Apa itu Apache Hadoop di Azure HDInsight?
Apache Hadoop adalah kerangka kerja sumber terbuka orisinal untuk pemrosesan terdistribusi dan analisis himpunan data besar pada kluster. Ekosistem Hadoop mencakup perangkat lunak dan utilitas terkait, termasuk Apache Hive, Apache HBase, Spark, Kafka, dan banyak lainnya.
Azure HDInsight adalah layanan analitik sumber terbuka dengan spektrum penuh yang dikelola penuh dalam cloud untuk perusahaan. Jenis kluster Apache Hadoop di Azure HDInsight memungkinkan Anda untuk menggunakan Apache Hadoop Distributed File System (HDFS), manajemen sumber daya APACHE Hadoop YARN, dan model pemrograman MapReduce sederhana untuk memproses dan menganalisis data batch secara paralel. Kluster Hadoop di HDInsight kompatibel dengan penyimpanan Azure Blob, Azure Data Lake Storage Gen1, atau Azure Data Lake Storage Gen2.
Untuk melihat komponen tumpukan teknologi Hadoop yang tersedia di HDInsight, lihat Komponen dan versi yang tersedia di HDInsight. Baca selengkapnya tentang Hadoop di HDInsight di Halaman fitur Azure untuk HDInsight.
Apa itu MapReduce
Apache Hadoop MapReduce adalah kerangka kerja perangkat lunak untuk menulis pekerjaan yang memproses sejumlah besar data. Data input dibagi menjadi gugus-gugus independen. Setiap gugus diproses secara paralel di seluruh simpul dalam kluster Anda. Pekerjaan MapReduce terdiri dari dua fungsi:
Pemeta:Mengonsumsi data input, menganalisisnya (biasanya dengan operasi pemfilteran dan pengurutan), dan memancarkan tuple (pasangan kunci-nilai)
Peredam: Mengonsumsi tuple yang dipancarkan oleh Pemeta dan melakukan operasi ringkasan yang menciptakan hasil gabungan yang lebih kecil dari data Pemetaan
Contoh pekerjaan dasar penghitungan kata MapReduce digambarkan dalam diagram berikut ini:
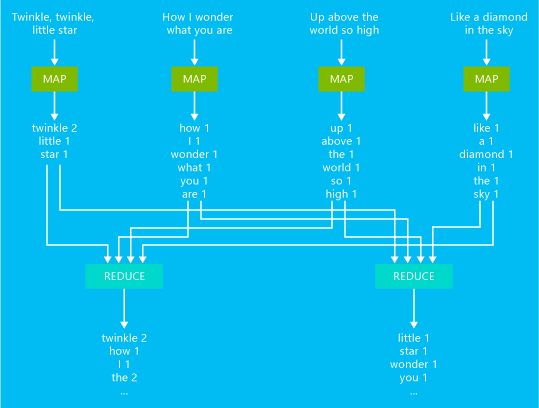
Output dari pekerjaan ini adalah hitungan berapa kali tiap kata muncul dalam teks.
- Pemeta mengambil setiap baris dari teks input sebagai input dan memecahnya menjadi kata-kata. Ia memancarkan pasangan kunci/nilai setiap kali kemunculan suatu kata diikuti oleh 1. Output diurutkan sebelum dikirim ke peredam.
- Peredam menjumlahkan hitungan individu untuk setiap kata ini dan memancarkan pasangan kunci/nilai tunggal yang memuat kata tersebut dan jumlah kemunculannya.
MapReduce dapat diterapkan dalam berbagai bahasa komputer. Java adalah penerapan yang paling umum, dan digunakan sebagai contoh dalam dokumen ini.
Bahasa pengembangan
Bahasa komputer atau kerangka kerja yang didasarkan pada Java dan Komputer Virtual Java dapat dijalankan langsung sebagai Pekerjaan MapReduce. Contoh yang digunakan dalam dokumen ini adalah aplikasi Java MapReduce. Bahasa komputer non-Java, seperti C#, Python, atau exe mandiri, harus menggunakan Streaming Hadoop.
Streaming Hadoop berkomunikasi dengan pemeta dan peredam melalui STDIN dan STDOUT. Pemeta dan peredam membaca data baris demi baris dari STDIN, dan menulis output ke STDOUT. Setiap baris yang dibaca atau dipancarkan oleh pemeta dan peredam harus dalam format pasangan kunci/nilai, yang dibatasi oleh karakter tab:
[key]\t[value]
Untuk informasi selengkapnya, lihat Streaming Hadoop.
Untuk contoh penggunaan streaming Hadoop dengan HDInsight, lihat dokumen berikut:
Di mana saya harus memulai
- Mulai Cepat: Buat kluster Apache Hadoop di Azure HDInsight menggunakan portal Microsoft Azure
- Tutorial: Kirim pekerjaan Apache Hadoop di HDInsight
- Kembangkan program Java MapReduce untuk Apache Hadoop di HDInsight
- Gunakan Apache Hive sebagai alat Ekstraksi, Transformasi, dan Pemuatan (ETL)
- Ekstrak, transformasi, dan pemuatan (ETL) dalam skala
- Mengoperasionalkan alur analitik data