Skálázás a KEDA-val
Kubernetes eseményvezérelt automatikus skálázás
A Kubernetes eseményvezérelt automatikus skálázás (KEDA) egy egyszerű és egyszerűsített összetevő, amely leegyszerűsíti az alkalmazások automatikus skálázását. A KEDA-t bármely Kubernetes-fürthöz hozzáadhatja, és használhatja a szabványos Kubernetes-összetevőkkel együtt, például a Vízszintes pod automatikus skálázása (HPA) vagy a fürt automatikus skálázási funkciója mellett. A KEDA-val olyan alkalmazásokat célozhat meg, amelyeket eseményvezérelt skálázásra szeretne használni, és lehetővé teheti, hogy más alkalmazások különböző skálázási módszereket használjanak. A KEDA egy rugalmas és biztonságos lehetőség, amely tetszőleges számú Kubernetes-alkalmazással vagy keretrendszerrel együtt futtatható.
Főbb képességek és funkciók
- Fenntartható és költséghatékony alkalmazások létrehozása nullára skálázási képességekkel
- Alkalmazások számítási feladatainak méretezése az igények kielégítésére KEDA-skálázók használatával
- Alkalmazások automatikus méretezése
ScaledObjects - Feladatok automatikus méretezése a
ScaledJobs - Éles szintű biztonság használata az automatikus skálázás és a hitelesítés számítási feladatoktól való leválasztásával
- Saját külső skálázó használata személyre szabott automatikus méretezési konfigurációk használatához
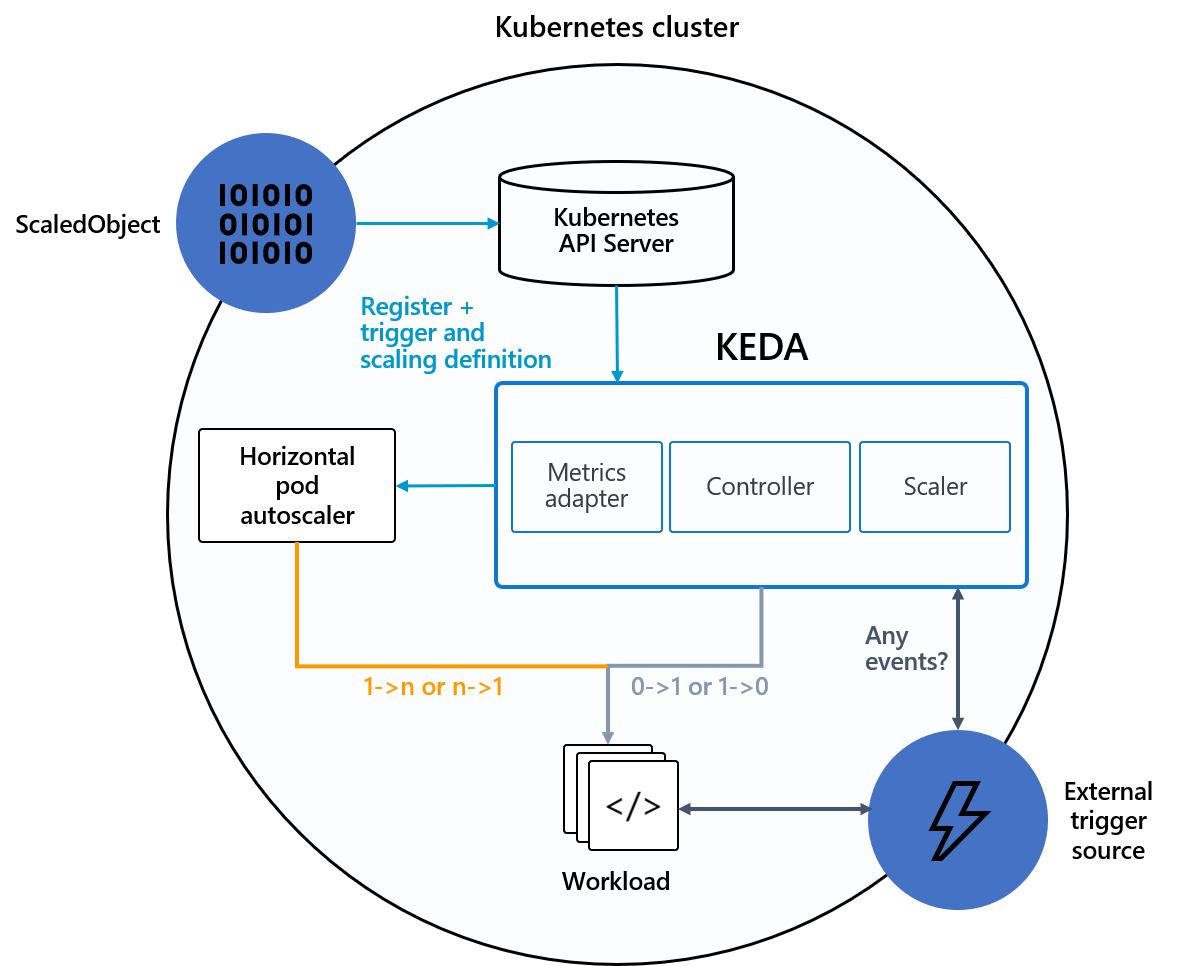
Architektúra
A KEDA két fő összetevőt biztosít:
- KEDA-operátor: Lehetővé teszi, hogy a végfelhasználók nulláról N példányokra skálázhatják a számítási feladatokat a Kubernetes-környezetek, a feladatok, a StatefulSets vagy bármely olyan ügyfélerőforrás támogatásával, amely egy alforrást
/scalehatároz meg. - Metrikák kiszolgálója: Külső metrikákat tesz elérhetővé a HPA-nak, például egy Kafka-témakör üzeneteit vagy az Azure Event Hubs eseményeit, hogy automatikus skálázási műveleteket hajtson végre. A felsőbb rétegbeli korlátozások miatt a KEDA metrikakiszolgálónak kell lennie a fürtben az egyetlen telepített metrikaadapternek.
Az alábbi ábra bemutatja, hogyan integrálható a KEDA a Kubernetes HPA-val, külső eseményforrásokkal és Kubernetes API Serverrel az automatikus skálázási funkciók biztosításához:
Tipp.
További információkért tekintse meg a HIVATALOS KEDA dokumentációját.
Eseményforrások és skálázók
A KEDA-skálázók észlelik, hogy az üzembe helyezést aktiválni vagy inaktiválni kell-e, és egyéni metrikákat kell-e betáplálni egy adott eseményforráshoz. A számítási feladatok KEDA-val történő méretezésének leggyakoribb módja az üzembe helyezések és a StatefulSets. Az alforrást megvalósító /scale egyéni erőforrásokat is skálázhatja. Meghatározhatja a Kubernetes üzembe helyezését vagy a StatefulSetet, amelyet a KEDA skálázni szeretne egy méretezési eseményindító alapján. A KEDA figyeli ezeket a szolgáltatásokat, és automatikusan skálázza őket az események alapján.
A háttérben a KEDA figyeli az eseményforrást, és az adatokat a Kubernetesbe és a HPA-ba folyamozza a gyors erőforrás-skálázás érdekében. Egy erőforrás minden replikája aktívan lekéri az elemeket az eseményforrásból. A KEDA használatával Deployments/StatefulSetsaz események alapján skálázhat, miközben az eseményforrással (például sorrendben történő feldolgozással, újrapróbálkozással, holtponttal vagy ellenőrzőpontokkal) is megőrizheti a gazdag kapcsolatot és a szemantikát.
Skálázott objektum specifikációja
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Skálázott feladat specifikációja
Az eseményvezérelt kód központi telepítésként való skálázásának alternatívaként a kódot Kubernetes-feladatként is futtathatja és skálázhatja. Ennek a beállításnak az elsődleges oka az, ha hosszú ideig futó végrehajtásokat kell feldolgoznia. Ahelyett, hogy egy üzembe helyezésen belül több eseményt dolgoz fel, minden észlelt esemény saját Kubernetes-feladatát ütemezi. Ez a módszer lehetővé teszi az egyes események külön-külön történő feldolgozását, és az egyidejű végrehajtások számát az üzenetsor eseményeinek száma alapján skálázhatja.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}