Panduan mulai cepat: Membuat kluster Apache Spark di Azure HDInsight menggunakan portal Microsoft Azure
Dalam panduan mulai cepat ini, gunakan portal Microsoft Azure untuk membuat kluster Apache Spark di Azure HDInsight. Kemudian, buat file Jupyter Notebook, dan gunakan untuk menjalankan kueri SQL Spark terhadap tabel Apache Hive. Azure HDInsight merupakan layanan analitik sumber terbuka terkelola dengan spektrum penuh untuk perusahaan. Kerangka kerja Apache Spark untuk HDInsight memungkinkan analitik data dan komputasi kluster yang cepat menggunakan pemrosesan dalam memori. Jupyter Notebook memungkinkan Anda berinteraksi dengan data, menggabungkan kode dengan teks {i>markdown
Untuk penjelasan mendalam tentang konfigurasi yang tersedia, lihat Siapkan kluster di HDInsight. Untuk informasi tambahan mengenai penggunaan portal untuk membuat kluster, lihat Membuat kluster di portal.
Jika Anda menggunakan beberapa kluster bersama-sama, Anda mungkin ingin membuat jaringan virtual; jika Anda menggunakan kluster Spark mungkin juga ingin menggunakan Koneksi or Gudang Apache Hive. Untuk informasi selengkapnya, lihat Merencanakan jaringan virtual untuk Azure HDInsight dan Mengintegrasikan Apache Spark dan Apache Hive dengan Hive Warehouse Connector.
Penting
Penagihan untuk kluster HDInsight di-prorata per menit, baik Anda menggunakannya atau tidak. Pastikan untuk menghapus kluster Anda setelah selesai menggunakannya. Untuk informasi selengkapnya, lihat bagian Membersihkan sumber daya di artikel ini.
Prasyarat
Akun Azure dengan langganan aktif. Buat akun secara gratis.
Membuat kluster Apache Spark di Microsoft Azure HDInsight
Gunakan portal Microsoft Azure untuk membuat kluster HDInsight yang menggunakan Azure Storage Blobs sebagai penyimpanan kluster. Untuk informasi selengkapnya tentang menggunakan Data Lake Storage Gen2, lihat Panduan Mulai Cepat: Siapkan kluster di HDInsight.
Masuk ke portal Azure.
Dari menu di bagian atas, pilih + Buat sumber daya.
Pilih Analitik>Azure HDInsight untuk masuk ke halaman Buat kluster HDInsight.
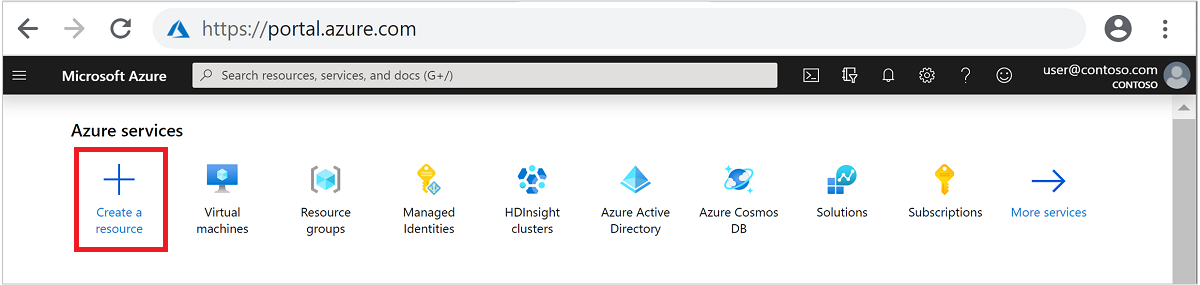
Pada tab Dasar, berikan informasi berikut ini:
Properti Deskripsi Langganan Dari daftar dropdown, pilih langganan Azure yang digunakan untuk kluster. Grup sumber daya Dari daftar dorp-down, pilih grup sumber daya yang sudah ada, atau pilih Buat baru. Nama kluster Masukkan nama yang unik secara global. Wilayah Dari daftar drop-down, pilih wilayah tempat kluster dibuat. Zona ketersediaan Opsional - tentukan zona ketersediaan untuk menyebarkan kluster Anda Jenis kluster Pilih jenis kluster untuk membuka daftar. Dari daftar, pilih Spark. Versi Kluster Bidang ini akan diisi secara otomatis dengan versi default setelah tipe kluster dipilih. Nama pengguna login kluster Masukkan nama pengguna masuk kluster. Nama defaultnya adalah admin. Anda menggunakan akun ini untuk masuk ke Jupyter Notebook nanti di mulai cepat. Sandi login kluster Masukkan nama pengguna masuk kluster. Nama pengguna Secure Shell (SSH) Masukkan nama pengguna SSH. Nama pengguna SSH yang digunakan untuk panduan mulai cepat ini adalah sshuser. Secara default, akun ini memiliki kata sandi yang sama dengan akun nama pengguna Cluster Login. 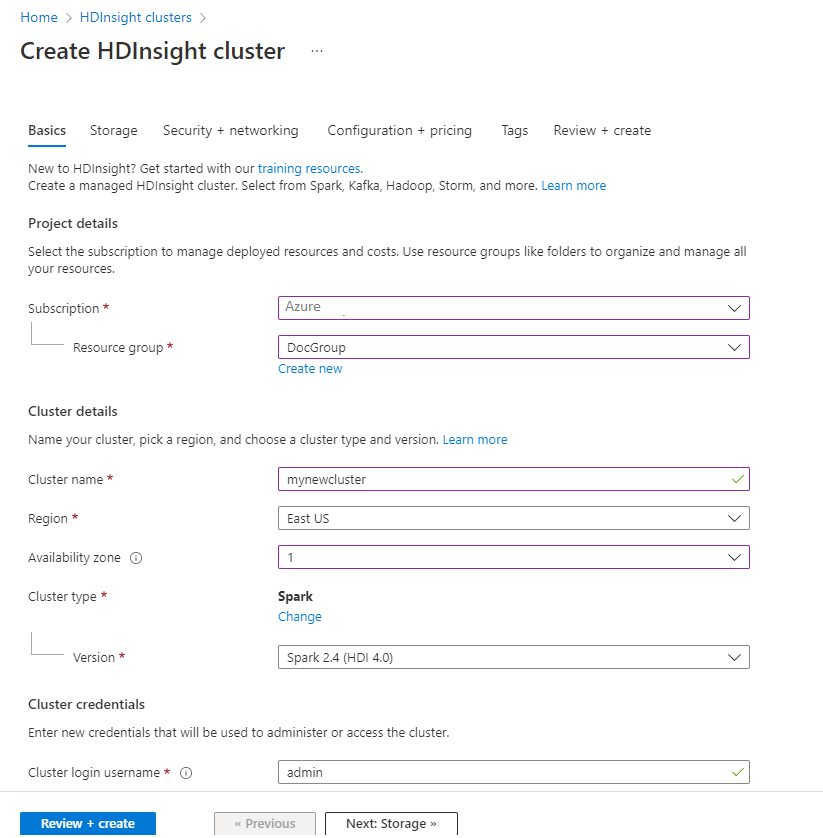
Pilih Berikutnya: Penyimpanan >> untuk melanjutkan ke halaman Penyimpanan.
Di Penyimpanan, berikan nilai berikut ini:
Properti Deskripsi Jenis penyimpanan utama Gunakan nilai default Azure Storage. Metode pemilihan Gunakan nilai default Pilih dari daftar. Akun penyimpanan primer Gunakan nilai yang diisi otomatis. Kontainer Gunakan nilai yang diisi otomatis. 
Pilih Tinjau + buat untuk melanjutkan.
Di bawah Tinjau + buat, pilih Buat. Dibutuhkan sekitar 20 menit untuk membuat kluster. Kluster harus dibuat sebelum Anda dapat melanjutkan ke sesi berikutnya.
Jika mengalami masalah terkait membuat kluster HDInsight, bisa jadi Anda tidak memiliki izin yang tepat untuk melakukannya. Untuk mengetahui informasi selengkapnya, lihat Persyaratan kontrol akses.
Membuat file Jupyter Notebook
Jupyter Notebook merupakan lingkungan buku catatan interaktif yang mendukung berbagai bahasa pemrogram. Buku catatan tersebut memungkinkan Anda untuk berinteraksi dengan data, menggabungkan kode dengan teks markdown, dan melakukan visualisasi sederhana.
Dari browser web, arahkan ke
https://CLUSTERNAME.azurehdinsight.net/jupyter, di manaCLUSTERNAMEmerupakan nama kluster Anda. Jika diminta, masukkan kredensial masuk kluster untuk kluster.Pilih PySpark>Baru untuk membuat buku catatan.
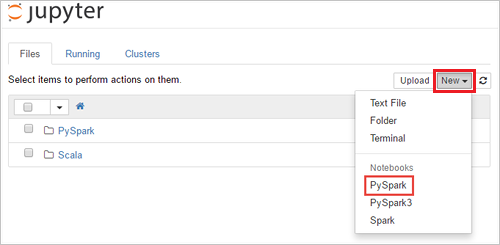
Notebook baru dibuat dan dibuka dengan nama Untitled(Untitled.pynb).
Menjalankan pernyataan SQL Apache Spark
SQL (Structured Query Language) merupakan bahasa yang paling umum dan banyak digunakan untuk membuat kueri dan mendefinisikan data. Spark SQL berfungsi sebagai ekstensi untuk Apache Spark guna memproses data terstruktur, menggunakan sintaksis SQL yang sudah diketahui.
Verifikasi kernel sudah siap. Kernel siap saat Anda melihat lingkaran berongga di samping nama kernel di buku catatan. Lingkaran padat menunjukkan bahwa kernel sibuk.

Saat memulai buku catatan untuk pertama kalinya, kernel melakukan beberapa tugas di latar belakang. Tunggu hingga kernel siap.
Tempelkan kode berikut dalam sel kosong, lalu tekan SHIFT + ENTER untuk menjalankan kode. Perintah mencantumkan tabel Hive pada kluster:
%%sql SHOW TABLESSaat menggunakan file Jupyter Notebook dengan kluster HDInsight, Anda mendapatkan preset
sqlContextyang dapat Anda gunakan untuk menjalankan kueri Apache Hive menggunakan Spark SQL.%%sqlmenginformasikan Jupyter Notebook untuk menggunakan presetsqlContextuntuk menjalankan kueri Apache Hive. Kueri mengambil 10 baris teratas dari tabel Hive(hivesampletable)yang dilengkapi dengan semua kluster HDInsight secara default. Dibutuhkan sekitar 30 detik untuk mendapatkan hasilnya. Output-nya terlihat seperti: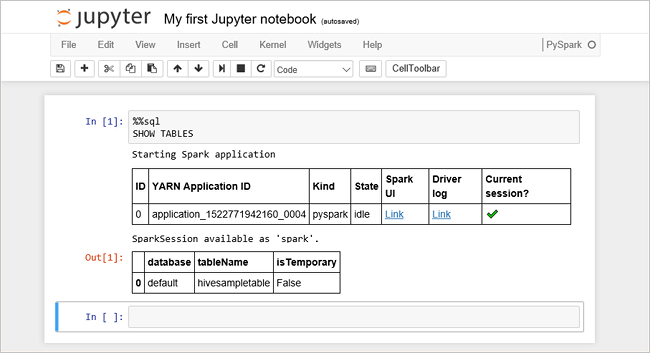 adalah mulai cepat." border="true":::
adalah mulai cepat." border="true":::Setiap kali Anda menjalankan kueri di Jupyter, judul jendela browser web Anda menunjukkan status (Sibuk) bersama dengan judul buku catatan. Anda juga melihat lingkaran padat di sebelah teks PySpark di pojok kanan atas.
Jalankan kueri lain untuk melihat data dalam
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Layar akan direfresh untuk menampilkan output kueri.
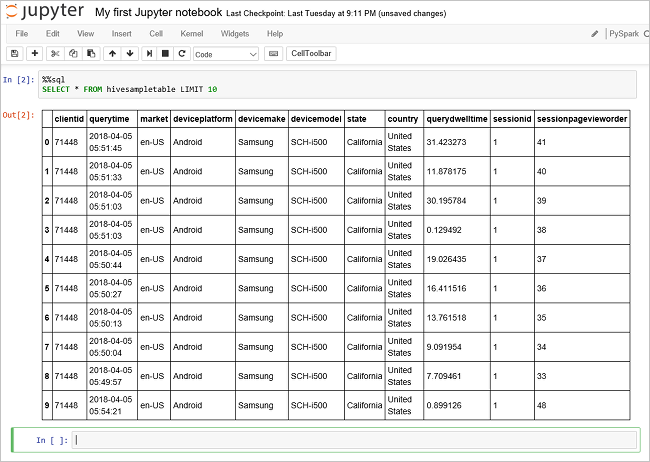 Wawasan" border="true":::
Wawasan" border="true":::Dari menu File pada buku catatan, pilih Tutup dan Hentikan. Mematikan buku catatan akan merilis sumber daya kluster.
Membersihkan sumber daya
HDInsight menyimpan data Anda di Azure Storage atau Azure Data Lake Storage, sehingga Anda dapat menghapus kluster dengan aman saat tidak digunakan. Anda juga dikenakan biaya untuk klaster HDInsight, bahkan saat tidak digunakan. Karena biaya untuk kluster berkali-kali lebih banyak daripada biaya untuk penyimpanan, masuk akal secara ekonomis untuk menghapus kluster saat tidak digunakan. Jika Anda berencana untuk segera mengerjakan tutorial yang tercantum diLangkah berikutnya, Anda mungkin ingin menyimpan kluster.
Beralih kembali ke portal Microsoft Azure, dan pilih Hapus.
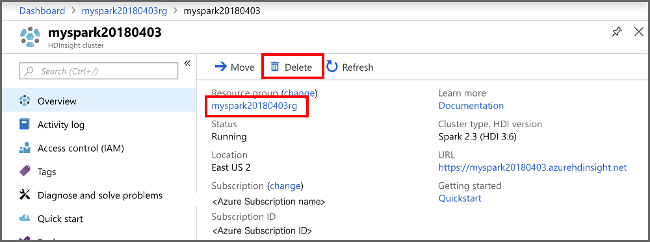 kluster pemandangan" border="true":::
kluster pemandangan" border="true":::
Anda juga dapat memilih nama grup sumber daya untuk membuka halaman grup sumber daya, lalu memilih Hapus grup sumber daya. Dengan menghapus grup sumber daya, Anda menghapus kluster HDInsight dan akun penyimpanan default.
Langkah berikutnya
Dalam panduan mulai cepat ini, Anda akan mempelajari cara membuat kluster Apache Spark di HDInsight dan menjalankan kueri Spark SQL dasar. Lanjutkan ke tutorial berikutnya untuk mempelajari cara menggunakan kluster HDInsight untuk menjalankan kueri interaktif pada data sampel.