumból, eltávolítja a beágyazott formázást, és megőrzi a szöveget, és esetleg információt ad a szöveg helyzetéről. Az eredmény szöveges információk adatfolyama. További információ: Keresés szűrőinek konfigurálása és kezelése. |
| Szótörők és gyökeresítők | A szóhatároló egy nyelvspecifikus összetevő, amely egy adott nyelv lexikális szabályai (szótörés) alapján keresi meg a szavak határait. Minden szótörés egy nyelvspecifikus ősösszetevőhöz van társítva, amely konjugálja az igéket, és inflekciós bővítéseket hajt végre. Indexeléskor a szűrő démonkiszolgáló szótörőt és tőszármaztatót használ egy adott táblázatoszlop szöveges adatainak nyelvi elemzéséhez. A teljes szöveges indexben a táblázatoszlophoz társított nyelv határozza meg, hogy melyik szóhatárolót és szótőelemzőt használják az oszlop indexeléséhez. További információ: Szóhatárolók és -ősök konfigurálása és kezelése kereséshez (SQL Server). |
Az SQL Server 2012 (11.x) az amerikai angol (LCID 1033) és az Egyesült Királyság angol (LCID 2057) szóhatárolóinak és őselemeinek új verzióját telepíti. Az összetevők korábbi verziójára azonban válthat, ha meg szeretné őrizni az előző viselkedést. További információt a Az amerikai angol és az egyesült királyságbeli angol nyelvhez használt Szótörő módosítása részben talál.
Full-Text Keresés feldolgozása
A teljes szöveges keresést a Full-Text motor hajtja. A Full-Text motor két szerepkörrel rendelkezik: a támogatás indexelésével és a támogatás lekérdezésével.
Full-Text indexelési folyamat
Amikor teljes szöveges indexelés (más néven bejárás) indul, a Full-Text Engine nagy mennyiségű adatot visz át a memóriába, és értesíti a szűrődémon hosztot. A kiszolgáló szűri és szótöri az adatokat, majd a kapott adatokat fordított szólistákká alakítja. A teljes szöveges keresés ezután lekéri a konvertált adatokat a szólistákból, feldolgozza az adatokat a szóismétlések eltávolításához, és egy vagy több fordított indexben tartósan tárolja a szólisták kötegét.
A varbinary(max) vagy a képoszlopban tárolt adatok indexelésekor a felületet implementáló IFilter szűrő a megadott fájlformátum (például Microsoft Word) alapján nyeri ki a szöveget. Bizonyos esetekben a szűrőösszetevőknek a varbinary(max) vagy a képadatokat ki kell írniuk a filterdata mappába ahelyett, hogy a memóriába kellene őket leküldniük.
A feldolgozás részeként az összegyűjtött szöveges adatokat egy szóbontón keresztül küldik, hogy a szöveget különálló tokenekre vagy kulcsszavakra bontsa. A tokenizáláshoz használt nyelv az oszlop szintjén van megadva, vagy a szűrőösszetevő varbinary(max), kép- vagy XML-adatai között azonosítható.
Lehetséges további feldolgozást végezni a szóelhagyások eltávolítására és a tokenek normalizálására, mielőtt a teljes szövegindexben vagy egy indextöredékben tárolják őket.
Amikor egy populáció teljes, egy végső egyesítési folyamat indul el, amely egyesíti az indextöredékeket egy fő teljes szöveges indexszé. Ez jobb lekérdezési teljesítményt eredményez, mivel több indextöredék helyett csak a fő indexet kell lekérdezni, és jobb pontozási statisztikák használhatók a relevancia rangsorolásához.
Full-Text lekérdezési folyamat
A lekérdezésfeldolgozó átadja a lekérdezés teljes szöveges részeit a Full-Text motornak feldolgozás céljából. A Full-Text motor szótörést végez, és szükség esetén szinonimaszótár-bővítést, származtatást, valamint zajszófeldolgozást is végrehajt. Ezután a lekérdezés teljes szöveges részei SQL-operátorok formájában jelennek meg, elsősorban streamelési táblaértékű függvényekként (STVF-ek). A lekérdezés végrehajtása során ezek az STVF-ek a fordított indexhez férnek hozzá a megfelelő eredmények lekéréséhez. Az eredmények vagy ezen a ponton lesznek visszaadva az ügyfélnek, vagy tovább dolgozzák őket, mielőtt visszakerülnének az ügyfélhez.
Teljes szöveges indexarchitektúra
A Full-Text motor a teljes szöveges indexekben található információkat teljes szöveges lekérdezések fordítására használja, amelyek gyorsan kereshetnek egy táblában bizonyos szavakat vagy szavak kombinációit. A teljes szöveges indexek egy adatbázistábla egy vagy több oszlopában tárolják a fontos szavakra és azok helyére vonatkozó információkat. A teljes szöveges index az SQL Server Full-Text motorja által létrehozott és karbantartott tokenalapú funkcionális indexek speciális típusa. A teljes szöveges index létrehozásának folyamata eltér más típusú indexek készítésétől. Ahelyett, hogy egy adott sorban tárolt értéken alapuló B-fastruktúrát hoznának létre, a Full-Text motor fordított, halmozott, tömörített indexstruktúrát épít az indexelt szöveg egyes tokenjeiből. A teljes szöveges index méretét csak annak a számítógépnek a rendelkezésre álló memóriaerőforrásai korlátozzák, amelyen az SQL Server-példány fut.
Az SQL Server 2008-tól kezdve (10.0.x) a teljes szöveges indexek integrálva vannak az adatbázismotorral, ahelyett, hogy a fájlrendszerben tartózkodnak, mint az SQL Server korábbi verzióiban. Új adatbázis esetén a teljes szöveges katalógus mostantól egy olyan virtuális objektum, amely nem tartozik fájlcsoporthoz; ez csupán egy logikai fogalom, amely a teljes szöveges indexek egy csoportjára hivatkozik. Vegye figyelembe azonban, hogy az SQL Server 2005 (9.x) adatbázis frissítése során az adatfájlokat tartalmazó teljes szöveges katalógusok új fájlcsoportot hoznak létre; további információt a Full-Text Keresés frissítése című témakörben talál.
Táblánként csak egy teljes szöveges index engedélyezett. Ahhoz, hogy egy táblán teljes szöveges indexet lehessen létrehozni, a táblának egyetlen, egyedi, nem null oszloppal kell rendelkeznie. Létrehozhat teljes szöveges indexet char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary és varbinary(max) típusú oszlopokon a teljes szöveges kereséshez. Ha egy teljes szöveges indexet hoz létre egy olyan oszlopon, amelynek adattípusa varbináris, varbinary(max), kép vagy xml , meg kell adnia egy típusoszlopot. A típusoszlop egy táblaoszlop, amelyben a dokumentum fájlkiterjesztését (.doc, .pdfés .xlsígy tovább) tárolja minden sorban.
Teljes szöveges indexstruktúra
A teljes szöveges index szerkezetének alapos ismerete segít megérteni a Full-Text Motor működését. Ez a cikk a Document táblázat AdventureWorks2025 alábbi részletét használja példatáblaként. Ez a részlet csak két oszlopot, az DocumentID oszlopot és az Title oszlopot, valamint a táblázat három sorát jeleníti meg.
Ebben a példában feltételezzük, hogy egy teljes szöveges index lett létrehozva az Title oszlopban.
| Dokumentumazonosító | Cím |
|---|---|
1 |
Crank Arm and Tire Maintenance |
2 |
Front Reflector Bracket and Reflector Assembly 3 |
3 |
Front Reflector Bracket Installation |
Például a következő táblázat, amely az 1. töredéket jeleníti meg, ábrázolja a Title oszlopon létrehozott teljes szöveges index tartalmát a Document táblázatban. A teljes szöveges indexek több információt tartalmaznak, mint amennyit a táblázat tartalmaz. A táblázat egy teljes szöveges index logikai ábrázolása, és csak szemléltetésre szolgál. A sorok tömörített formátumban vannak tárolva a lemezhasználat optimalizálása érdekében.
Az adatok megfordítva vannak az eredeti dokumentumokból. Az inverzió azért következik be, mert a kulcsszavakat a dokumentumazonosítókhoz rendelik. Ezért a teljes szöveges indexeket gyakran fordított indexnek is nevezik.
Azt is megfigyelheti, hogy a kulcsszó and el lesz távolítva a teljes szöveges indexből. Ez azért van így, mert and egy stopword, és a stopwords eltávolítása egy teljes szöveges indexből jelentős megtakarítást eredményezhet a lemezterületen, ami javítja a lekérdezési teljesítményt. További információ a stopwordsről: Stopwords és Stoplists konfigurálása és kezelése Full-Text Kereséshez.
Töredék 1
| Kulcsszó | ColId | Dokumentumazonosító | Előfordulás |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Front |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Bracket |
1 | 3 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Installation |
1 | 3 | 4 |
Az Keyword oszlop egyetlen, indexelési időpontban kinyert tokent tartalmaz. A szóelválasztók határozzák meg, hogy mi alkot egy tokent.
Az ColId oszlop egy olyan értéket tartalmaz, amely egy teljes szöveges indexelt oszlopnak felel meg.
Az DocId oszlop egy 8 bájtos egész szám értékeit tartalmazza, amelyek egy teljes szöveges indexelt táblázat adott teljes szöveges kulcsértékéhez lesznek leképezettek. Ez a leképezés akkor szükséges, ha a teljes szöveges kulcs nem egész adattípus. Ilyen esetekben a teljes szöveges kulcsértékek és DocId értékek közötti megfeleltetés egy külön táblában, a DocId Mapping táblában marad fenn. A leképezések lekérdezéséhez használja a sp_fulltext_keymappings rendszer által tárolt eljárást. A keresési feltétel DocId teljesítéséhez az előző tábla értékeit össze kell illeszteni a leképezési táblával a DocId lekérdezett alaptábla sorainak lekéréséhez. Ha az alaptábla teljes kulcsértéke egész szám típusú, akkor az érték közvetlenül szolgál DocId szerepében, és nincs szükség leképezésre. Ezért a teljes szöveges kulcsértékek egész számának használata segíthet a teljes szöveges lekérdezések optimalizálásában.
Az Occurrence oszlop egész számot tartalmaz. Minden DocId-értékhez tartozik egy lista az előfordulási értékekről, amelyek megfelelnek az adott kulcsszó relatív szóeltolásainak a DocId-ben. Az előfordulási értékek hasznosak a kifejezés- vagy közelségi egyezések meghatározásában, például a kifejezések numerikusan szomszédos előfordulási értékekkel rendelkeznek. Hasznosak a relevanciaértékek számításában is; Például egy kulcsszó előfordulásainak száma a DocId-ben használható a pontozáshoz.
Teljes szöveges indextöredékek
A logikai teljes szöveges index általában több belső táblára oszlik. Minden belső táblázatot teljes szöveges indextöredéknek nevezünk. Ezen töredékek némelyike újabb adatokat tartalmazhat, mint mások. Ha például egy felhasználó frissíti a következő sort, amelynek DocId értéke 3, és a tábla automatikusan módosul, egy új töredék jön létre.
| Dokumentumazonosító | Cím |
|---|---|
3 |
Rear Reflector |
A következő példában, amely a 2. töredéket mutatja be, a töredék frissebb adatokat tartalmaz a DocId 3-ról az 1. töredékhez képest. Ezért a felhasználó lekérdezésekor a DocId 3-hoz a 2. töredék adatait használjuk fel. Minden töredék egy létrehozási időbélyeggel van megjelölve, amely lekérdezhető a sys.fulltext_index_fragments katalógusnézet használatával.
Töredék 2
| Kulcsszó | ColId | Dokumentumazonosító | Előfordulás |
|---|---|---|---|
Rear |
1 | 3 | 1 |
Reflector |
1 | 3 | 2 |
Ahogy a 2. töredékből is látható, a teljes szöveges lekérdezéseknek belsőleg kell lekérdeznie az egyes töredékeket, és el kell vetnie a régebbi bejegyzéseket. Ezért a teljes szöveges index túl sok teljes szöveges indextöredéke jelentős leromláshoz vezethet a lekérdezési teljesítményben. A töredékek számának csökkentése érdekében az REORGANIZETransact-SQL utasítással átrendezheti a teljes szöveges katalógust. Ez az utasítás egy fő egyesítést hajt végre, amely egyetlen nagyobb töredékbe egyesíti a töredékeket, és eltávolítja az összes elavult bejegyzést a teljes szöveges indexből.
Az átrendezés után a példaindex a következő sorokat tartalmazza:
| Kulcsszó | ColId | Dokumentumazonosító | Előfordulás |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Rear |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
A teljes szöveges indexek és a normál SQL Server-indexek közötti különbségek
| Teljes szöveges indexek | Normál SQL Server-indexek |
|---|---|
| Táblánként csak egy teljes szöveges index engedélyezett. | Táblánként több normál index engedélyezett. |
| Az adatok teljes szöveges indexekhez , úgynevezett populációkhoz való hozzáadása ütemezéssel vagy adott kéréssel kérhető, vagy automatikusan, új adatok hozzáadásával történhet. | Automatikusan frissül, amikor a rendszer beszúrja, frissíti vagy törli azokat az adatokat, amelyeken alapulnak. |
| Ugyanabban az adatbázisban csoportosítva egy vagy több teljes szöveges katalógusba. | Nincs csoportosítva. |
Full-Text nyelvi összetevők keresése és nyelvi támogatás
A teljes szöveges keresés közel 50 különböző nyelvet támogat, például angol, spanyol, kínai, japán, arab, bangla és hindi nyelvet. A támogatott teljes szöveges nyelvek teljes listáját a sys.fulltext_languages című témakörben találja. A teljes szöveges indexben található oszlopok mindegyike egy Microsoft Windows területi azonosítóhoz (LCID) van társítva, amely egy teljes szöveges keresés által támogatott nyelvnek felel meg. Az LCID 1033 például amerikai angol, a LCID 2057 pedig brit angol. Az SQL Server minden támogatott teljes szöveges nyelvhez olyan nyelvi összetevőket biztosít, amelyek támogatják az adott nyelven tárolt teljes szöveges adatok indexelését és lekérdezését.
A nyelvspecifikus összetevők a következő elemeket tartalmazzák:
| Összetevő | Leírás |
|---|---|
| Szótörők és gyökeresítők | A szóválasztók egy adott nyelv lexikális szabályai (szótörés) alapján találják meg a szóhatárokat. Minden szóelemző egy olyan szótövezőhöz van társítva, amely ugyanahhoz a nyelvhez konjugálja az igéket. További információ: Szóhatárolók és -ősök konfigurálása és kezelése kereséshez (SQL Server). |
| Stoplisták | Rendelkezésre áll egy rendszer-stoplista, amely a stopwords (más néven zajszavak) alapszintű készletét tartalmazza. A stopword olyan szó, amely nem segít a keresésben, és a teljes szöveges lekérdezések figyelmen kívül hagyják. Például az angol nyelvhelynél olyan szavak, mint a a, and, is, és the megállítószavaknak minősülnek. Általában egy vagy több szinonimaszótárfájlt és stoplistát kell konfigurálnia. További információkért lásd: Stopwords és Stoplists konfigurálása és kezelése a Full-Text Kereséshez. |
| Szinonimaszótár-fájlok | Az SQL Server emellett egy szinonimaszótárfájlt is telepít minden teljes szövegű nyelvhez és egy globális szinonimaszótárfájlhoz. A telepített szinonimaszótárfájlok üresek, de szerkesztheti őket egy adott nyelv vagy üzleti forgatókönyv szinonimáinak definiálásához. A teljes szöveges adatokra szabott szinonimaszótár fejlesztésével hatékonyan bővítheti az adatokra vonatkozó teljes szöveges lekérdezések hatókörét. További információ: Szinonimaszótárfájlok konfigurálása és kezelése Full-Text kereséshez. |
| Szűrők (iFilters) | Ha egy dokumentumot varbinary(max), image vagy xml adattípusú oszlopban indexel, szűrőre van szükség a további feldolgozáshoz. A szűrőnek a dokumentum típusára (.doc, , .pdf, .xls.xmlstb.) kell vonatkoznia. További információ: Keresés szűrőinek konfigurálása és kezelése. |
A szóhatárolók (és a szótövek) és a szűrők a szűrődémon folyamatában (fdhost.exe) futnak.