A lehetséges károk elhárítása
Miután meghatározta az alaptervet és a megoldás által generált káros kimenet mérésének módját, lépéseket tehet a lehetséges károk mérséklésére, és szükség esetén újra tesztelheti a módosított rendszert, és összehasonlíthatja a kárszinteket az alapkonfigurációval.
A generatív AI-megoldások lehetséges károsodásainak elhárítása rétegzett megközelítéssel jár, amelyben négy rétegben alkalmazhatók a kárenyhítési technikák, ahogy az itt látható:
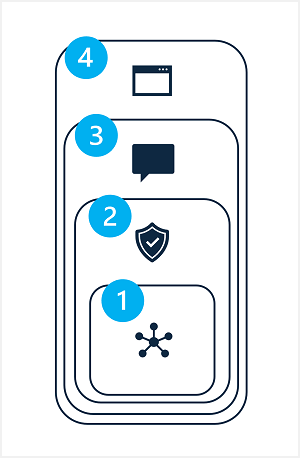
- Modell
- Széf ty System
- Metaprompt és földelés
- Felhasználó felület
1: A modellréteg
A modellréteg a megoldás középpontjában lévő generatív AI-modell(ek)ből áll. Előfordulhat például, hogy a megoldás egy olyan modell köré épül, mint a GPT-4.
A modellrétegben alkalmazható kockázatcsökkentések a következők:
- A kívánt megoldáshoz megfelelő modell kiválasztása. Bár például a GPT-4 hatékony és sokoldalú modell lehet, egy olyan megoldásban, amely csak a kis méretű, konkrét szöveges bemenetek besorolásához szükséges, az egyszerűbb modellek a szükséges funkciókat is biztosíthatják, így kisebb a káros tartalomgenerálás kockázata.
- Egy alapszintű modell finomhangolása saját betanítási adatokkal, hogy az általa generált válaszok nagyobb valószínűséggel relevánsak legyenek, és a megoldásforgatókönyvre terjedjenek ki.
2: A biztonsági rendszer rétege
A biztonsági rendszer rétege platformszintű konfigurációkat és képességeket tartalmaz, amelyek segítenek enyhíteni a károkat. Az Azure OpenAI szolgáltatás például támogatja azokat a tartalomszűrőket, amelyek a tartalom négy súlyossági szintre (biztonságos, alacsony, közepes és magas) történő besorolásán alapuló kérések és válaszok letiltására vonatkozó feltételeket alkalmaznak a lehetséges ártalom négy kategóriájára (gyűlölet, szexuális, erőszak és önsérelem) vonatkozóan.
Egyéb biztonsági rendszerréteg-kockázatcsökkentések tartalmazhatnak visszaélésészlelési algoritmusokat annak megállapítására, hogy a megoldást szisztematikusan használják-e (például nagy mennyiségű automatizált kéréssel egy robottól), valamint riasztási értesítéseket, amelyek gyors választ adnak a rendszer esetleges visszaélésére vagy káros viselkedésére.
3: A metaprompt és a földelő réteg
A metaprompt és a földelő réteg a modellnek küldött kérések felépítésére összpontosít. Az ezen a rétegen alkalmazható kárenyhítési technikák a következők:
- A modell viselkedési paramétereit meghatározó metapromptok vagy rendszerbemenetek megadása.
- A parancssori tervezés alkalmazása földelési adatok beviteli kérésekhez való hozzáadásához, maximalizálva a releváns, nemharmális kimenetek valószínűségét.
- A lekérdezési kiterjesztett generációs (RAG) módszer használatával környezeti adatokat kér le megbízható adatforrásokból, és belefoglalja azokat a kérésekbe.
4: A felhasználói felület rétege
A felhasználói felület rétege tartalmazza azt a szoftveralkalmazást, amelyen keresztül a felhasználók a generatív AI-modellel kommunikálnak, valamint dokumentációt vagy egyéb felhasználói biztosítékot, amely leírja a megoldás használatát a felhasználók és az érdekelt felek számára.
Ha úgy tervezi meg az alkalmazás felhasználói felületét, hogy bizonyos témákra vagy típusokra korlátozza a bemeneteket, vagy a bemeneti és kimeneti ellenőrzés alkalmazása csökkenti a potenciálisan káros válaszok kockázatát.
A generatív AI-megoldások dokumentációjának és egyéb leírásainak megfelelően átláthatónak kell lenniük a rendszer képességeiről és korlátairól, az alapul szolgáló modellekről, valamint azokról a lehetséges károkról, amelyek nem mindig kezelhetők az Ön által alkalmazott kockázatcsökkentő intézkedésekkel.