Bármely adat indexelése az Azure AI Search leküldéses API-val
A REST API a legrugalmasabb módja az adatok Azure AI Search-indexbe való leküldésének. Bármilyen programozási nyelvet használhat, vagy interaktív módon bármely olyan alkalmazással, amely JSON-kérelmeket tehet közzé egy végponton.
Itt megtudhatja, hogyan használhatja hatékonyan a REST API-t, és megismerheti az elérhető műveleteket. Ezután áttekintheti a .NET Core-kódot, és megtudhatja, hogyan optimalizálhatja a nagy mennyiségű adat API-n keresztüli hozzáadását.
Támogatott REST API-műveletek
Az AI Search két támogatott REST API-t biztosít. Keresési és felügyeleti API-k. Ez a modul a keresési REST API-kra összpontosít, amelyek a keresés öt funkcióján nyújtanak műveleteket:
| Szolgáltatás | Üzemeltetés |
|---|---|
| Index | Létrehozás, törlés, frissítés és konfigurálás. |
| Bizonylat | Lekérés, hozzáadás, frissítés és törlés. |
| Indexelő | Adatforrások konfigurálása és ütemezés korlátozott adatforrásokon. |
| Skillset | Lekérés, létrehozás, törlés, lista és frissítés. |
| Szinonimák térképe | Lekérés, létrehozás, törlés, lista és frissítés. |
A keresési REST API meghívása
Ha a keresési API-k bármelyikét meg szeretné hívni, a következőkre van szüksége:
- Használja a keresőszolgáltatás által biztosított HTTPS-végpontot (az alapértelmezett 443-as porton keresztül), az api-verziót az URI-ban kell tartalmaznia.
- A kérelem fejlécének tartalmaznia kell egy api-key attribútumot.
A végpont, az api-verzió és az api-kulcs megkereséséhez nyissa meg az Azure Portalt.

A portálon keresse meg a keresési szolgáltatást, majd válassza a Kereséskezelő lehetőséget. A REST API-végpont a Kérelem URL-cím mezőjében található. Az URL első része a végpont (például https://azsearchtest.search.windows.net), és a lekérdezési sztring az api-version (például api-version=2023-07-01-Preview) értéket jeleníti meg.

A api-key bal oldali kereséshez válassza a Kulcsok lehetőséget. Az elsődleges vagy másodlagos rendszergazdai kulcs akkor használható, ha a REST API-t használja az index lekérdezése helyett. Ha csak egy indexben kell keresnie, létrehozhat és használhat lekérdezési kulcsokat.
Egy index adatainak hozzáadásához, frissítéséhez vagy törléséhez rendszergazdai kulcsot kell használnia.
Adatok hozzáadása indexhez
Http POST-kérés használata az indexelési funkcióval ebben a formátumban:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
A kérés törzsének tudatnia kell a REST-végpontkal a dokumentumon végrehajtandó műveletet, a műveletet alkalmazni kívánt dokumentumot és a használni kívánt adatokat.
A JSON formátumának a következő formátumban kell lennie:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Művelet | Leírás |
|---|---|
| upload | Az SQL-ben található upserthez hasonlóan a dokumentum létrejön vagy lecserélődik. |
| Egyesítése | A meglévő dokumentum egyesítése a megadott mezőkkel. Az egyesítés sikertelen lesz, ha nem található dokumentum. |
| mergeOrUpload | Az egyesítése frissíti a meglévő dokumentumot a megadott mezőkkel, és feltölti, ha a dokumentum nem létezik. |
| törlés | Törli a teljes dokumentumot, csak a key_field_name kell megadnia. |
Ha a kérés sikeres, az API egy 200-es állapotkódot ad vissza.
Feljegyzés
Az összes válaszkód és hibaüzenet teljes listáját lásd: Dokumentumok hozzáadása, frissítése vagy törlése (Azure AI Search REST API)
Ez a példa JSON feltölti az ügyfélrekordot az előző leckében:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
Annyi dokumentumot vehet fel az értéktömbbe, amennyit csak szeretne. Az optimális teljesítmény érdekében azonban fontolja meg a dokumentumok legfeljebb 1000 dokumentum vagy 16 MB teljes méretű kötegelését a kérelmekben.
A .NET Core használata az adatok indexelésére
A legjobb teljesítmény érdekében használja a legújabb Azure.Search.Document ügyfélkódtárat, amely jelenleg a 11-es verzió. Az ügyfélkódtárat a NuGettel telepítheti:
dotnet add package Azure.Search.Documents --version 11.4.0
Az index teljesítménye hat fő tényezőn alapul:
- A keresési szolgáltatási szint, valamint az engedélyezett replikák és partíciók.
- Az indexséma összetettsége. Csökkentse, hogy az egyes mezők hány tulajdonsággal rendelkeznek (kereshető, facetable, rendezhető).
- Az egyes kötegekben lévő dokumentumok száma, a legjobb méret az indexsémától és a dokumentumok méretétől függ.
- Hogyan többszálú a megközelítés.
- Hibák és szabályozás kezelése. Exponenciális backoff újrapróbálkozási stratégiát használjon.
- Ahol az adatok találhatók, próbálja indexelni az adatokat a keresési index közelében. Futtathat például feltöltéseket az Azure-környezetből.
Az optimális kötegméret meghatározása
Mivel a legjobb kötegméret meghatározása kulcsfontosságú tényező a teljesítmény javításához, tekintsük át a kód egyik megközelítését.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
A módszer a köteg méretének növelése és az érvényes válasz fogadásához szükséges idő monitorozása. A kód 100 és 1000 közötti ciklusokat tartalmaz 100 dokumentumlépésben. Az egyes kötegméretek esetében a dokumentum méretét, a válaszkéréshez szükséges időt és az MB-onkénti átlagos időt adja ki. A kód futtatása az alábbihoz hasonló eredményeket ad:
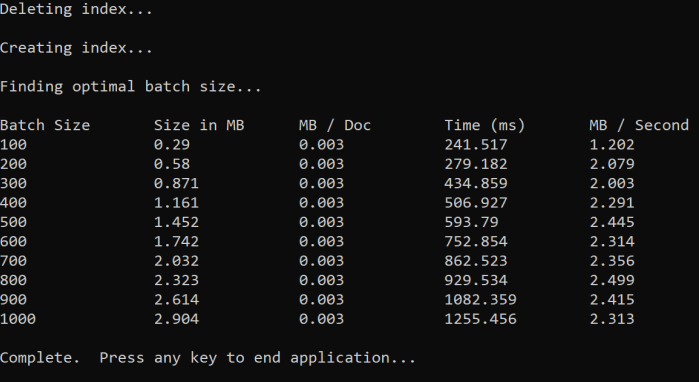
A fenti példában az átviteli sebességhez a legjobb kötegméret 2,499 MB/másodperc, kötegenként 800 dokumentum.
Exponenciális backoff újrapróbálkozási stratégia implementálása
Ha az index túlterhelés miatt kezdi szabályozni a kérelmeket, az 503-as (nagy terhelés miatt elutasított) vagy 207-as (egyes dokumentumok nem sikerültek a kötegben) állapottal válaszol. Ezeket a válaszokat kell kezelnie, és jó stratégia a visszalépés. A visszatartás azt jelenti, hogy egy ideig szünetelteti a kérés újrapróbálkozását. Ha ezt az időt minden egyes hiba esetében megnöveli, exponenciálisan vissza fog kapcsolni.
Tekintse meg ezt a kódot:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
A kód nyomon követi a sikertelen dokumentumokat egy kötegben. Ha hiba történik, megvárja a késést, majd megduplázza a következő hiba késleltetését.
Végül, van egy maximális számú újrapróbálkozás, és ha ez a maximális szám eléri a program létezik.
Menetkezelés használata a teljesítmény javítása érdekében
A dokumentumfeltöltési alkalmazást a fenti háttérstratégia szálkezeléses megközelítéssel történő átfésülésével fejezheti be. Íme néhány példakód:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Ez a kód aszinkron hívásokat használ egy olyan függvényhez ExponentialBackoffAsync , amely implementálja a háttérstratégiát. A függvényt szálak használatával hívhatja meg, például a processzor magjainak számát. Amikor a maximális számú szálat használták, a kód megvárja, amíg a szálak befejeződnek. Ezután létrehoz egy új szálat, amíg az összes dokumentum fel nem tölthető.