Keresési index bővítése az Azure AI Searchben egyéni osztályokkal és Azure AI-nyelvvel
Az egyéni szövegbesorolás lehetővé teszi, hogy egy szövegszakaszt különböző felhasználói osztályokhoz rendeljen. Betaníthat például egy modellt a könyvek hátlapján lévő szinopszisra, hogy automatikusan azonosítsa a könyvek műfaját. Ezután ezt az azonosított műfajt használva gazdagíthatja online bolt keresőjét egy műfaji aspektussal.
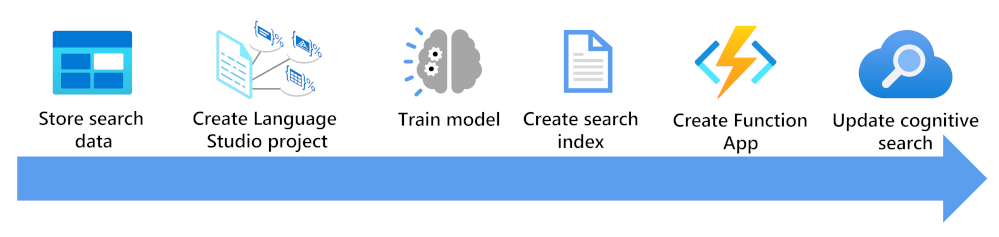
Itt láthatja, mit kell figyelembe vennie egy keresési index egyéni szövegbesorolási modellel való bővítéséhez.
- A dokumentumok tárolása a Language Studio és az Azure AI Search indexelői számára
- Egyéni szövegbesorolási projekt létrehozása
- A modell betanítása és tesztelése
- Keresési index létrehozása a tárolt dokumentumok alapján
- Az üzembe helyezett betanított modellt használó függvényalkalmazás létrehozása
- A keresési megoldás, az indexelő, az indexelő és az egyéni képességkészlet frissítése
Az adatok tárolása
Az Azure Blob Storage a Language Studióból és az Azure AI Servicesből is elérhető. A tárolónak elérhetőnek kell lennie, ezért a legegyszerűbb megoldás a Tároló kiválasztása, de privát tárolók használata is lehetséges további konfigurációval.
Az adatok mellett az egyes dokumentumok besorolásának hozzárendelésére is szükség van. A Language Studio egy grafikus eszközt biztosít, amellyel egyenként, manuálisan osztályozhatja az egyes dokumentumokat.
Két különböző projekttípus közül választhat, ha egy dokumentum egyetlen osztályra képez le egy egycímkés besorolási projektet. Ha egy dokumentumot több osztályhoz is hozzárendelhet, használja a többcímke-besorolási projektet.
Ha nem szeretné manuálisan osztályozni az egyes dokumentumokat, az Azure AI Language-projekt létrehozása előtt címkézheti az összes dokumentumot. Ez a folyamat magában foglalja a címkék JSON-dokumentumának létrehozását ebben a formátumban:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
A tömbhöz annyi osztályt kell hozzáadnia, amennyit csak kell classes . A tömb minden dokumentumához hozzáad egy bejegyzést, beleértve a documents dokumentumnak megfelelő osztályokat is.
Az Azure AI Language-projekt létrehozása
Az Azure AI Language-projekt kétféleképpen hozható létre. Ha anélkül kezdi el használni a Language Studiót, hogy először létrehoz egy nyelvi szolgáltatást az Azure Portalon, a Language Studio felajánlja önnek, hogy létrehoz egyet.
Az Azure AI Language-projektek létrehozásának legrugalmasabb módja, ha először az Azure Portalon hozza létre a nyelvi szolgáltatást. Ha ezt a lehetőséget választja, lehetősége van egyéni funkciók hozzáadására.
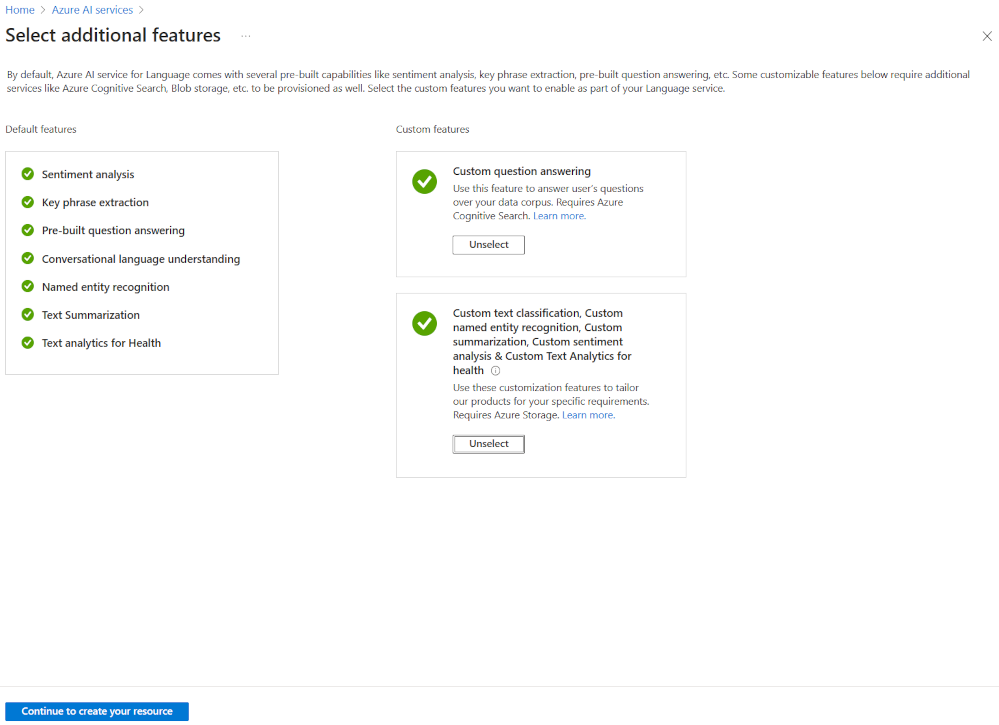
Egyéni szövegbesorolás létrehozásakor válassza ki ezt az egyéni funkciót a nyelvi szolgáltatás létrehozásakor. Ezzel a módszerrel a nyelvi szolgáltatást egy tárfiókhoz is csatolja.
Az erőforrás üzembe helyezése után közvetlenül a Language Studióhoz navigálhat a nyelvi szolgáltatás áttekintő paneljén. Ezután létrehozhat egy új egyéni szövegbesorolási projektet.
Feljegyzés
Ha a Language Studióból hozta létre a nyelvi szolgáltatást, előfordulhat, hogy az alábbi lépéseket kell követnie: Szerepkörök beállítása az Azure Language-erőforráshoz és a tárfiókhoz, hogy a tárolót az egyéni szövegbesorolási projekthez csatlakoztassa.
A besorolási modell betanítása
Az összes AI-modellhez hasonlóan azonosított adatokkal kell rendelkeznie, amelyekkel betanítheti azokat. A modellnek példákat kell látnia arra, hogyan képezhet le adatokat egy osztályra, és példákat kell használnia a modell teszteléséhez. Dönthet úgy, hogy a modell automatikusan felosztja a betanítási adatokat, alapértelmezés szerint a dokumentumok 80%-át használja a modell betanítására, 20%-át pedig vaktesztre. Ha rendelkezik bizonyos dokumentumokkal, amelyekkel tesztelni szeretné a modellt, címkézheti a dokumentumokat tesztelésre.

A Language Studióban a projektben válassza az Adatok címkézése lehetőséget. Az összes dokumentumot látni fogja. Jelölje ki a tesztelési csoporthoz hozzáadni kívánt dokumentumokat, majd válassza a Modell teljesítményének tesztelése lehetőséget. Mentse a frissített címkéket, majd hozzon létre egy új betanítási feladatot.
Keresési index létrehozása
Nincs semmi konkrét teendője egy olyan keresési index létrehozásához, amelyet egy egyéni szövegbesorolási modell egészít ki. Kövesse az Azure AI Search-megoldás létrehozásának lépéseit. A függvényalkalmazás létrehozása után frissíteni fogja az indexet, az indexelőt és az egyéni készséget.
Azure-függvényalkalmazás létrehozása
Kiválaszthatja a függvényalkalmazáshoz használni kívánt nyelvet és technológiákat. Az alkalmazásnak képesnek kell lennie JSON-t átadni az egyéni szövegbesorolási végpontnak, például:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Ezután dolgozza fel a modell JSON-válaszát, például:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
A függvény ezután egy strukturált JSON-üzenetet ad vissza egy egyéni készségkészletnek az AI Searchben, például:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
A függvényalkalmazásnak öt dolgot kell tudnia:
- A besorolandó szöveg.
- A betanított egyéni szövegbesorolási üzembe helyezett modell végpontja.
- Az egyéni szövegbesorolási projekt elsődleges kulcsa.
- A projekt neve.
- Az üzembe helyezés neve.
Az elsőt az AI Search egyéni képességkészlete adja át a függvénynek bemenetként. A fennmaradó négy a Language Studióban található.

A végpont és az üzembe helyezés neve a modell üzembe helyezésének paneljén található.

A projekt neve és elsődleges kulcsa a projektbeállítások panelen található.
Az Azure AI Search-megoldás frissítése
Az Azure Portalon három módosítást kell végrehajtania a keresési index bővítéséhez.
- Az egyéni szövegbesorolási bővítés tárolásához hozzá kell adnia egy mezőt az indexhez.
- Egyéni képességkészletet kell hozzáadnia ahhoz, hogy meghívja a függvényalkalmazást az osztályozandó szöveggel.
- Le kell képeznie a készségkészlet válaszát az indexbe.
Mező hozzáadása meglévő indexhez
Az Azure Portalon nyissa meg az AI Search-erőforrást, válassza ki az indexet, és ehhez a formátumhoz adja hozzá a JSON-t:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Ez a JSON egy összetett mezőt ad hozzá az indexhez az osztály category kereshető mezőben való tárolásához. A második confidenceScore mező a megbízhatósági százalékot két mezőben tárolja.
Az egyéni képességkészlet szerkesztése
Az Azure Portalon válassza ki a készségkészletet, és adja hozzá a JSON-t az alábbi formátumban:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Ez a WebApiSill képességdefiníció azt határozza meg, hogy a rendszer a dokumentum nyelvét és tartalmát bemenetként adja át a függvényalkalmazásnak. Az alkalmazás visszaadja a JSON nevű classszöveget.
A függvényalkalmazás kimenetének leképezése az indexbe
Az utolsó módosítás a kimenet indexbe való leképezése. Az Azure Portalon válassza ki az indexelőt, és szerkessze a JSON-t egy új kimeneti leképezés létrehozásához:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
Az indexelő most már tudja, hogy a függvényalkalmazás document/class kimenetét a classifiedtext mezőben kell tárolni. Mivel ezt összetett mezőként definiálták, a függvényalkalmazásnak vissza kell adnia egy JSON-tömböt, amely egy és confidenceScore egy category mezőt tartalmaz.
Mostantól bővített keresési indexben kereshet az egyéni besorolt szövegben.