Ismerkedés az Apache Spark használatával
Az Apache Spark elosztott adatfeldolgozási keretrendszer, amely nagy léptékű adatelemzést tesz lehetővé a fürt több feldolgozási csomópontja közötti munka koordinálásával.
A Spark működése
Az Apache Spark-alkalmazások független folyamathalmazként futnak egy fürtön, amelyet a fő program SparkContext objektuma (az illesztőprogram-program) koordinál. A SparkContext csatlakozik a fürtkezelőhöz, amely az Apache Hadoop YARN implementációjának használatával lefoglalja az erőforrásokat az alkalmazások között. Miután csatlakozott, a Spark a fürt csomópontjain végrehajtókat szerez be az alkalmazáskód futtatásához.
A SparkContext futtatja a fő függvényt és a párhuzamos műveleteket a fürtcsomópontokon, majd összegyűjti a műveletek eredményeit. A csomópontok adatokat olvasnak és írnak a fájlrendszerből és a fájlrendszerbe, és rugalmas elosztott adatkészletekként (RDD-kként) gyorsítótáraznak át adatokat a memóriában.
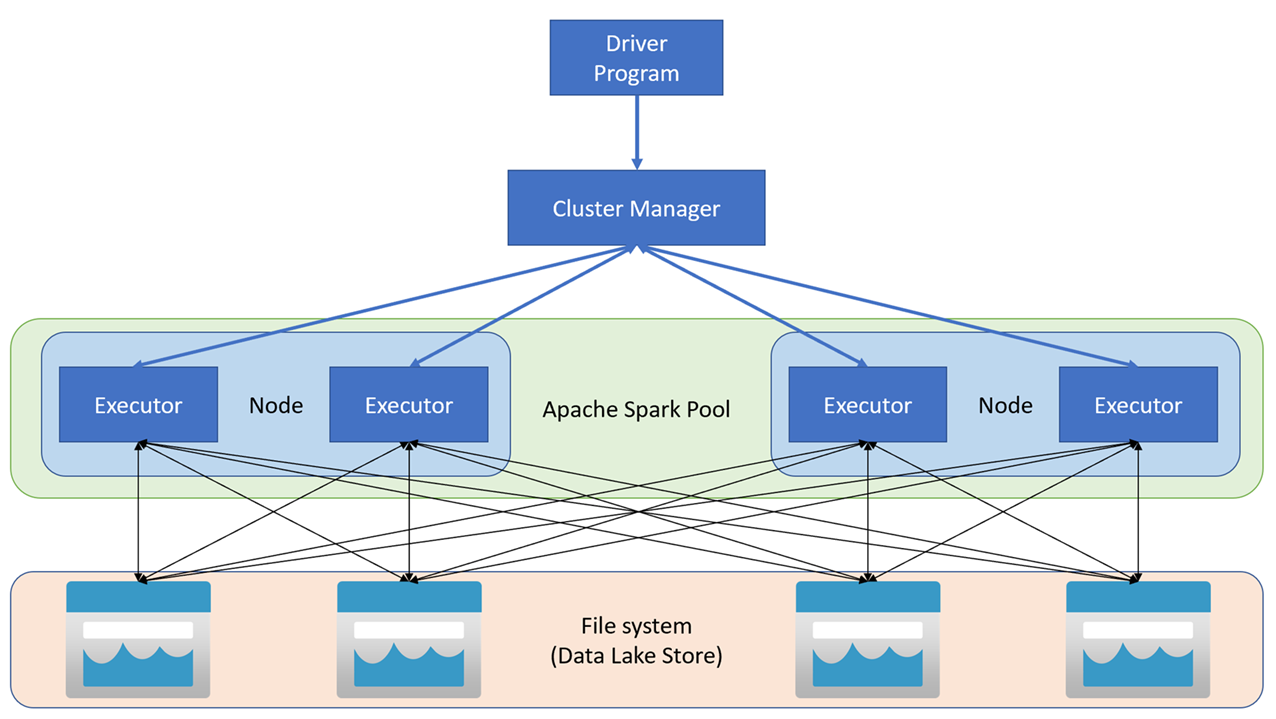
A SparkContext feladata, hogy egy alkalmazást irányított aciklikus gráfmá (DAG) alakítsa át. A gráf olyan egyedi feladatokból áll, amelyeket a csomópontok végrehajtói folyamatában hajtanak végre. Mindegyik alkalmazás saját végrehajtó folyamatokkal rendelkezik, amelyek az alkalmazás teljes időtartamáig működnek, és több szálon futtatnak feladatokat.
Spark-készletek az Azure Synapse Analyticsben
Az Azure Synapse Analyticsben a fürt Spark-készletként van implementálva, amely futtatókörnyezetet biztosít a Spark-műveletekhez. Létrehozhat egy vagy több Spark-készletet egy Azure Synapse Analytics-munkaterületen az Azure Portalon vagy az Azure Synapse Studióban. Spark-készlet definiálásakor megadhatja a készlet konfigurációs beállításait, többek között a következőket:
- A spark-készlet neve.
- A készlet csomópontjaihoz használt virtuális gép (VM) mérete, beleértve a hardveres gyorsított GPU-kompatibilis csomópontok használatát is.
- A készletben lévő csomópontok száma, valamint a készlet méretének rögzítése vagy az egyes csomópontok dinamikusan online állapotba hozhatók a fürt automatikus méretezéséhez. Ebben az esetben megadhatja az aktív csomópontok minimális és maximális számát.
- A készletben használandó Spark-futtatókörnyezet verziója; amely meghatározza az egyes összetevők, például a Python, a Java és más telepített összetevők verzióit.
Tipp.
A Spark-készlet konfigurációs beállításairól további információt az Azure Synapse Analytics Apache Spark-készletkonfigurációiról az Azure Synapse Analytics dokumentációjában talál.
Az Azure Synapse Analytics-munkaterület Spark-készletei kiszolgáló nélküliek – igény szerint indulnak, és tétlen állapotban leállnak.