Mi az a besorolás?
A bináris besorolás két kategóriával való besorolás. A betegeket például nem diabéteszes vagy cukorbetegként címkézhetjük.
Az osztály előrejelzése úgy történik, hogy az egyes lehetséges osztályok valószínűségét 0 (lehetetlen) és 1 (bizonyos) közötti értékként határozza meg. Az összes osztály teljes valószínűsége mindig 1, mivel a beteg egyértelműen diabéteszes vagy nem diabéteszes. Tehát, ha a diabéteszes beteg előrejelzett valószínűsége 0,3, akkor 0,7-es a valószínűsége annak, hogy a beteg nem cukorbeteg.
Az előrejelzett osztály meghatározásához egy küszöbértéket (gyakran 0,5) használnak. Ha a pozitív osztály (ebben az esetben a diabéteszes) előrejelzett valószínűsége nagyobb, mint a küszöbérték, akkor a diabéteszes besorolás lesz előre jelezve.
Besorolási modell betanítása és értékelése
A besorolás egy felügyelt gépi tanulási módszer példája, ami azt jelenti, hogy olyan adatokra támaszkodik, amelyek ismert funkcióértékeket és ismert címkeértékeket tartalmaznak. Ebben a példában a funkcióértékek a betegek diagnosztikai mérései, a címkeértékek pedig a nem diabéteszes vagy diabéteszesek besorolását képezik. A besorolási algoritmus az adatok egy részhalmazát egy olyan függvénybe illeszti, amely kiszámítja az egyes osztálycímkék valószínűségét a funkcióértékekből. A rendszer a fennmaradó adatokat a modell kiértékeléséhez használja a szolgáltatásokból származó előrejelzések és az ismert osztálycímkék összehasonlításával.
Egy egyszerű példa
Tekintsünk át egy példát, amely segít elmagyarázni a fő alapelveket. Tegyük fel, hogy a következő betegadatokkal rendelkezünk, amelyek egyetlen jellemzőből (vércukorszint) és 0 osztálycímkéből állnak a nem cukorbetegek esetében, 1 diabéteszes esetén.
| Vércukorszint | Cukorbeteg |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 0 |
| 102 | 0 |
| 115 | 0 |
| 107 | 0 |
| 87 | 0 |
| 120 | 0 |
| 83 | 0 |
| 119 | 0 |
| 104 | 0 |
| 105 | 0 |
| 86 | 0 |
| 109 | 0 |
Az első nyolc megfigyelést egy besorolási modell betanítására használjuk, és először ábrázoljuk a vércukorszint jellemzőjét (x) és az előrejelzett diabéteszes címkét (y).
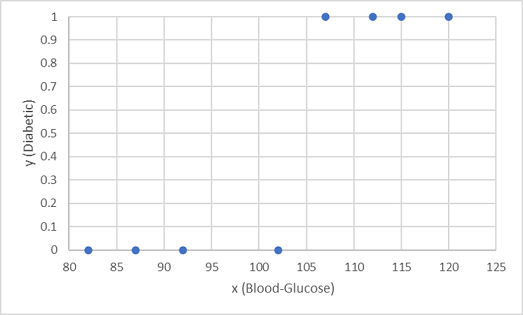
Olyan függvényre van szükségünk, amely x alapján számítja ki az y valószínűségi értékét (más szóval az f(x) = y függvényre van szükségünk). A diagramon látható, hogy az alacsony vércukorszinttel rendelkező betegek mind nem diabéteszesek, míg a magasabb vércukorszinttel rendelkező betegek cukorbetegek. Úgy tűnik, minél magasabb a vércukorszint, annál valószínűbb, hogy a beteg cukorbeteg, az inflekciós pont valahol 100 és 110 között van. El kell illesztenünk egy függvényt, amely 0 és 1 közötti értéket számít ki az y értékhez.
Az egyik ilyen függvény egy logisztikai függvény, amely szigmoidális (S-alakú) görbét alkot.
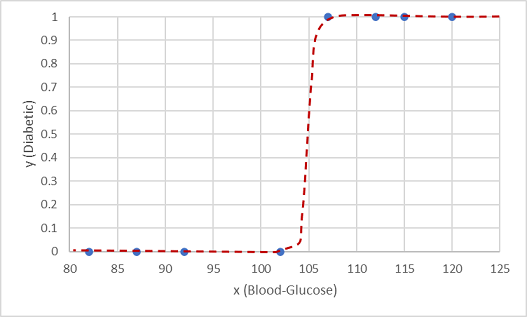
Most a függvény segítségével kiszámíthatjuk az y valószínűségi értékét, ami azt jelenti, hogy a beteg diabéteszes, az x tetszőleges értékéből az x függvényvonalának pontjának megkeresésével. 0,5-ös küszöbértéket állíthatunk be az osztálycímke előrejelzésének kezdőpontjaként.
Teszteljük a két adatértékkel, amelyet visszatartottunk.
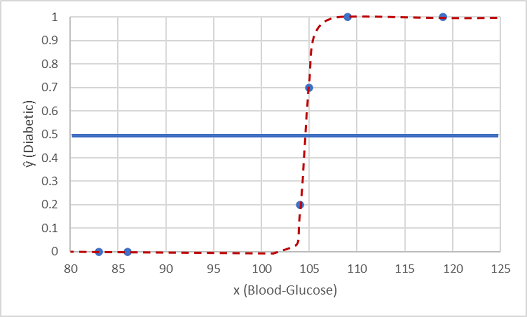
A küszöbérték alatt ábrázolt pontok 0 (nem diabéteszes) előrejelzett osztályt eredményeznek, a vonal feletti pontok pedig 1 -et (diabéteszesek) jeleznek előre.
Most összehasonlíthatjuk a modellbe ágyazott logisztikai függvényen alapuló címke-előrejelzéseket (ŷ vagy "y-hat") a tényleges osztályfeliratokkal (y).
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 0 | 0 |
| 104 | 0 | 0 |
| 105 | 0 | 0 |
| 86 | 0 | 0 |
| 109 | 0 | 0 |