Adatok vizualizációja a Sparkkal
Az adat-lekérdezések eredményeinek elemzésének egyik leg intuitívabb módja az, ha diagramként jeleníti meg őket. Az Azure Synapse Analytics jegyzetfüzetei alapvető diagramkészítési képességeket biztosítanak a felhasználói felületen, és ha ez a funkció nem biztosítja a szükséges funkciókat, a számos Python-grafikus kódtár egyikével hozhat létre és jeleníthet meg adatvizualizációkat a jegyzetfüzetben.
Beépített jegyzetfüzetdiagramok használata
Amikor adatkeretet jelenít meg, vagy SQL-lekérdezést futtat egy Spark-jegyzetfüzetben az Azure Synapse Analyticsben, az eredmények a kódcellában jelennek meg. Alapértelmezés szerint az eredmények táblázatként jelennek meg, de az eredménynézetet diagramra is módosíthatja, és a diagram tulajdonságaival testre szabhatja, hogyan jeleníti meg a diagram az adatokat, ahogy az itt látható:
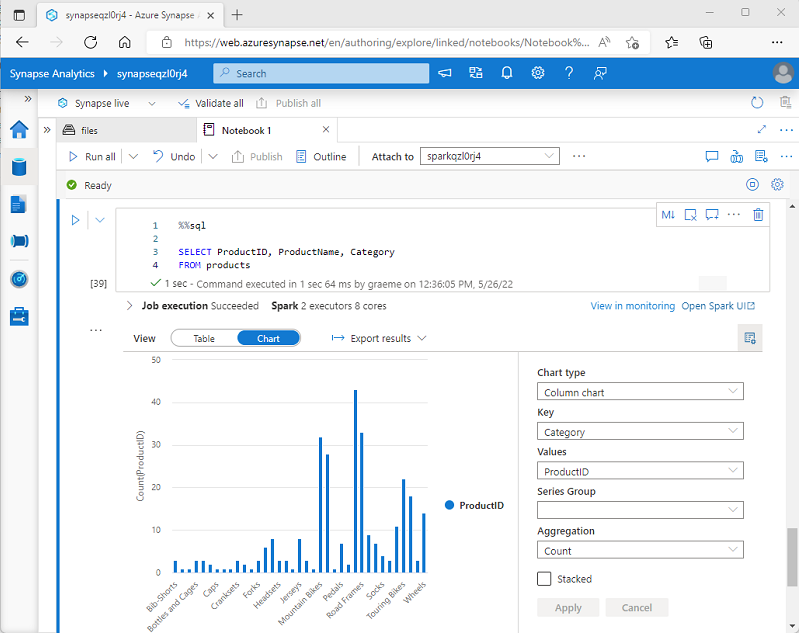
A jegyzetfüzetek beépített diagramkészítési funkciója akkor hasznos, ha olyan lekérdezés eredményeivel dolgozik, amelyek nem tartalmaznak meglévő csoportosításokat vagy összesítéseket, és szeretné gyorsan összegezni az adatokat vizuálisan. Ha nagyobb mértékben szeretné szabályozni az adatok formázását, vagy hogy megjelenítse a lekérdezésben már összesített értékeket, érdemes megfontolnia egy grafikus csomag használatát saját vizualizációk létrehozásához.
Grafikus csomagok használata kódban
Számos grafikus csomaggal hozhat létre adatvizualizációkat a kódban. A Python különösen a csomagok széles választékát támogatja; legtöbbjük a matplotlib alapkönyvtárra épül. A grafikus tárak kimenete megjeleníthető egy jegyzetfüzetben, így egyszerűen kombinálhatja a kódot az adatok beágyazott adatvizualizációkkal és markdown-cellákkal való betöltéséhez és kezeléséhez, hogy kommentárt nyújtson.
A következő PySpark-kód használatával például összesítheti a modulban korábban feltárt hipotetikus termékek adataiból származó adatokat, és a Matplotlib használatával létrehozhat egy diagramot az összesített adatokból.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
A Matplotlib-kódtár megköveteli, hogy az adatok ne Spark-adatkeretben, hanem Pandas-adatkeretben legyenek, ezért a rendszer a toPandas metódust használja az átalakításhoz. A kód ezután létrehoz egy megadott méretű ábrát, és az eredményként kapott diagram megjelenítése előtt egy egyéni tulajdonságkonfigurációval ábrázol egy sávdiagramot.
A kód által létrehozott diagram a következő képhez hasonlóan nézne ki:
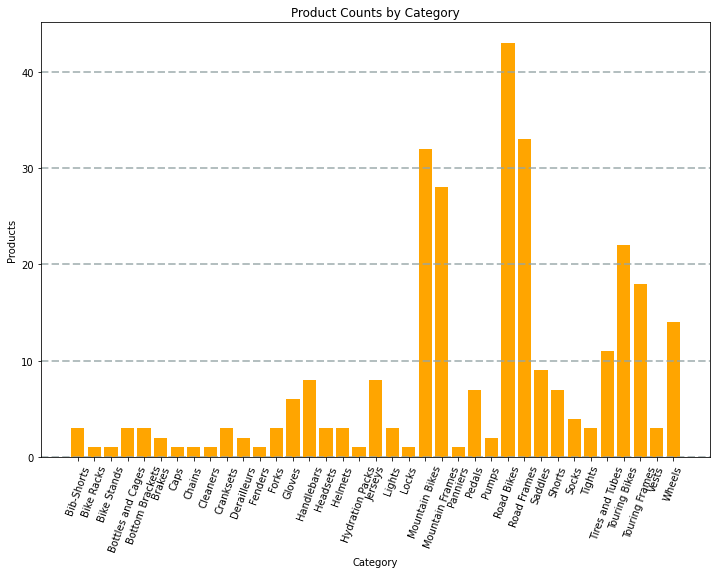
A Matplotlib-kódtár használatával sokféle diagramot hozhat létre; vagy ha előnyben részesíti, más kódtárakat, például a Seabornt is használhatja a nagymértékben testre szabott diagramok létrehozásához.