Partisi di Azure Cosmos DB untuk Apache Cassandra
BERLAKU UNTUK:![]() Cassandra
Cassandra
Artikel ini menjelaskan cara kerja partisi di Azure Cosmos DB untuk Apache Cassandra.
API untuk Cassandra menggunakan partisi untuk menskalakan tabel individual di keyspace untuk memenuhi kebutuhan performa aplikasi Anda. Partisi dibentuk berdasarkan nilai kunci partisi yang terkait dengan setiap rekaman dalam tabel. Semua rekaman dalam partisi memiliki nilai kunci partisi yang sama. Azure Cosmos DB secara transparan dan otomatis mengelola penempatan partisi di seluruh sumber daya fisik untuk secara efisien memenuhi kebutuhan skalabilitas dan performa tabel. Ketika persyaratan throughput dan penyimpanan aplikasi meningkat, Azure Cosmos DB memindahkan dan menyeimbangkan data di sejumlah besar mesin fisik.
Dari perspektif pengembang, partisi berperilaku dengan cara yang sama untuk Azure Cosmos DB untuk Apache Cassandra seperti yang dilakukan di Apache Cassandra asli. Namun, ada beberapa perbedaan di balik layar.
Perbedaan antara Apache Cassandra dan Azure Cosmos DB
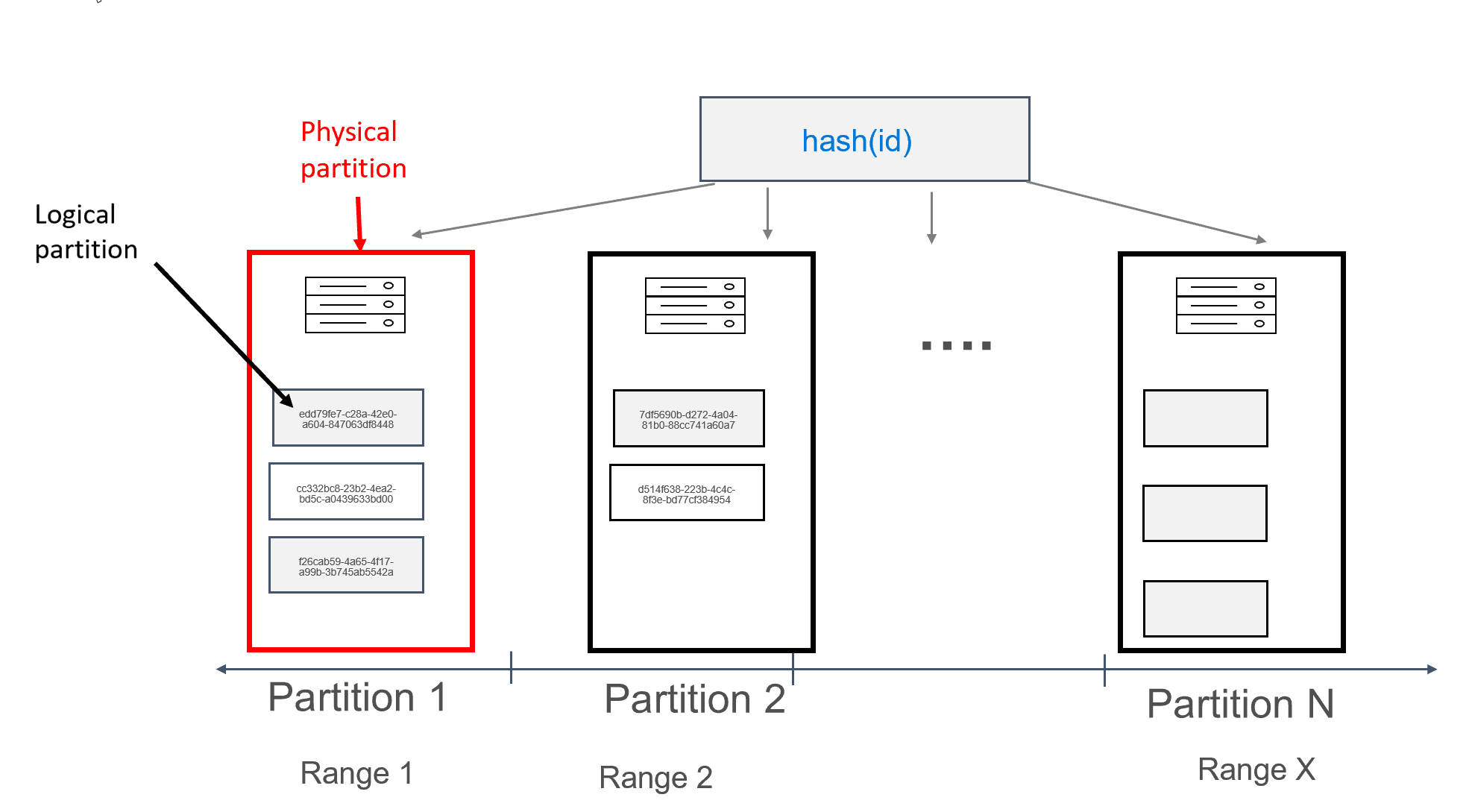
Dalam Azure Cosmos DB, setiap mesin tempat partisi disimpan sendiri disebut sebagai partisi fisik. Partisi fisik mirip dengan Komputer Virtual; unit komputasi khusus, atau sekumpulan sumber daya fisik. Setiap partisi yang disimpan pada unit komputasi ini disebut sebagai partisi logis di Azure Cosmos DB. Jika Anda sudah terbiasa dengan Apache Cassandra, Anda dapat memikirkan partisi logis dengan cara yang sama seperti ketika Anda memikirkan partisi reguler di Cassandra.
Apache Cassandra merekomendasikan batas 100 MB pada ukuran data yang dapat disimpan dalam partisi. API untuk Cassandra untuk Azure Cosmos DB memungkinkan hingga 20 GB per partisi logis, dan hingga 30GB data per partisi fisik. Di Azure Cosmos DB, tidak seperti Apache Cassandra, kapasitas komputasi yang tersedia dalam partisi fisik diekspresikan dengan menggunakan satu metrik yang disebut unit permintaan, yang memungkinkan Anda untuk memikirkan beban kerja Anda dalam hal permintaan (baca atau tulis) per detik, bukan inti, memori, atau IOPS. Ini dapat membuat perencanaan kapasitas lebih sederhana, setelah Anda memahami biaya setiap permintaan. Setiap partisi fisik dapat memiliki hingga 10000 RUs komputasi yang tersedia untuk itu. Anda dapat mempelajari selengkapnya tentang opsi skalabilitas dengan membaca artikel kami tentang skala elastis di API untuk Cassandra.
Dalam Azure Cosmos DB, setiap partisi fisik terdiri dari satu set replika, juga dikenal sebagai rangkaian replika, dengan setidaknya 4 replika per partisi. Ini berbeda dengan Apache Cassandra, yang memungkinkan penetapan faktor replikasi 1. Namun, cara ini membuat ketersediaan menjadi rendah jika satu-satunya node yang berisi data menurun. Dalam API untuk Cassandra selalu ada faktor replikasi 4 (kuorum 3). Azure Cosmos DB secara otomatis mengelola set replika, sementara ini perlu dipertahankan dengan menggunakan berbagai alat di Apache Cassandra.
Apache Cassandra memiliki konsep token, yaitu hash kunci partisi. Token didasarkan pada hash murmur3 64 byte, dengan nilai mulai dari -2^63 hingga -2^63 - 1. Rentang ini biasa disebut sebagai "cincin token" di Apache Cassandra. Cincin token didistribusikan ke dalam rentang token, dan rentang ini dibagi di antara node yang ada di kluster Apache Cassandra asli. Pemartisian untuk Azure Cosmos DB diimplementasikan dengan cara yang sama, kecuali menggunakan algoritma hash yang berbeda, dan memiliki cincin token internal yang lebih besar. Namun, secara eksternal kami mengekspos kisaran token yang sama dengan Apache Cassandra, yaitu, -2^63 hingga -2^63 - 1.
Kunci primer
Semua tabel dalam API untuk Cassandra harus memiliki yang primary key ditentukan. Sintaks untuk kunci utama diperlihatkan di bawah ini:
column_name cql_type_definition PRIMARY KEY
Misalnya, kita ingin membuat tabel pengguna, yang menyimpan pesan untuk pengguna yang berbeda:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
Dalam desain ini, kami telah mendefinisikan bidang id sebagai kunci utama. Kunci utama berfungsi sebagai pengidentifikasi untuk rekaman dalam tabel dan juga digunakan sebagai kunci partisi di Azure Cosmos DB. Jika kunci utama didefinisikan dengan cara yang dijelaskan sebelumnya, hanya akan ada satu rekaman di setiap partisi. Ini akan menghasilkan distribusi yang sangat horizontal dan dapat diskalakan saat menulis data ke database, dan sangat ideal untuk kasus penggunaan pencarian nilai kunci. Aplikasi harus menyediakan kunci utama setiap kali membaca data dari tabel, untuk memaksimalkan performa baca.
Kunci utama senyawa
Apache Cassandra juga memiliki konsep compound keys. Senyawa primary key terdiri dari lebih dari satu kolom; kolom pertama adalah partition key, dan kolom tambahan adalah clustering keys. Sintaks untuk compound primary key ditunjukkan di bawah ini:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Misalkan kita ingin mengubah desain di atas dan memungkinkannya untuk secara efisien mengambil pesan untuk pengguna tertentu:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
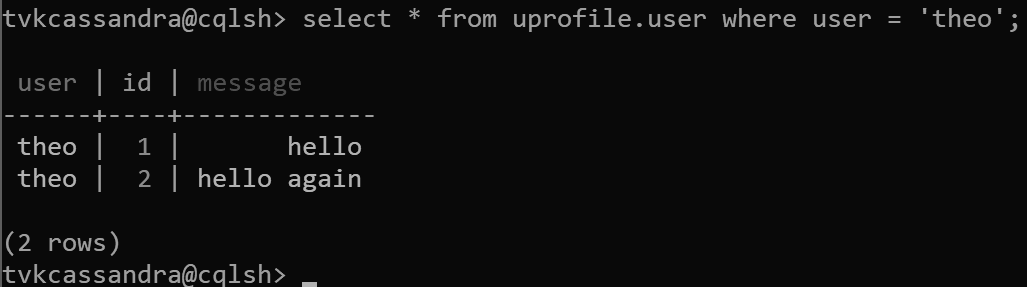
Dalam desain ini, kita sekarang mendefinisikan user sebagai kunci partisi, dan id sebagai kunci pengklusteran. Anda dapat menentukan tombol pengklusteran sebanyak yang Anda inginkan, tetapi setiap nilai (atau kombinasi nilai) untuk kunci pengklusteran harus unik agar beberapa rekaman ditambahkan ke partisi yang sama, misalnya:
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Ketika data dikembalikan, data diurutkan berdasarkan kunci pengklusteran, seperti yang diharapkan di Apache Cassandra:
Peringatan
Saat mengkueri data dalam tabel yang memiliki kunci primer gabungan, jika Anda ingin memfilter kunci partisi dan bidang lain yang tidak diindeks selain kunci pengklusteran, pastikan Anda secara eksplisit menambahkan indeks sekunder pada kunci partisi:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB for Apache Cassandra tidak menerapkan indeks ke kunci partisi secara default, dan indeks dalam skenario ini dapat secara signifikan meningkatkan performa kueri. Tinjau artikel kami tentang pengindeksan sekunder untuk informasi selengkapnya.
Dengan data yang dimodelkan dengan cara ini, beberapa rekaman dapat ditetapkan ke setiap partisi, dengan cara dikelompokkan menurut pengguna. Dengan demikian, kami dapat mengeluarkan kueri yang dirutekan secara efisien oleh partition key (dalam hal ini, user) untuk mendapatkan semua pesan untuk pengguna tertentu.
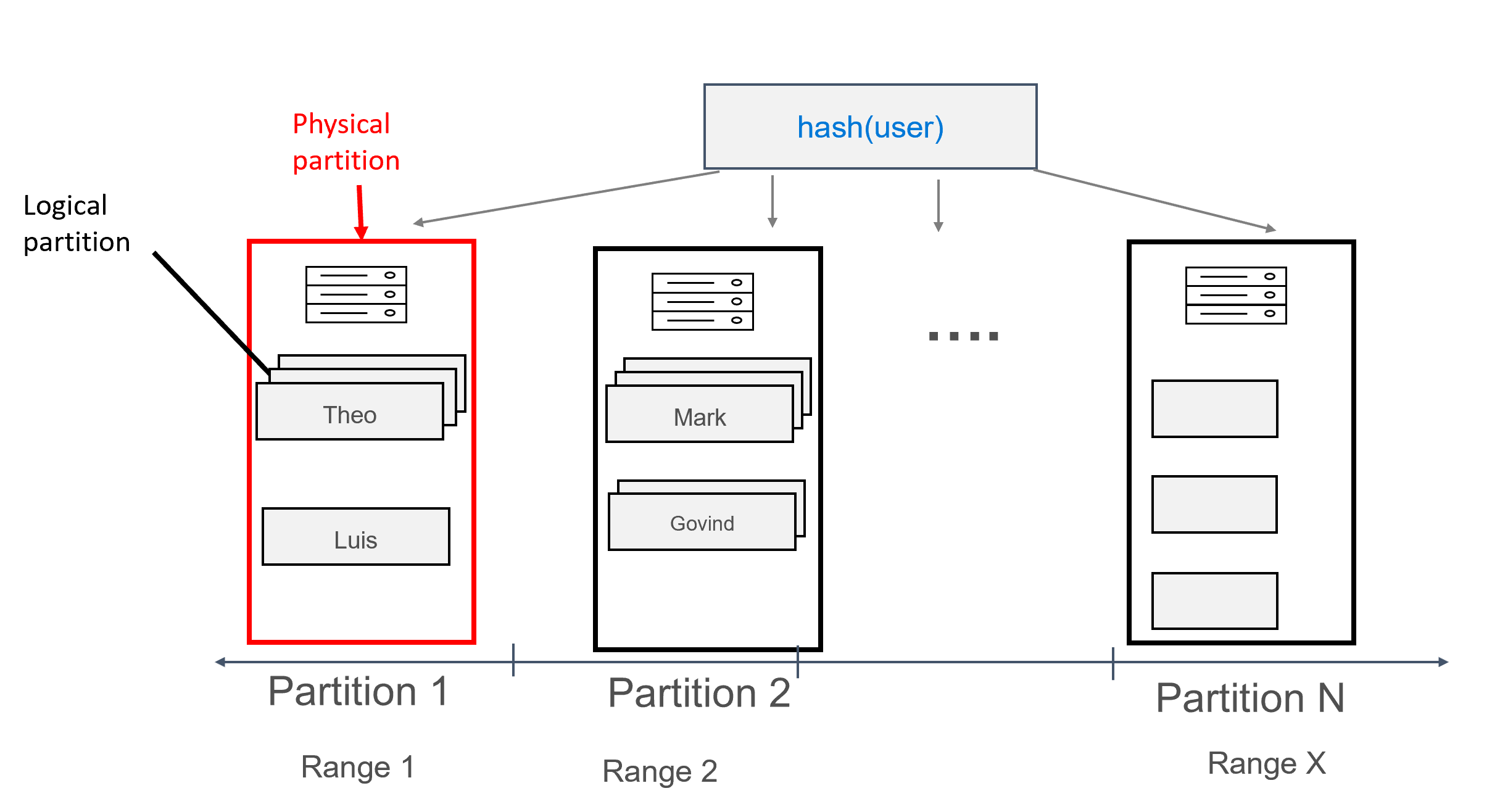
Kunci partisi komposit
Kunci partisi komposit pada dasarnya berfungsi dengan cara yang sama seperti tombol senyawa, kecuali bahwa Anda dapat menentukan beberapa kolom sebagai kunci partisi komposit. Sintaks tombol partisi komposit ditunjukkan di bawah ini:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Misalnya, Anda dapat memiliki hal berikut, yaitu kombinasi unik firstname dan lastname akan membentuk tombol partisi, dan id merupakan tombol pengklusteran:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Langkah berikutnya
- Pelajari pemartisian dan penskalaan horizontal di Azure Cosmos DB.
- Pelajari tentang throughput yang ditentukan di Azure Cosmos DB.
- Pelajari tentang distribusi global di Azure Cosmos DB.