Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az oktatóanyag előző szakaszában telepítettük a PyTorchot a gépére. Most arra fogjuk használni, hogy a kódot a modell létrehozásához használt adatokkal állítsuk be.
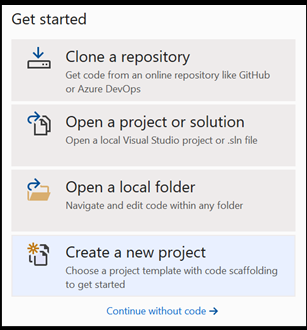
Nyisson meg egy új projektet a Visual Studióban.
- Nyissa meg a Visual Studiót, és válassza a lehetőséget
create a new project.
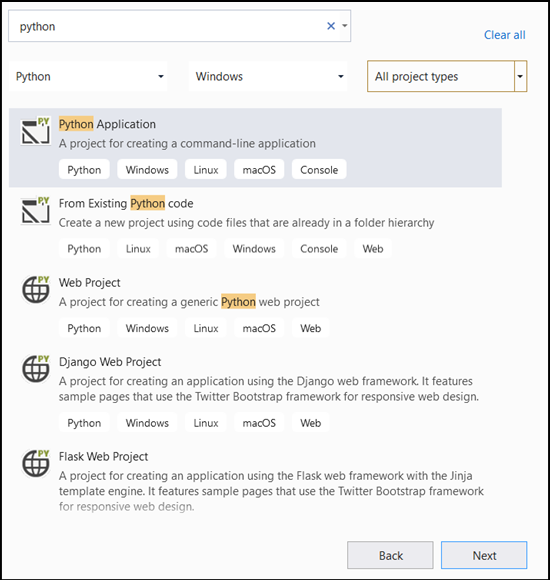
- A keresősávba írja be
Pythonés válassza kiPython Applicationa projektsablont.
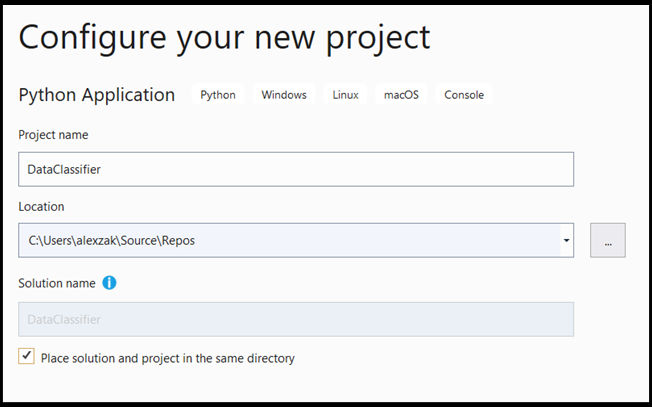
- A konfigurációs ablakban:
- Nevezd el a projektedet. Itt DataClassifier-nek hívjuk.
- Válassza ki a projekt helyét.
- Ha VS2019-et használ, győződjön meg róla, hogy
Create directory for solutionbe van jelölve. - Ha VS2017-et használ, győződjön meg arról, hogy
Place solution and project in the same directorynincs bejelölve.
Nyomja le create a projekt létrehozásához.
Python-értelmező létrehozása
Most meg kell határoznia egy új Python-értelmezőt. Ennek tartalmaznia kell a nemrég telepített PyTorch-csomagot.
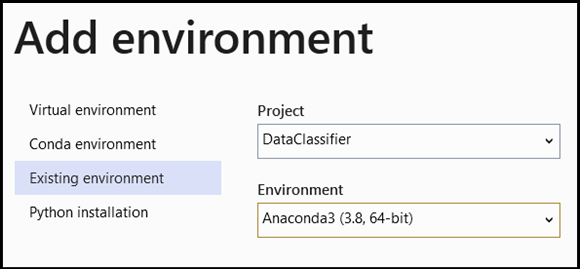
- Navigáljon az értelmező kiválasztásához, és válassza a következőt
Add Environment:

-
Add EnvironmentAz ablakban válassza a lehetőségetExisting environment, majd válassza a lehetőségetAnaconda3 (3.6, 64-bit). Ebbe beletartozik a PyTorch-csomag is.
Az új Python-értelmező és PyTorch-csomag teszteléséhez írja be a következő kódot a DataClassifier.py fájlba:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
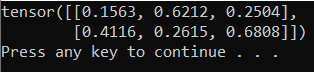
A kimenetnek az alábbihoz hasonló véletlenszerű 5x3 tenzornak kell lennie.
Megjegyzés:
Szeretne többet tanulni? Látogasson el a PyTorch hivatalos webhelyére.
Az adatok ismertetése
Betanítjuk a modellt a Fisher-féle Iris virágadatkészleten. Ez a híres adatkészlet 50 rekordot tartalmaz mindhárom íriszfajhoz: Iris setosa, Iris virginica és Iris versicolor.
Az adathalmaz több verziója is megjelent. Az Iris-adatkészletet az UCI Machine Learning-adattárban találja, importálhatja az adathalmazt közvetlenül a Python Scikit-learn kódtárból , vagy használhat bármely korábban közzétett verziót. Ha többet szeretne megtudni az Írisz virágadatkészletéről, látogasson el a Wikipédiára.
Ebben az oktatóanyagban a modell táblázatos bemenettel való betanítása érdekében az Excel-fájlba exportált Írisz-adatkészletet fogja használni.
Az Excel-táblázat minden sora az Írisz négy jellemzőt jeleníti meg: a sepal hossza cm-ben, a sepal szélessége cm-ben, a szirmok hossza cm-ben, a sziromszélesség pedig cm-ben. Ezek a funkciók lesznek a bemenetek. Az utolsó oszlop tartalmazza az ezekhez a paraméterekhez kapcsolódó írisztípust, és a regressziós kimenetet jelöli. Az adathalmaz összesen négy funkció 150 bemenetét tartalmazza, amelyek mindegyike megfelel a megfelelő Írisz-típusnak.
A regresszióelemzés a bemeneti változók és az eredmény közötti kapcsolatot vizsgálja. A bemenet alapján a modell megtanulja megjósolni a kimenet megfelelő típusát - a három írisztípus egyike: Iris-setosa, Iris-versicolor, Iris-virginica.
Fontos
Ha úgy dönt, hogy bármilyen más adatkészletet használ a saját modell létrehozásához, a modell bemeneti változóit és kimenetét a forgatókönyvnek megfelelően kell megadnia.
Töltse be az adathalmazt.
Töltse le az Iris-adatkészletet Excel formátumban. Itt találja.
DataClassifier.pyA Solution Explorer Files mappában lévő fájlban adja hozzá a következő importálási utasítást, hogy hozzáférjen az összes szükséges csomaghoz.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Mint látható, a pandas (Python-adatelemzés) csomagot fogja használni az adatok betöltéséhez és kezeléséhez, valamint a torch.nn csomaghoz, amely modulokat és bővíthető osztályokat tartalmaz a neurális hálózatok létrehozásához.
- Töltse be az adatokat a memóriába, és ellenőrizze az osztályok számát. Várhatóan minden írisztípusból 50 elem lesz. Mindenképpen adja meg az adathalmaz helyét a pc-n.
Adja hozzá az alábbi kódot a DataClassifier.py fájlhoz.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
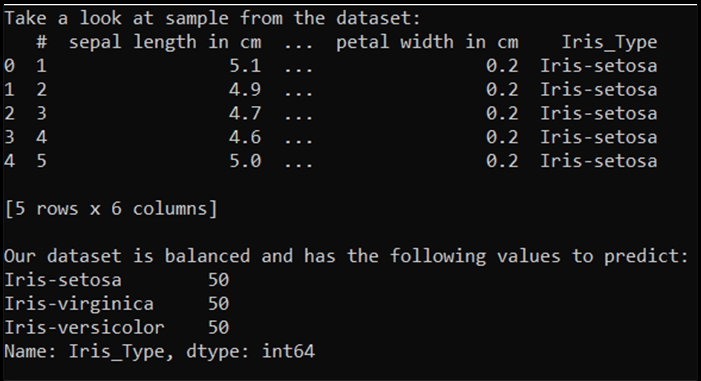
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
A kód futtatásakor a várt kimenet a következő:
Az adathalmaz használatához és a modell betanítása érdekében meg kell határoznunk a bemenetet és a kimenetet. A bemenet 150 sornyi funkciót tartalmaz, a kimenet pedig az Írisz típusú oszlop. A használni kívánt neurális hálózathoz numerikus változók szükségesek, ezért a kimeneti változót numerikus formátummá kell konvertálnia.
- Hozzon létre egy új oszlopot az adathalmazban, amely numerikus formátumban jeleníti meg a kimenetet, és meghatároz egy regressziós bemenetet és kimenetet.
Adja hozzá az alábbi kódot a DataClassifier.py fájlhoz.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
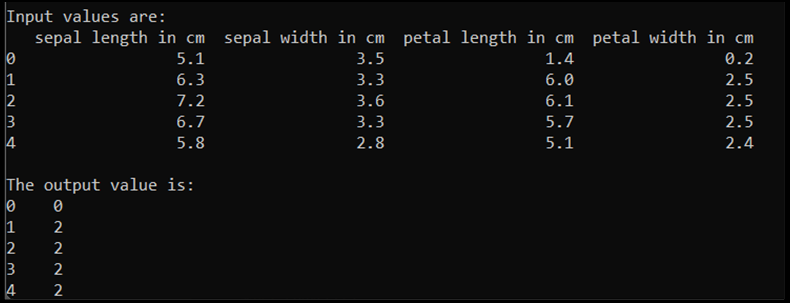
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
A kód futtatásakor a várt kimenet a következő:
A modell betanítása érdekében a modell bemenetét és kimenetét Tensor formátumba kell konvertálnunk:
- Konvertálás Tensorra:
Adja hozzá az alábbi kódot a DataClassifier.py fájlhoz.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
A kód futtatásakor a várt kimenet a bemeneti és kimeneti formátumot jeleníti meg az alábbiak szerint:

150 bemeneti érték van. Körülbelül 60% lesznek a modell betanítási adatai. A validálásra 20%-t, tesztre pedig 30%-t tartasz.
Ebben az oktatóanyagban egy betanítási adatkészlet kötegmérete 10-ként van definiálva. A tanulókészletben 95 elem található, ami azt jelenti, hogy átlagosan 9 teljes batch van, amelyeket egy epoch alatt iterálhatunk végig a tanulókészleten. Az érvényesítési és tesztkészletek kötegmérete 1 marad.
- Ossza fel az adatokat a készletek betanításához, érvényesítéséhez és teszteléséhez:
Adja hozzá az alábbi kódot a DataClassifier.py fájlhoz.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Következő lépések
Ha az adatok készen állnak a használatra, ideje betaníteni a PyTorch-modellt