Ismerkedés a Spark használatával
Az adatok Azure Databricksben futó Apache Sparkkal való feldolgozásának és elemzésének jobb megértéséhez fontos megérteni az alapul szolgáló architektúrát.
Magas szintű áttekintés
Az Azure Databricks szolgáltatás magas szinten elindítja és felügyeli az Apache Spark-fürtöket az Azure-előfizetésében. Az Apache Spark-fürtök olyan számítógépcsoportok, amelyek egyetlen számítógépként vannak kezelve, és kezelik a jegyzetfüzetekből kiadott parancsok végrehajtását. A fürtök lehetővé teszik az adatok feldolgozásának párhuzamosságát számos számítógépen a skálázás és a teljesítmény javítása érdekében. Ezek Spark-illesztőprogramokból és feldolgozó csomópontokból állnak. Az illesztőprogram-csomópont munkát küld a feldolgozó csomópontoknak, és arra utasítja őket, hogy adatokat kérjenek le egy adott adatforrásból.
A Databricksben a notebook-felület általában az illesztőprogram-program. Ez az illesztőprogram-program tartalmazza a program fő ciklusát, és elosztott adathalmazokat hoz létre a fürtön, majd műveleteket alkalmaz ezekre az adathalmazokra. Az illesztőprogram-programok az üzembe helyezés helyétől függetlenül egy SparkSession-objektumon keresztül férnek hozzá az Apache Sparkhoz.

A Microsoft Azure felügyeli a fürtöt, és szükség szerint automatikusan skálázza azt a fürt konfigurálásakor használt használat és beállítás alapján. Az automatikus leállítás is engedélyezhető, ami lehetővé teszi, hogy az Azure meghatározott számú perc inaktivitás után leállítja a fürtöt.
Spark-feladatok részletei
A fürtnek küldött munka a szükséges számú független feladatra van felosztva. Így oszlik el a munka a fürt csomópontjai között. A feladatok további tevékenységekre vannak felosztva. A feladat bemenete egy vagy több partícióra van particionálva. Ezek a partíciók az egyes pontok munkaegységei. A tevékenységek között előfordulhat, hogy a partíciókat át kell szervezni és meg kell osztani a hálózaton.
A Spark nagy teljesítményének titka a párhuzamosság. A vertikális skálázás (ha erőforrásokat ad hozzá egyetlen számítógéphez) véges mennyiségű RAM-ra, szálra és processzorsebességre korlátozódik, de a fürtök horizontálisan skálázhatók, és szükség szerint új csomópontokat ad hozzá a fürthöz.
A Spark két szinten párhuzamosítja a feladatokat:
- A párhuzamosítás első szintje a végrehajtó – egy munkavégző csomóponton futó Java virtuális gép (JVM), amely általában csomópontonként egy példány.
- A párhuzamosítás második szintje a pont - amelynek számát az egyes csomópontok magjainak és PROCESSZORainak száma határozza meg.
- Minden végrehajtó több tárolóhellyel rendelkezik, amelyekhez párhuzamos tevékenységek rendelhetők hozzá.
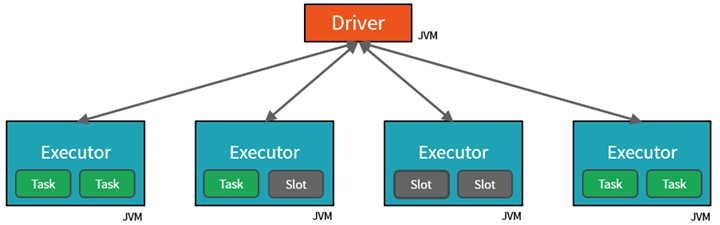
A JVM természetesen többszálas, de egyetlen JVM, például a vezető munkáját koordináló, véges felső korláttal rendelkezik. A munka tevékenységekre való felosztásával az illesztőprogram munkaegységeket rendelhet a feldolgozó csomópontok végrehajtóinak *tárolóhelyeihez párhuzamos végrehajtás céljából. Emellett az illesztőprogram meghatározza az adatok particionálásának módját, hogy azokat párhuzamos feldolgozás céljából el lehessen osztani. Az illesztőprogram tehát minden tevékenységhez hozzárendel egy adatpartíciót, hogy minden tevékenység tudja, melyik adatrészt dolgozza fel. A kezdés után minden tevékenység lekéri a hozzá rendelt adatok partícióját.
Feladatok és szakaszok
Az elvégzett munkától függően több párhuzamos feladatra lehet szükség. Minden feladat szakaszokra van bontva. Hasznos analógia, ha azt képzeljük, hogy a feladat egy ház felépítése:
- Az első lépés az alapok lefektetése lenne.
- A második fázis a falak felállítása lenne.
- A harmadik lépés a tető hozzáadása.
Ezeknek a lépéseknek a rendből való megkísérlése egyszerűen nem logikus, és valójában lehetetlen is lehet. Hasonlóképpen, a Spark szakaszokra bontja az egyes feladatokat, hogy minden a megfelelő sorrendben történjen.