Problémás lekérdezési tervek azonosítása
A lekérdezési teljesítmény hibaelhárításának tipikus módszere a problémás lekérdezés azonosítása, általában a legtöbb rendszererőforrást használó lekérdezés azonosítása, majd a végrehajtási terv lekérése. Két fő forgatókönyv létezik. Az egyik forgatókönyv az, hogy a lekérdezés folyamatosan rosszul teljesít. Ennek oka különböző problémák lehetnek, például hardvererőforrás-korlátozások (bár ez általában nem érinti az elszigetelten futó lekérdezéseket), a nem optimális lekérdezési struktúrát, az adatbáziskompatibilitási beállításokat, a hiányzó indexeket vagy a lekérdezésoptimalizáló rossz tervbeállításait. A második forgatókönyv az, hogy a lekérdezés egyes végrehajtásokban jól teljesít, másokban azonban gyengén. Ezt az inkonzisztencia olyan tényezőket okozhat, mint az adateltérés egy paraméteres lekérdezésben, amely hatékony tervvel rendelkezik egyes végrehajtásokhoz, és mások számára gyenge. Más gyakori tényezők közé tartozik a blokkolás, amikor egy lekérdezés egy másik lekérdezés befejezésére vár, hogy hozzáférjen egy táblához, vagy hardveres versengés.
Vizsgáljuk meg részletesebben ezeket a forgatókönyveket.
Hardverkorlátozások
A hardverkorlátozások általában nem nyilvánulnak meg egyetlen lekérdezés végrehajtása során, de éles terhelés esetén nyilvánvalóvá válnak, ha a processzorszálak és a memória korlátozott. A cpu-versengés a teljesítményfigyelő "% processzoridő" számlálójának megfigyelésével észlelhető, amely a kiszolgáló processzorhasználatát méri. Az SQL Serverben SOS_SCHEDULER_YIELD és CXPACKET várakozási típusok jelezhetik a processzorterhelést. A tárolórendszer gyenge teljesítménye még az optimalizált egyetlen lekérdezés-végrehajtást is lelassíthatja. A tárolási teljesítmény az operációs rendszer szintjén a legjobban nyomon követhető, ha a telítményfigyelő számlálókat Disk Seconds/Read és Disk Seconds/Write, valamint az I/O-műveletek befejezési idejének mérésére használják. Az SQL Server gyenge tárolási teljesítményt naplóz, ha egy I/O 15 másodpercnél hosszabb ideig tart. Az SQL Server magas PAGEIOLATCH_SH várakozása a tárolási teljesítmény problémáit jelezheti. A hardverteljesítményt általában a hibaelhárítási folyamat korai szakaszában értékelik ki a könnyű értékelés miatt.
Az adatbázis teljesítményével kapcsolatos problémák többsége az optimálisnál rosszabb lekérdezési mintákból ered, ami indokolatlan nyomást jelenthet a hardverre. A hiányzó indexek például a szükségesnél több adat beolvasásával processzor-, tárolási és memóriaterheléshez vezethetnek. Javasoljuk, hogy a hardverproblémák kezelése előtt kezelje és hangolja az optimálisnál rosszabb lekérdezéseket. Ezután a lekérdezés finomhangolását vizsgáljuk meg.
Optimálisnál rosszabb lekérdezési szerkezetek
A relációs adatbázisok a legjobban a set-alapú műveletek végrehajtásakor teljesítenek, amelyek a készletekben lévő adatokat (INSERT, , UPDATE, DELETEés SELECT) módosítják, és egyetlen értéket vagy eredményhalmazt állítanak elő. Az alternatív megoldás a soralapú feldolgozás, kurzorok vagy hurkok használatával, amelyek lineárisan növelik a költségeket az érintett sorok számával – az adatmennyiségek növekedésével járó problémás skálázás.
A soralapú műveletek nem optimális használatának észlelése kurzorokkal vagy WHILE hurkokkal fontos, de vannak más SQL Server-ellenes minták is, amelyeket fel kell ismerni. A táblaértékű függvények (TVF-ek), különösen a többutas TVF-ek problémás végrehajtási tervmintákat okoztak az SQL Server 2017 előtt. A fejlesztők gyakran többutas TVF-ekkel hajtanak végre több lekérdezést egyetlen függvényen belül, és egyetlen táblába összesítik az eredményeket. A TVF-k használata azonban teljesítménybírságokhoz vezethet.
Az SQL Server kétféle TVF-vel rendelkezik: beágyazott és többutas. A beágyazott TVF-eket nézetekként, a többutas TVF-eket pedig táblákként kezeli a rendszer a lekérdezésfeldolgozás során. Mivel a TVF-k dinamikusak, és nincsenek statisztikák, az SQL Server rögzített sorok számát használja a lekérdezésterv költségeinek becsléséhez. Ez a kis sorok száma esetén lehet jó, de több ezer vagy több millió sor esetén nem hatékony.
Egy másik anti-minta a skaláris függvények használata, amelyek hasonló becslési és végrehajtási problémákkal rendelkeznek. A Microsoft jelentős teljesítménybeli fejlesztéseket hajtott végre az intelligens lekérdezésfeldolgozással a 140- és 150-ös kompatibilitási szinteken.
SARGability
A relációs adatbázisokban a SARGable kifejezés egy olyan predikátumra (WHERE záradékra) hivatkozik, amely index használatával gyorsíthatja a lekérdezések végrehajtását. A helyes formátumú predikátumokat "Keresési argumentumoknak" vagy SARG-knak nevezzük. Az SQL Serverben a SARG használata azt jelenti, hogy az optimalizáló egy nemclustered indexet használ a SARG-ban hivatkozott oszlopon egy SEEK művelethez, ahelyett, hogy a teljes indexet vagy táblát beolvassa egy érték lekéréséhez.
A SARG jelenléte nem garantálja az index használatát egy „keresés” folyamán. Az optimalizáló költségszámítási algoritmusai továbbra is megállapíthatják, hogy az index túl drága, különösen akkor, ha egy SARG a tábla sorainak nagy százalékára hivatkozik. A SARG hiánya azt jelenti, hogy az optimalizáló nem értékeli ki a SEEK értéket egy nemclustered indexen.
A nem SARGable kifejezések közé tartoznak például a karakterlánc elején helyettesítő karaktert használó záradékkal rendelkező LIKE kifejezések, például WHERE lastName LIKE '%SMITH%'. Egyéb nem SARGable predikátumok akkor fordulnak elő, ha függvényeket használnak egy oszlopon, például WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. Ezeket a lekérdezéseket általában az index- vagy táblavizsgálatok végrehajtási terveinek vizsgálatával azonosítják, ahol az elvárt keresések helyett szkennelések történnek.
Lekérdezés és végrehajtási terv képernyőképe egy nem optimalizálható függvény használatával.
A lekérdezés záradékában használt WHERE oszlopban van egy index, és bár a fenti végrehajtási tervben használják, láthatja, hogy az indexet beolvassák, ami azt jelenti, hogy a teljes indexet olvassák be. A predikátumban lévő LEFT függvény nem SARGable-lé teszi ezt a kifejezést. Az optimalizáló nem fogja kiértékelni az indexkeresést a Város oszlop indexén.
Ez a lekérdezés egy SARGable predikátum használatára írható. Az optimalizáló ezután kiértékel egy keresést a City oszlop indexén. Az indexkeresési operátor ebben az esetben egy kisebb sorhalmazt olvasna be.
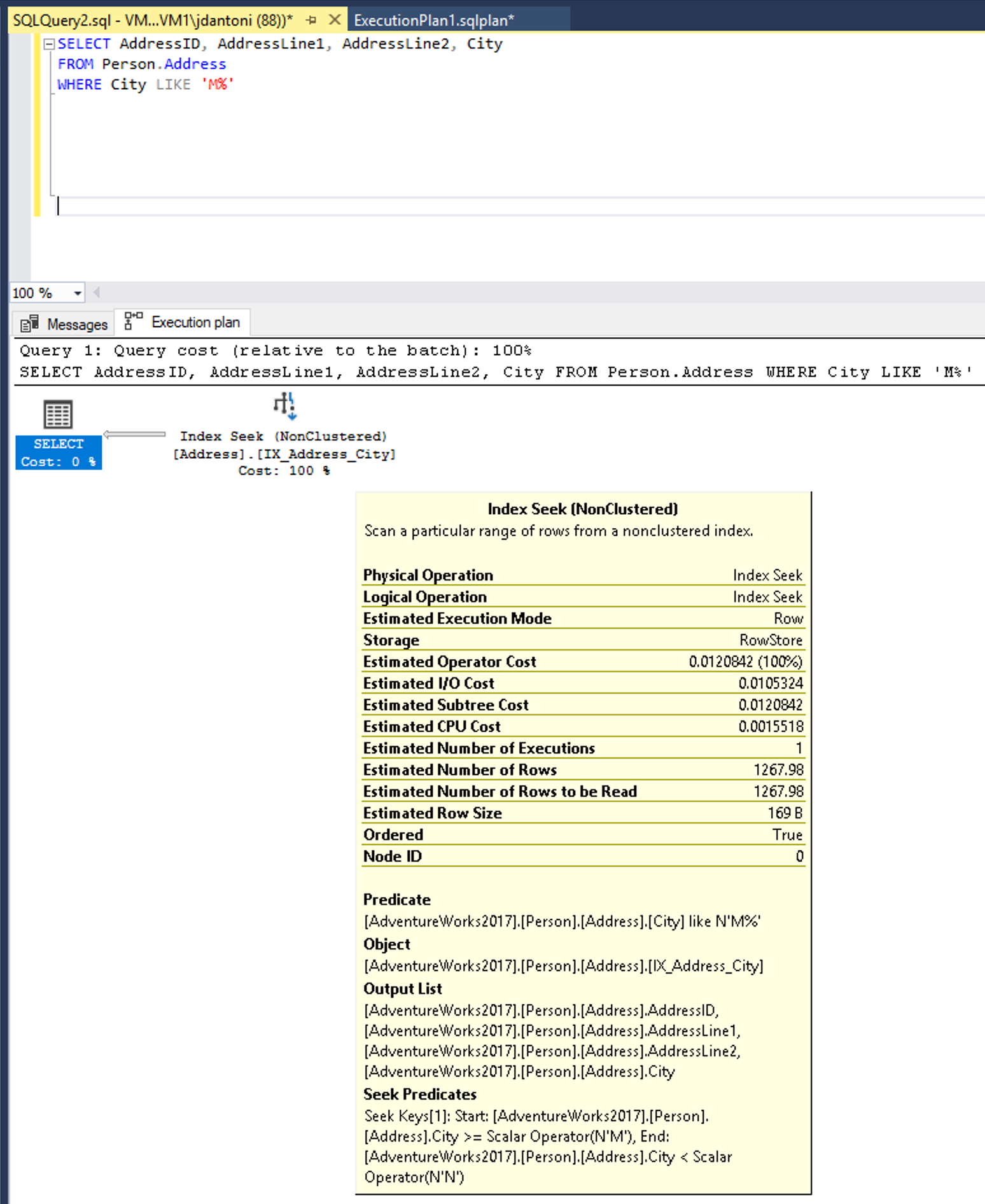
A LEFT függvény LIKE-vé módosítása indexkeresést eredményez.
Megjegyzés
Ebben a példában a LIKE kulcsszó nem rendelkezik helyettesítő karakterrel a bal oldalon, ezért az M betűvel kezdődő városokat keresi. Ha "kétoldalúan" vagy helyettesítő karakterrel ('%M%' vagy '%M') kezdődne, akkor nem lenne SARGable. A keresési műveletről azt becsülik, hogy 1,267 sort ad vissza, ami körülbelül 15%-a a nem "SARGable" predikátummal rendelkező lekérdezés becslésének.
Néhány más adatbázis-fejlesztési minta az adatbázist szolgáltatásként kezeli, nem pedig adattárként. Ha adatbázist használ az adatok JSON-ra konvertálására, sztringek manipulálására vagy összetett számítások elvégzésére, az túlzott processzorhasználathoz és nagyobb késéshez vezethet. Azok a lekérdezések, amelyek megpróbálják lekérni az összes rekordot, majd számításokat végeznek az adatbázisban, túlzott IO- és CPU-használathoz vezethetnek. Ideális esetben az adatbázist adatelérési műveletekhez és optimalizált adatbázis-szerkezetekhez, például aggregációhoz kell használnia.
Hiányzó indexek
Az adatbázis-rendszergazdák leggyakoribb teljesítményproblémái a hasznos indexek hiányából erednek, ami miatt a motor a szükségesnél több oldalt olvas a lekérdezési eredmények visszaadásához. Bár az indexek erőforrásokat használnak fel (ami befolyásolja az írási teljesítményt és a tárhelyet), a teljesítményük gyakran meghaladja a többletköltséget. Az ezekkel a problémákkal kapcsolatos végrehajtási terveket a lekérdezési operátor Clustered Index Scan vagy a Nonclustered Index Seek és Key Lookup kombinációja által lehet azonosítani, ami egy meglévő index hiányzó oszlopait jelzi.
Az adatbázismotor segít a hiányzó indexek jelentésében a végrehajtási tervekben. Az ajánlott indexek neve és részletei a dinamikus felügyeleti nézetben sys.dm_db_missing_index_detailsérhetők el. Más DMV-k, mint a sys.dm_db_index_usage_stats és a sys.dm_db_index_operational_stats, szükségesnél is jobban kihangsúlyozzák a meglévő indexek kihasználtságát.
A nem használt index elvetése ésszerű lehet. A hiányzó indexes DMV-knek és a tervekkel kapcsolatos figyelmeztetéseknek a lekérdezések finomhangolásához kiindulási pontoknak kell lenniük. Fontos, hogy megismerje a kulcsfontosságú lekérdezéseket, és indexeket hozzon létre a támogatásukhoz. Nem ajánlott az összes hiányzó index létrehozása a környezet kiértékelése nélkül.
Hiányzó és elavult statisztikák
Az oszlop- és indexstatisztika fontossága a lekérdezésoptimalizáló számára elengedhetetlen. Emellett fontos felismerni azokat a feltételeket is, amelyek elavult statisztikákhoz vezethetnek, és hogy ez a probléma hogyan nyilvánulhat meg az SQL Serverben. Az Azure SQL-ajánlatok alapértelmezés szerint on értékre vannak állítva az automatikus frissítési statisztikák. Az SQL Server 2016 előtt az automatikus frissítési statisztikák alapértelmezett viselkedése az volt, hogy addig nem frissítik a statisztikákat, amíg az index oszlopainak módosításainak száma a tábla sorainak körülbelül 20% értékével nem egyenlő. Ez a viselkedés jelentős adatmódosításokat eredményezhet, amelyek a statisztikák frissítése nélkül módosítják a lekérdezési teljesítményt, ami elavult statisztikákon alapuló optimálisnál rosszabb tervekhez vezethet.
Az SQL Server 2016 előtt a 2371-es nyomkövetési jelzővel dinamikus értékre módosíthatja a szükséges számú módosítást, így a tábla növekedése során a statisztikai frissítés indításához szükséges sormódosítások százalékos aránya csökkent. Az SQL Server, az Azure SQL Database és az Azure SQL Managed Instance újabb verziói alapértelmezés szerint támogatják ezt a viselkedést. A dinamikus felügyeleti függvény sys.dm_db_stats_properties megjeleníti a statisztikák legutóbbi frissítésének időpontját és a legutóbbi frissítés óta eltelt módosítások számát, így gyorsan azonosíthatja azokat a statisztikákat, amelyek manuális frissítéseket igényelhetnek.
Gyenge optimalizáló lehetőségek
Bár a lekérdezésoptimalizáló jó munkát végez a legtöbb lekérdezés optimalizálásában, vannak olyan határesetek, amikor a költségalapú optimalizáló jelentős döntéseket hozhat, amelyek nincsenek teljesen megértve. Ennek számos módja van, például lekérdezési tippek, nyomkövetési jelzők, végrehajtási terv kényszerítése és egyéb kiigazítások használata a stabil és optimális lekérdezési terv elérése érdekében. A Microsoft egy támogatási csapattal rendelkezik, amely segít elháríteni ezeket a forgatókönyveket.
Az alábbi példában az AdventureWorks2017 adatbázisból egy lekérdezési javaslatot használunk, amely arra utasítja az adatbázis-optimalizálót, hogy mindig a Seattle városnevet használja. Ez az útmutatás nem garantálja a legjobb végrehajtási tervet minden városértékhez, de kiszámítható. A "Seattle" értéke a @city_name csak az optimalizálás során lesz felhasználva. A végrehajtás során a rendszer a tényleges megadott értéket (‘Ascheim’) használja.
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Ahogy a példában látható, a lekérdezés egy tippet (záradékot OPTION ) használ arra, hogy az optimalizáló egy adott változóértéket használjon a végrehajtási terv létrehozásához.
Paraméter lekérdezés
Az SQL Server gyorsítótárazza a lekérdezés-végrehajtási terveket későbbi használatra. Mivel a végrehajtási terv lekérési folyamata egy lekérdezés kivonatértékén alapul, a lekérdezés szövegének azonosnak kell lennie a gyorsítótárazott terv lekérdezésének minden végrehajtásához. Ha több értéket szeretne támogatni ugyanabban a lekérdezésben, sok fejlesztő a tárolt eljárásokon keresztül átadott paramétereket használja az alábbi példában látható módon:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
A lekérdezések explicit módon paraméterezhetők az sp_executesql eljárás használatával. Az egyes lekérdezések explicit paraméterezése azonban az alkalmazáson keresztül történik a PREPARE és az EXECUTE valamilyen formában (az API-tól függően). Amikor az adatbázismotor először hajtja végre a lekérdezést, optimalizálja a lekérdezést a paraméter kezdeti értéke, jelen esetben a 42 alapján. Ez a paraméterfigyelésnek nevezett viselkedés lehetővé teszi, hogy a lekérdezések összeállításának általános számítási terhelése csökkenjen a kiszolgálón. Ha azonban eltérés van az adatok között, a lekérdezés teljesítménye nagy mértékben változhat.
Egy 10 millió rekordot tartalmazó táblában például 99% 1 azonosítóval rendelkezik, a másik 1% pedig egyedi számok, a teljesítmény azon alapul, hogy eredetileg melyik azonosítót használták a lekérdezés optimalizálásához. Ez a vadul ingadozó teljesítmény adateloszlást jelez, és nem jár együtt a paraméter sniffinggel kapcsolatos eredendő problémákkal. Ez a viselkedés meglehetősen gyakori teljesítményprobléma, amellyel tisztában kell lennie. Ismernie kell a probléma megoldásának lehetőségeit. Van néhány módszer a probléma megoldására, de mindegyik kompromisszumokkal jár:
- Használja a
RECOMPILEutasítást a lekérdezésben, vagy aWITH RECOMPILEvégrehajtási opciót a tárolt eljárásokban. Ez a tipp azt eredményezi, hogy a lekérdezés vagy az eljárás minden végrehajtásakor újrafordításra kerül, ami növeli a cpu-kihasználtságot a kiszolgálón, de mindig az aktuális paraméterértéket fogja használni. - A
OPTIMIZE FOR UNKNOWNlekérdezési tippet használhatja. Ez a tipp azt eredményezi, hogy az optimalizáló úgy dönt, hogy nem szippantja a paramétereket, és összehasonlítja az értéket az oszlopadatok hisztogramjával. Ez a lehetőség nem a lehető legjobb tervet biztosítja, de konzisztens végrehajtási tervet tesz lehetővé. - Írja újra az eljárást vagy a lekérdezéseket úgy, hogy a paraméterértékek köré logikát épít be, és csak az ismert problémás paramétereknél alkalmazza a RECOMPILE utasítást. Az alábbi példában, ha a SalesPersonID paraméter NULL értékű, a lekérdezés a
OPTION (RECOMPILE)-vel lesz futtatva.
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Ez a példa jó megoldás, de meglehetősen nagy fejlesztési erőfeszítést és az adatterjesztés szilárd megértését igényli. Karbantartást igényel az adatok változásakor.