A Spark használata az Azure Synapse Analyticsben
Számos különböző alkalmazást futtathat a Sparkban, beleértve a Python- vagy Scala-szkriptekben lévő kódot, a Java-archívumként (JAR) lefordított Java-kódot és másokat. A Sparkot általában kétféle számítási feladatban használják:
- Kötegelt vagy streamelési feladatok az adatok betöltésére, tisztítására és átalakítására – gyakran automatizált folyamat részeként futnak.
- Interaktív elemzési munkamenetek az adatok feltárásához, elemzéséhez és vizualizációihoz.
Spark-kód futtatása jegyzetfüzetekben
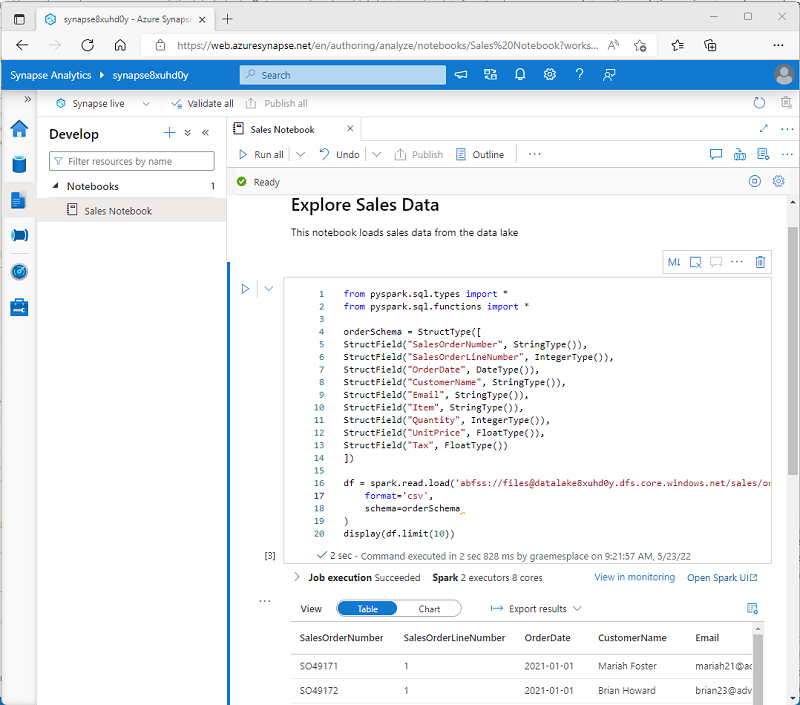
Az Azure Synapse Studio beépített notebook-felületet tartalmaz a Spark használatához. A jegyzetfüzetek intuitív módon kombinálják a kódot Markdown-jegyzetekkel, amelyeket gyakran használnak adattudósok és adatelemzők. Az Azure Synapse Studióban az integrált jegyzetfüzetek megjelenése és megjelenése hasonló a Jupyter notebookokéhoz – ez egy népszerű nyílt forráskód notebookplatform.
Megjegyzés:
Bár általában interaktívan használják, a jegyzetfüzetek belefoglalhatók az automatizált folyamatokba, és felügyelet nélküli szkriptként futtathatók.
A jegyzetfüzetek egy vagy több cellából állnak, amelyek mindegyike kódból vagy markdownból áll. A jegyzetfüzetek kódcellái olyan funkciókkal rendelkeznek, amelyek segíthetnek a hatékonyabb munkavégzésben, például:
- Szintaxiskiemelés és hibatámogatás.
- Kód automatikus kitöltése.
- Interaktív adatvizualizációk.
- Az eredmények exportálásának képessége.
Tipp.
Ha többet szeretne megtudni a jegyzetfüzetek Azure Synapse Analyticsben való használatáról, tekintse meg a Synapse-jegyzetfüzetek létrehozását, fejlesztését és karbantartását az Azure Synapse Analytics dokumentációjában található Azure Synapse Analytics-cikkben .
Adatok elérése Synapse Spark-készletből
Az Azure Synapse Analyticsben a Spark használatával különböző forrásokból származó adatokkal dolgozhat, például:
- Az Azure Synapse Analytics-munkaterület elsődleges tárfiókján alapuló adattó.
- A munkaterületen társított szolgáltatásként definiált tároláson alapuló adattó.
- Dedikált vagy kiszolgáló nélküli SQL-készlet a munkaterületen.
- Azure SQL- vagy SQL Server-adatbázis (az SQL Server Spark-összekötőjének használatával)
- Társított szolgáltatásként definiált és a Cosmos DB-hez készült Azure Synapse Link használatával konfigurált Azure Cosmos DB elemzési adatbázis.
- A munkaterület társított szolgáltatásaként definiált Azure Data Explorer Kusto-adatbázis.
- Egy külső Hive-metaadattár, amely társított szolgáltatásként van definiálva a munkaterületen.
A Spark egyik leggyakoribb felhasználási módja a data lake-beli adatok használata, ahol a fájlok több gyakran használt formátumban is olvashatók és írhatók, beleértve a tagolt szöveget, a Parquetet, az Avro-t és másokat.