Intelligens lekérdezésfeldolgozás ismertetése
Az SQL Server 2017-ben és 2019-ben, valamint az Azure SQL-ben a Microsoft számos új funkciót vezetett be a 140-150-ös kompatibilitási szintre. Ezen funkciók közül sok helyesen alkalmazza a korábban antimintákat, például a felhasználó által definiált skaláris értékfüggvényeket és a táblaváltozókat.
Ezek a funkciók néhány funkciócsaládra oszlanak:
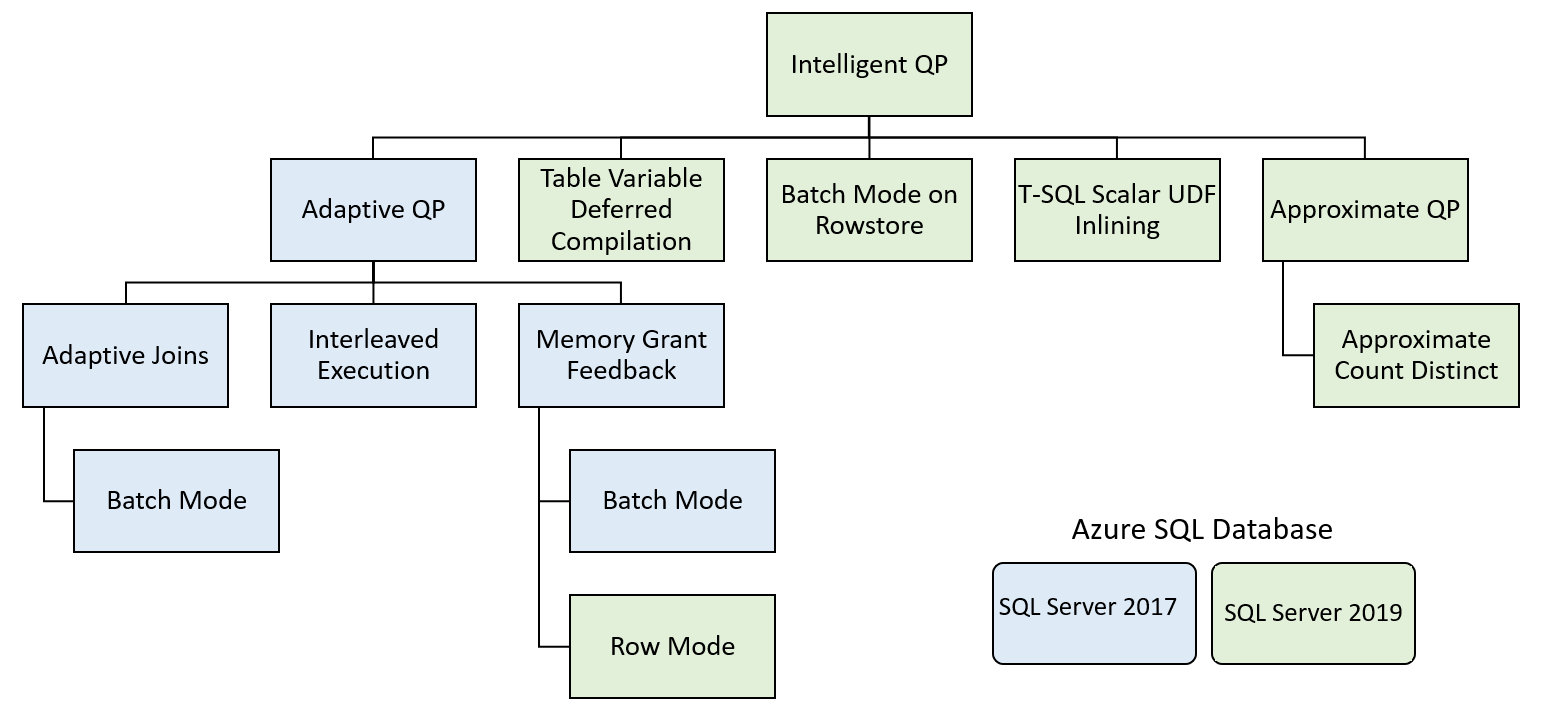
Az intelligens lekérdezésfeldolgozás olyan funkciókat tartalmaz, amelyek minimális megvalósítási munkával javítják a számítási feladatok teljesítményét.
Ha a számítási feladatokat automatikusan jogosulttá szeretné tenni az intelligens lekérdezések feldolgozására, módosítsa a megfelelő adatbázis-kompatibilitási szintet 150-esre. Példa:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Adaptív lekérdezés-feldolgozás
Az adaptív lekérdezésfeldolgozás számos lehetőséget tartalmaz, amelyek a lekérdezés végrehajtási környezete alapján dinamikusabbá teszik a lekérdezésfeldolgozást. Ezek a lehetőségek számos olyan funkciót tartalmaznak, amelyek javítják a lekérdezések feldolgozását.
Adaptív illesztések – az adatbázismotor a hash és a beágyazott hurkok közötti illesztés kiválasztását az illesztésbe beszúrt sorok száma alapján módosítja. Az adaptív illesztések jelenleg csak kötegelt végrehajtási módban működnek.
Interleaved Execution – Ez a funkció jelenleg támogatja a többutas táblaértékű függvényeket (MSTVF). Az SQL Server 2017 előtt az MSTVF-k rögzített sorbecslést használtak egy vagy 100 sorra az SQL Server verziójától függően. Ez a becslés optimálisabb lekérdezési tervekhez vezethet, ha a függvény sokkal több sort ad vissza. A rendszer tényleges sorszámot generál az MSTVF-ből, mielőtt a terv többi részét átjárt végrehajtással fordítanák le.
Memória-visszacsatolás – Az SQL Server a lekérdezés kezdeti tervében létrehoz egy memóriakiadást a statisztikákból származó sorszámbecslések alapján. A súlyos adateltérés a sorok számának túl- vagy alulbecsléséhez vezethet, ami a memória túlhasználatát okozhatja, ami csökkenti az egyidejűséget, vagy alulkivonásokat okozhat, ami miatt a lekérdezés adatokat ömölhet a tempdb-be. A memória-visszacsatolással az SQL Server észleli ezeket a feltételeket, és csökkenti vagy növeli a lekérdezés számára biztosított memória mennyiségét a kiömlés vagy túlterhelés elkerülése érdekében.
Ezek a funkciók automatikusan engedélyezve vannak a 150-ös kompatibilitási módban, és nem igényelnek más módosításokat az engedélyezéshez.
Táblaváltozó késleltetett fordítása
Az MSTVF-ekhez hasonlóan az SQL Server végrehajtási terveinek táblaváltozói is egy sor rögzített sorszámbecslését tartalmazzák. Az MSTVF-ekhez hasonlóan ez a rögzített becslés is gyenge teljesítményt eredményezett, amikor a változó a vártnál nagyobb sorszámmal rendelkezett. Az SQL Server 2019-ben a táblaváltozók elemzése megtörtént, és tényleges sorszámmal rendelkezik. A halasztott fordítás természete hasonló az MSTVF-ek interleaved végrehajtásához, azzal a különbségtel, hogy a lekérdezés első fordításakor történik, nem pedig dinamikusan a végrehajtási terven belül.
Batch mód a sortárolóban
A kötegelt végrehajtási mód lehetővé teszi az adatok kötegelt feldolgozását sorról sorra helyett. A számításokhoz és aggregációkhoz jelentős cpu-költségekkel járó lekérdezések látják a feldolgozási modell legnagyobb előnyét. A kötegelt feldolgozás és az oszlopcentrikus indexek elkülönítésével több számítási feladat is kihasználhatja a kötegelt módú feldolgozás előnyeit.
Skaláris, felhasználó által definiált függvények inlining
Az SQL Server régebbi verzióiban a skaláris függvények több okból is rosszul teljesítettek. A skaláris függvények iteratív módon lettek végrehajtva, hatékonyan feldolgozva egyszerre egy sort. Nem rendelkeztek megfelelő költségbecsléssel egy végrehajtási tervben, és nem engedélyezték a párhuzamosságot egy lekérdezési tervben. A felhasználó által definiált függvények tagolásával ezek a függvények skaláris al lekérdezésekké alakulnak a végrehajtási terv felhasználó által definiált függvényoperátora helyett. Ez az átalakítás jelentős teljesítménynövekedéshez vezethet a skaláris függvényhívásokat tartalmazó lekérdezések esetében.
Hozzávetőleges számelhatárolható
Az adattárház-lekérdezések gyakori mintája a megrendelések vagy felhasználók eltérő számának végrehajtása. Ez a lekérdezési minta költséges lehet egy nagy táblához. A hozzávetőleges darabszám becslése gyorsabb módszert vezet be a sorok csoportosításával történő egyedi darabszám összegyűjtésére. Ez a függvény 2%-os hibaarányt garantál 97%-os megbízhatósági intervallummal.