Szöveg használata beszéd API-hoz
A Speech to Text API-khoz hasonlóan az Azure AI Speech szolgáltatás más REST API-kat is kínál a beszédszintézishez:
- A Szöveg–beszéd API, amely a beszédszintézis elsődleges módja.
- A Batch szintézis API, amely olyan kötegelt műveletek támogatására lett kialakítva, amelyek nagy mennyiségű szöveget konvertálnak hanggá – például hangkönyvet hozhat létre a forrásszövegből.
A REST API-król a Text to Speech REST API dokumentációjában olvashat bővebben. A gyakorlatban a legtöbb interaktív beszédalapú alkalmazás egy (programozási) nyelvspecifikus SDK-n keresztül használja az Azure AI Speech szolgáltatást.
Az Azure AI Speech SDK használata
A beszédfelismeréshez hasonlóan a gyakorlatban a legtöbb interaktív beszédalapú alkalmazás az Azure AI Speech SDK használatával készült.
A beszédszintézis implementálásának mintája hasonló a beszédfelismeréshez:
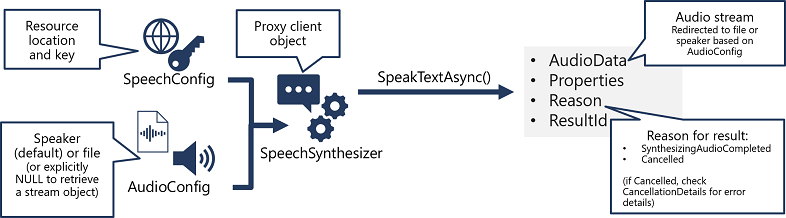
- SpeechConfig-objektum használatával foglalja össze az Azure AI Speech-erőforráshoz való csatlakozáshoz szükséges információkat. Pontosabban a helyét és kulcsát.
- A hangkonfigurációval definiálhatja a szintetizálandó beszéd kimeneti eszközét. Alapértelmezés szerint ez az alapértelmezett rendszerhangszóró, de megadhat egy hangfájlt is, vagy ha ezt az értéket explicit módon null értékre állítja, feldolgozhatja a közvetlenül visszaadott hangstream objektumot.
- SpeechSynthesizer objektum létrehozásához használja a SpeechConfig és az AudioConfig parancsot. Ez az objektum a Text to Speech API proxyügyfele.
- Használja a SpeechSynthesizer objektum metódusait a mögöttes API-függvények meghívásához. A SpeakTextAsync() metódus például az Azure AI Speech szolgáltatással konvertálja a szöveget beszélt hanggá.
- Dolgozza fel az Azure AI Speech szolgáltatás válaszát. A SpeakTextAsync metódus esetében az eredmény egy SpeechSynthesisResult objektum, amely a következő tulajdonságokat tartalmazza:
- AudioData
- Tulajdonságok
- Ok
- Eredményazonosító
A beszéd sikeres szintetizálása után az Ok tulajdonság a SynthesizingAudioCompleted enumerálásra van állítva, és az AudioData tulajdonság tartalmazza a hangstreamet (amely a Hangkonfigurációtól függően automatikusan el lett küldve egy beszélőnek vagy fájlnak).