WebNN API Tutorial
For an intro to WebNN, including information about operating system support, model support, and more, visit the WebNN Overview.
This tutorial will show you how to use WebNN with ONNX Runtime Web to build an image classification system on the web that is hardware accelerated using on-device GPU. We will be leveraging the MobileNetV2 model, which is an open-source model on Hugging Face used to classify images.
If you want to view and run the final code of this tutorial, you can find it on our WebNN Developer Preview GitHub.
Note
The WebNN API is a W3C Candidate Recommendation and is in early stages of a developer preview. Some functionality is limited. We have a list of current support and implementation status.
Requirements and set-up:
Setting Up Windows
Ensure you have the correct versions of Edge, Windows, and hardware drivers as detailed in the WebNN Requirements section.
Setting Up Edge
Download and install Microsoft Edge Dev.
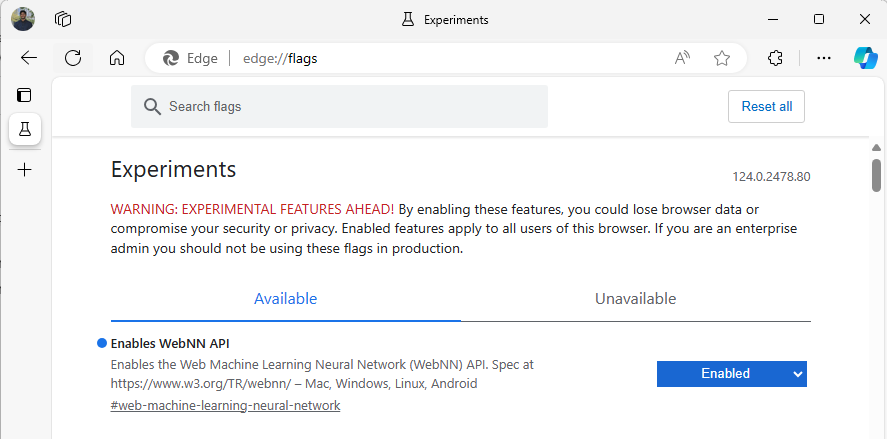
Launch Edge Beta, and navigate to
about:flagsin the address bar.Search for "WebNN API", click the dropdown, and set to 'Enabled'.
Restart Edge, as prompted.
Setting Up Developer Environment
Download and install Visual Studio Code (VSCode).
Launch VSCode.
Download and install the Live Server extension for VSCode within VSCode.
Select
File --> Open Folder, and create a blank folder in your desired location.
Step 1: Initialize the web app
- To begin, create a new
index.htmlpage. Add the following boilerplate code to your new page:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Verify the boilerplate code and developer setup worked by selecting the Go Live button at the bottom right hand side of VSCode. This should launch a local server in Edge Beta running the boilerplate code.
- Now, create a new file called
main.js. This will contain the javascript code for your app. - Next, create a subfolder off the root directory named
images. Download and save any image within the folder. For this demo, we'll use the default name ofimage.jpg. - Download the mobilenet model from the ONNX Model Zoo. For this tutorial, you'll be using the mobilenet2-10.onnx file. Save this model to the root folder of your web app.
- Finally, download and save this image classes file,
imagenetClasses.js. This provides 1000 common classifications of images for your model to use.
Step 2: Add UI elements and parent function
- Within the body of the
<main>html tags you added in the previous step, replace the existing code with the following elements. These will create a button and display a default image.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- Now, you'll add ONNX Runtime Web to your page, which is a JavaScript library you'll use to access the WebNN API. Within the body of the
<head>html tags, add the following javascript source links.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
- Open your
main.jsfile, and add the following code snippet.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Step 3: Pre-process data
- The function you just added calls
getImageTensorFromPath, another function you have to implement. You'll add it below, as well as another async function it calls to retrieve the image itself.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- You also need to add the
imageDataToTensorfunction that is referenced above, which will render the loaded image into a tensor format that will work with our ONNX model. This is a more involved function, though it might seem familiar if you've worked with similar image classification apps before. For an extended explanation, you can view this ONNX tutorial.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Step 4: Call ONNX Runtime Web
- You've now added all the functions needed to retrieve your image and render it as a tensor. Now, using the ONNX Runtime Web library that you loaded above, you'll run your model. Note that to use WebNN here, you simply specify
executionProvider = "webnn"- ONNX Runtime's support makes it very straightforward to enable WebNN.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
// Uncomment for additional information in debug builds:
// ort.env.wasm.proxy = true;
// ort.env.logLevel = "verbose";
// ort.env.debug = true;
// Configure WebNN.
const modelPath = "./mobilenetv2-10.onnx";
const devicePreference = "gpu"; // Other options include "npu" and "cpu".
const options = {
executionProviders: [{ name: "webnn", deviceType: devicePreference, powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
// The key names in freeDimensionOverrides should map to the real input dim names in the model.
// For example, if a model's only key is batch_size, you only need to set
// freeDimensionOverrides: {"batch_size": 1}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Step 5: Post-process data
- Finally, you'll add a
softmaxfunction, then add your final function to return the most likely image classification. Thesoftmaxtransforms your values to be between 0 and 1, which is the probability form needed for this final classification.
First, add the following source files for helper libraries Jimp and Lodash in the head tag of main.js.
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
Now, add these following functions to main.js.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- You've now added all the scripting needed to run image classification with WebNN in your basic web app. Using the Live Server extension for VS Code, you can now launch your basic webpage in-app to see the results of the classification for yourself.