Szemantikai nyelvi modellek
Megjegyzés:
További részletekért tekintse meg a Szöveg és képek lapot!
Az NLP fejlődése következtében a tokenek szemantikai kapcsolatát beágyazó modellek betanítása erős mélytanulási nyelvi modellek megjelenéséhez vezetett. Ezeknek a modelleknek a középpontjában a nyelvi elemek vektorokként (többértékű számtömbök) való kódolása, más néven beágyazások, áll.
Ez a vektoralapú megközelítés a szöveg modellezéséhez olyan technikákkal vált általánossá, mint a Word2Vec és a GloVe, amelyekben a szöveg jogkivonatai sűrű vektorként jelennek meg több dimenzióval. A modell betanítása során a dimenzióértékek az egyes tokenek szemantikai jellemzőit tükrözik a betanítási szövegben való használatuk alapján. A vektorok közötti matematikai kapcsolatok ezután kihasználhatók a gyakori szövegelemzési feladatok hatékonyabb végrehajtásához, mint a régebbi, tisztán statisztikai technikák. Ennek a megközelítésnek egy újabb előrelépése az, hogy egy olyan technikát használunk, amit "attention"-nek nevezünk, hogy az egyes tokeneket kontextusban vegyük figyelembe, és kiszámítsuk a körülöttük lévő tokenek hatását. Az eredményül kapott környezetfüggő beágyazások, például a GPT modellcsaládban találhatóak, biztosítják a modern generatív AI alapját.
Szöveg vektorként való ábrázolása
A vektorok többdimenziós térben lévő pontokat jelölnek, amelyeket koordináták határoznak meg több tengely mentén. Minden vektor a forrás irányát és távolságát írja le. A szemantikailag hasonló tokéneknek olyan vektorokat kell eredményezniük, amelyek hasonló tájolásúak – más szóval hasonló irányba mutatnak.
Vegyük például a következő háromdimenziós beágyazásokat néhány gyakori szóhoz:
| Word | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Ezeket a vektorokat háromdimenziós térben vizualizálhatjuk az itt látható módon:

A vektorok "dog""cat" hasonlóak (mind a háziállatok, mind "puppy""kitten" a fiatal állatok). A "tree", "young" és ball" szavak eltérő vektoros tájolással rendelkeznek, ami tükrözi különböző szemantikai jelentésüket.
A vektorokban kódolt szemantikai jellemzők lehetővé teszik a szavak összehasonlítását és elemzési összehasonlítást lehetővé tevő vektoralapú műveletek használatát.
Kapcsolódó kifejezések keresése
Mivel a vektorok tájolását a dimenzióértékek határozzák meg, a hasonló szemantikai jelentésű szavak általában hasonló tájolásúak. Ez azt jelenti, hogy olyan számításokat használhat, mint a vektorok közötti koszinusz-hasonlóság , hogy értelmes összehasonlításokat végezhessenek.
Ha például meg szeretné határozni a "páratlant" a kettő között "dog", "cat"és "tree", kiszámíthatja a vektorpárok közötti koszinuszos hasonlóságot. A koszinusz hasonlóságát a következőképpen számítjuk ki:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Hol A · B van a pont szorzata, és ||A|| az A vektor nagysága.
A három szó közötti hasonlóságok kiszámítása:
dog[0,8, 0,6, 0,1] éscat[0,7, 0,5, 0,2]:- Pont termék: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
-
dognagysága: √(0.8² + 0.6² + 0.1²) = √(0.64 + 0.36 + 0.01) = √1.01 ≈ 1.005 -
catnagysága: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Koszinusz hasonlóság: 0,88 / (1,005 × 0,883) ≈ 0,992 (magas hasonlóság)
dog[0.8, 0.6, 0.1] éstree[0.2, 0.1, 0,9]:- Pont termék: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- A
treevektor nagysága: √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Koszinusz hasonlóság: 0,31 / (1,005 × 0,927) ≈ 0,333 (alacsony hasonlóság)
cat[0.7, 0.5, 0.2] éstree[0.2, 0.1, 0,9]:- Pont termék: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Koszinusz hasonlóság: 0,37 / (0,883 × 0,927) ≈ 0,452 (alacsony hasonlóság)
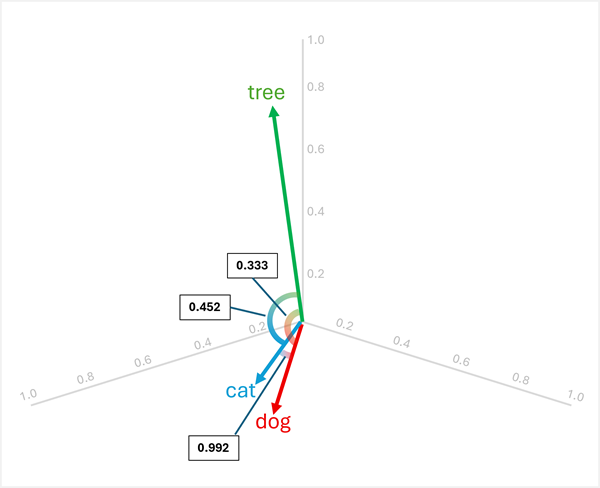
Az eredmények azt mutatják, hogy "dog" és "cat" nagyon hasonlóak (0,992), míg "tree" kevésbé hasonlít mind "dog"-ra (0,333), mind "cat"-re (0,452). Ezért tree egyértelműen kilóg a sorból.
Vektorfordítás összeadással és kivonással
Új vektoralapú eredmények létrehozásához hozzáadhat vagy kivonhat vektorokat; amely ezután egyező vektorokkal rendelkező tokenek keresésére használható. Ez a technika lehetővé teszi az intuitív aritmetikai alapú logikát a nyelvi kapcsolatokon alapuló megfelelő kifejezések meghatározásához.
Például a korábbi vektorok használatával:
-
dog+young= [0,8, 0,6, 0,1] + [0,1, 0,1, 0,3] = [0,9, 0,7, 0,4] =puppy -
cat+young= [0,7, 0,5, 0,2] + [0,1, 0,1, 0,3] = [0,8, 0,6, 0,5] =kitten
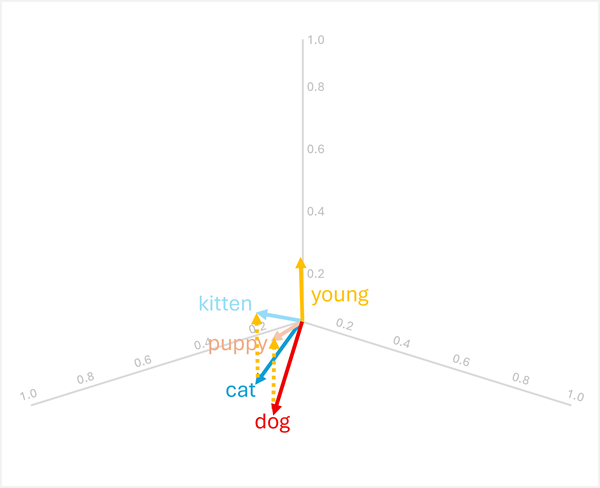
Ezek a műveletek azért működnek, mert a vektor "young" egy felnőtt állat szemantikai transzformációját kódolja a fiatal megfelelőjéhez.
Megjegyzés:
A gyakorlatban a vektor aritmetika ritkán hoz létre pontos egyezéseket; ehelyett arra a szóra keresne rá, amelynek a vektora a legközelebbi (leginkább hasonló) az eredményhez.
Az aritmetika fordítottan is működik:
-
puppy-young= [0,9, 0,7, 0,4] - [0,1, 0,1, 0,3] = [0,8, 0,6, 0,1] =dog -
kitten-young= [0,8, 0,6, 0,5] - [0,1, 0,1, 0,3] = [0,7, 0,5, 0,2] =cat
Analóg érvelés
A vektoraritmetika analógiai kérdések megválaszolására is képes, például: "puppy úgy van dog-hez, mint kitten".
Ennek megoldásához számítsa ki a következőt: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0,1, -0,1, 0,1] + [0,8, 0,6, 0,1]
- = [0,7, 0,5, 0,2]
- =
cat
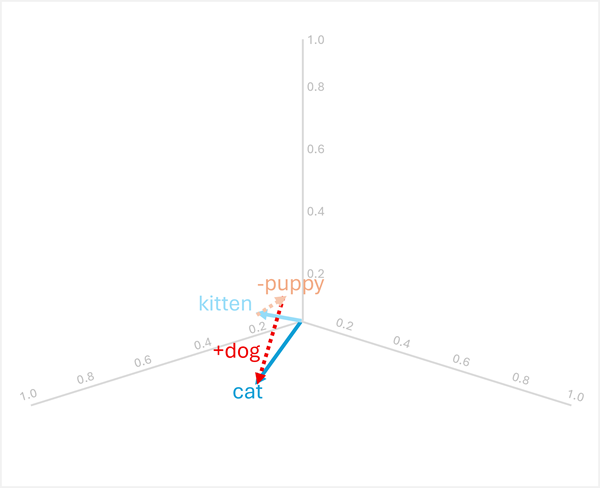
Ezek a példák bemutatják, hogy a vektorműveletek hogyan képesek rögzíteni a nyelvi kapcsolatokat, és hogyan lehet érvelést végezni a szemantikai mintákról.
Szemantikai modellek használata szövegelemzéshez
A vektoralapú szemantikai modellek számos gyakori szövegelemzési feladathoz nyújtanak hatékony képességeket.
Szövegösszesítés
A szemantikai beágyazások lehetővé teszik a kivonatoló összegzést azáltal, hogy a mondatokat olyan vektorokkal azonosítják, amelyek a legreprezentálóbbak a teljes dokumentumra. Az egyes mondatok vektorként való kódolásával (gyakran az alkotó szavak beágyazásának átlagolásával vagy készletezésével) kiszámíthatja, hogy mely mondatok a legfontosabbak a dokumentum jelentésében. Ezek a központi mondatok kinyerhetők úgy, hogy a fő témákat rögzítő összegzést alkotjanak.
Kulcsszó kivonása
A vektoros hasonlóság az egyes szavak beágyazásának és a dokumentum általános szemantikai ábrázolásának összehasonlításával azonosíthatja a dokumentum legfontosabb kifejezéseit. Azok a szavak, amelyek vektorai leginkább a dokumentumvektorhoz hasonlítanak, vagy a dokumentum összes szóvektorának figyelembevételekor a legközpontibbak, valószínűleg a fő témákat képviselő kulcskifejezések.
Elnevezett entitásfelismerés
A szemantikai modellek úgy finomhangolhatók, hogy felismerjék a nevesített entitásokat (személyeket, szervezeteket, helyeket stb.) a hasonló entitástípusokat csoportosító vektorábrázolások tanulásával. A következtetés során a modell megvizsgálja az egyes tokenek embeddingjét és környezetét annak megállapítására, hogy képvisel-e egy elnevezett entitást, és ha igen, milyet.
Szövegbesorolás
Az olyan feladatok esetében, mint a hangulatelemzés vagy a témakör kategorizálása, a dokumentumok összesítő vektorként (például a dokumentumban lévő összes szóbeágyazás középértékének) jelölhetők. Ezek a dokumentumvektorok ezután használhatók a gépi tanulási osztályozók funkcióiként, vagy összehasonlíthatók közvetlenül az osztály prototípusvektoraival kategóriák hozzárendeléséhez. Mivel a szemantikailag hasonló dokumentumok hasonló vektoros tájolással rendelkeznek, ez a megközelítés hatékonyan csoportosítja a kapcsolódó tartalmakat, és megkülönbözteti a különböző kategóriákat.